In this tutorial, you will learn what is web scraping and how to perform web scraping.

Navigation
Show
What is Web Scraping
Web scraping is the process of using a bot to extract data from a website and export it into a digestible format. A web scraper extracts the HTML code from a web page, which is then parsed to extract valuable information.
In a nutshell, the meaning of web scraping is extracting data from a website.
What are Web Scrapers and how they Work
Web scrapers are bots that extract data from public websites. Web scrapers work by fetching a URL, parsing the HTML and storing the requested data in its desired format (e.g. CSV, JSON).
Web scraping bots are used to speed up data extraction from the web. If you want to scrape information from a specific web page, or even entire websites, scrapers can be use to extracting and selecting specific information from an HTML page in an automated matter.
Why Learn Web Scraping
Web scraping is a very valuable skills within organizations
Web scraping is can be used to:
- Build web crawlers
- Scraping data from the web to enhance their own product
- Extract data from an API
- Scrape competitor sites (e.g. compare prices, …)
- Build machine learning models
- Keep track of public reviews
- …
Large language models such as ChatGPT relied on web scraping to train their machine learning models. See datasets used for ChatGPT.
Ways to do Web Scraping
There are multiple ways to do web scraping. You can use a programming language to make HTTP requests, use a web browser with a plugin, use a browser application or work use a web crawler.
- Simple HTTP Requests using a Programming language like Python (e.g
requestslibrary) - Using a web browser (e.g.
Selenium,Puppeteeror chrome extension) - Using a web crawler (e.g. Scrapy or Screaming Frog)
Categories of Web Scrapers
There are 4 types of web scrapers:
- Pre-built and Self-built Scrapers (e.g. Python, NodeJS apps, Scrapy)
- Scraping Extensions (e.g. Scraper Chrome Extension)
- Scraper Softwares and web crawlers (e.g. Screaming Frog)
- Cloud-based scrapers and web crawlers (e.g. JetOctopus, Deepcrawl)
Pre-built and Self-built web scrapers are scrapers created and executed through a programming language such as Python or JavaScript. They require knowledge in computer programming and are limited to the programmer’s skills.
Web scraping browser extensions are extensions added to a web browser that allow the user to scrape web pages as they navigate in real-time. Scraper extensions are the simplest web scraping tools. They are usually free and require little prior-knowledge of web scraping. An example of a web scraping browser extension is Scraper Chrome Extension.
Scraper softwares are softwares installed on your computer that provide a user-interface to scrape the web. Scraper softwares often named web crawlers as they provide recursive web scraping features. The scraper software use the computer IP address and are limited to the speed capacity of the computer they are on.
Cloud-based scrapers are softwares hosted on web servers that provide an interface and the server resources to scrape the web. The cloud-based scrapers use the server’s IP and server capacity to crawl the web. These features allow uninterrupted fast scraping and minimize the risk of personal IP addresses being blocked. See how to scrape and prevent your IP from being blocked.
Web Crawlers VS Web Scrapers
If you don’t know whether you should use a web scraper or a web crawler, ask yourself this question: “do I need to discover and extract many pages from a website?”. For smaller projects, web scraping is very useful.
Web Crawlers
Web crawlers such as Screaming Frog are essentially web scrapers.
They are much more powerful than homemade web scrapers. While most web scrapers are built to scrape a list of pages that you give it, web crawlers a very complex structure that recursively “follows” links found on pages crawled. They also take care of most of the challenges that come up in web scraping. They are also much more expensive.
Building your own web crawler using web scraping technique can become very complex, very fast.
Web Scrapers
Building your own web scraper, or using a browser based scraper, allows you to quickly fetch content of a web page on demand, without the hurdle of downloading, opening and running an application like a web crawler. For example, a chrome extension may be better to scrape any pages while you browse.
Self-built web scrapers allow you to scrape content and reuse it within your code infrastructure in a way that an external web crawler can’t.
Is Web Scraping Legal?
In the United-States, the US Supreme Court ruled out that web scraping is legal as long as you scrape data publicly available on the internet. There is however some kind of data that is protected by international regulations (e.g. personal data, intellectual property, etc.). In is important to note that there are cases and regions where scraping may not be legal. For instance, a report by The Dutch Data Protection Authority mentions that web scraping is in violation of GDPR in the case of scraping social media posts or profiles.
What is the Best Programming Language for Web Scraping?
Python is the most commonly used programming language for web scraping.
Python has a various libraries and framework that allow to make HTTP request, parse data, set-up proxies, multi-threading requests and store and process the scraped data.
Useful Web Scraping Libraries and Tools
Here are 9 libraries and tools useful in web scraping:
- Requests library
- BeautifulSoup,
- Selenium,
- Scrapy,
- Puppeteer,
- Playwright,
- URLlib3,
- lxml,
- threading

Thanks to a wide variety of tools, Python allows performing all the necessary tasks: whether it is parsing dynamic data, setting up a proxy, or working with a simple HTTP request.
Other very popular programming language in Web Scraping are PHP and JavaScript as they allow to perform web scraping server-side and instantly use the resulting data into another website. NodeJS is often used in web scraping.
Good Websites to Use to Practice Web Scraping
My favourite website to practice web scraping is crawler-test.com. Here is an extended list of websites that you can use for web scraping:
- scrapethissite.com
- the-internet.herokuapp.com
- phptravels.com/demo
- s1.demo.opensourcecms.com/wordpress
- books.toscrape.com
- quotes.toscrape.com
- crawler-test.com
- realpython.github.io/fake-jobs
How to Do Web Scraping
To scrape and parse a website, follow these steps:
- Find the URL of a page that you want to scrape
Make sure that you are allowed to scrape the content of a page by reading its robot.txt file and/or the website’s privacy policy.
- Extract content from a web page using HTTP requests or a browser
Using a browser, a browser-based application or HTTP requests, get the HTML of a web page by either copying it from the source or by extracting it from the response.
- Use an HTML parser to format the content in a usable way.
Use a library such as BeautifulSoup to parse the HTML so that you can extract information from it.
- Inspect the HTML of the page.
Review the structure of the HTML of the web page to understand where the data that you want is located. You may use inspect in your browser to view the DOM for this step.
- Locate elements that you want to extract.
Use HTML tags, CSS Selectors and/or XPath to locate elements that you want to extract from the web page.
- Extract and store data in your preferred format
Store the data that you are extracting in a file or database as you go along so that you don’t loose the acquired data.
How Web Scraping Works
Web scraping works by extracting the content of a web page using HTTP requests and then parse the resource (e.g. HTML, json, etc.) in order to extract valuable information
- Request the content of a webpage (
requests) - Download the HTML
- Parse the HTML (
BeautifulSoup) - Extract the elements from the parsed content
Difference Between Requests, Scrapy and BeautifulSoup
- Requests is a library to perform HTTP requests on a per URL basis
- Scrapy is a web crawler that uses HTTP requests, while extracting new URLs to crawl
- BeautifulSoup is a parsing library
What are HTTP Requests
An HTTP request is a way for web clients (e.g. web browsers) to communicate with web servers over the internet.
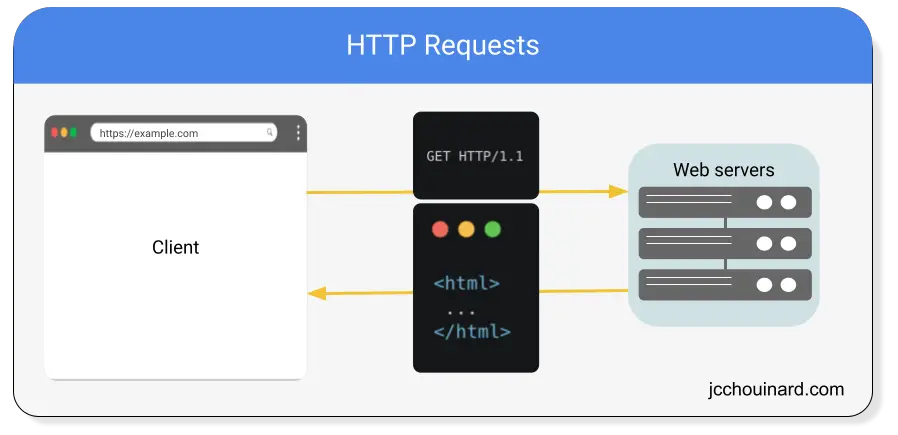
When a client sends an HTTP request to a server, it is asking for some kind of resource (such as a webpage, an image, or a file).
The server then sends a response that contains the requested resource. If the resource is not available, it will send an error message.
How to Use HTTP Requests in Web Scraping
HTTP requests can be used in web scraping by sending GET, POST or HEAD requests to the server for example. HTTP requests are more efficient than browser-based framework when scraping the web.
How to Do Web Scraping?
In order to get started with web scraping, you will need to understand the basics of HTML, CSS, JavaScript, Xpath and CSS Locators.
Here we will learn many ways that you can start doing web scraping:
- Web Scraping with a Chrome Extension
- Web Scraping with a Web Crawler
- Web Scraping with Wget
- Web Scraping with Python
Web Scraping with a Chrome Extension
The first, and the easiest way to do web scraping is to download the Scraper Chrome extension.
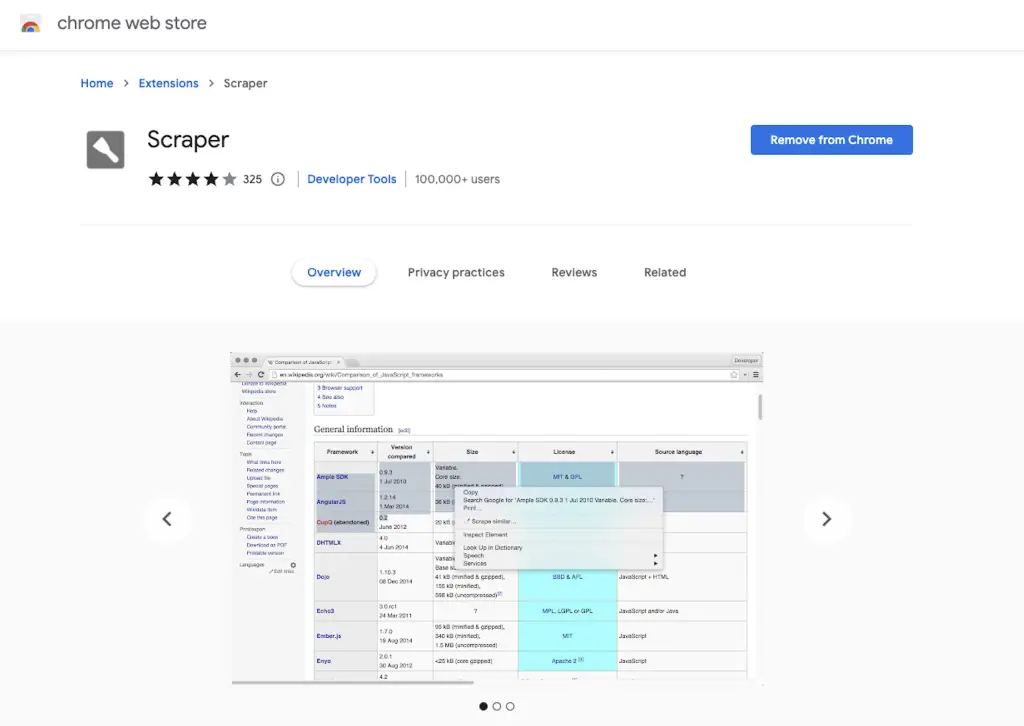
This extension allows a simple “scrape similar” feature when you right click on any element of any web page.
Doing this opens a new screen where the XPath of the element that you selected and gave you some options to export to Google Docs or copy to your clipboard.
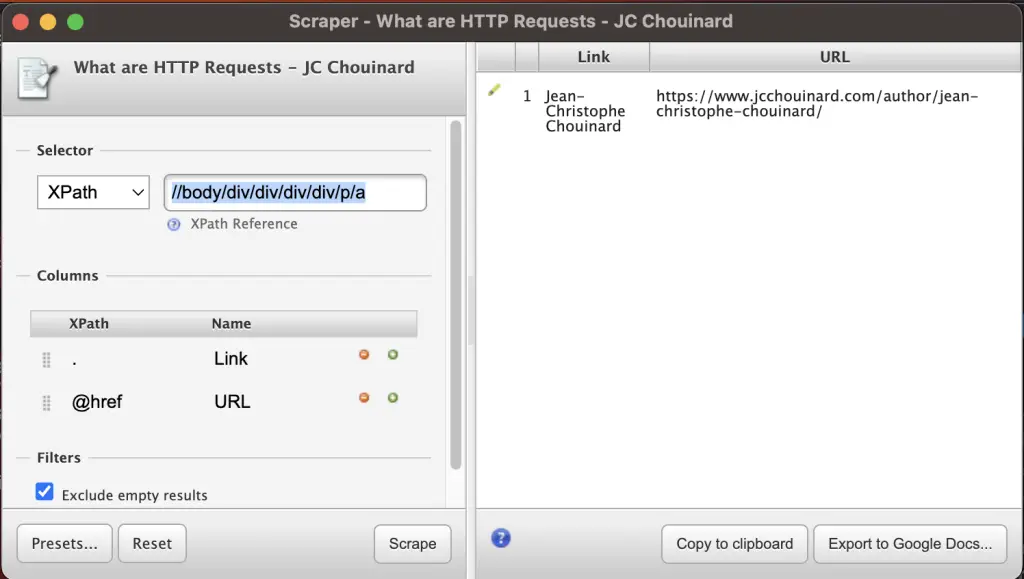
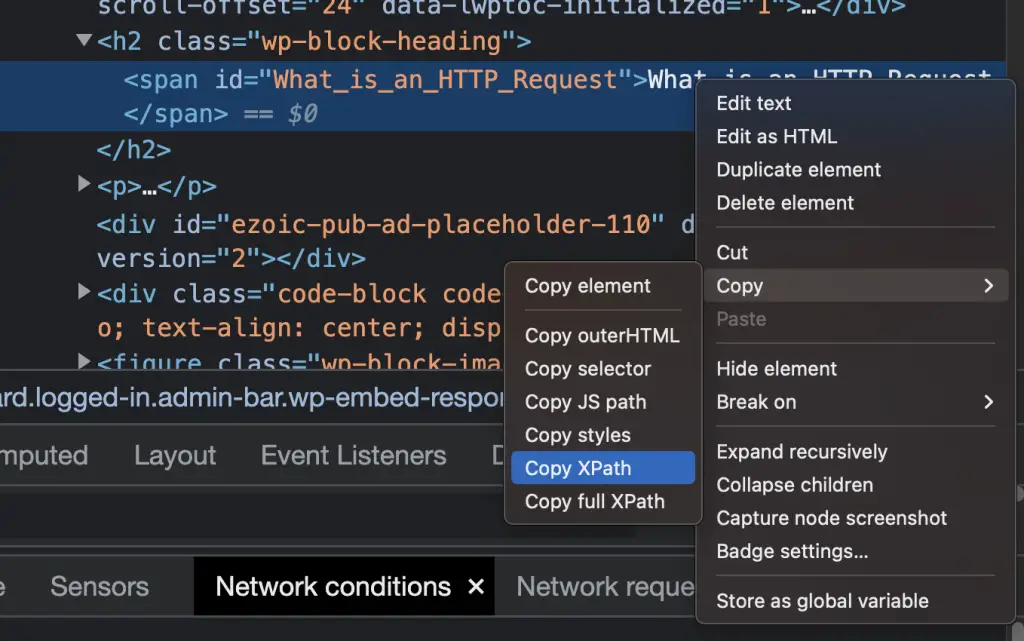
You can also add custom Xpath, and if you don’t know at all what Xpath is or how it works, Chrome Devtools as a very cool feature.
You can inspect and right click on any element in the DOM and select Copy > Copy XPath.
Web Scraping with a Web Crawler
To perform web scraping with a web crawler you need to either install a local software (e.g. Screaming Frog) or use a cloud-based web crawler (e.g. Jet Octopus).
There are multiple web crawlers available out there. I have tried a lot of them.
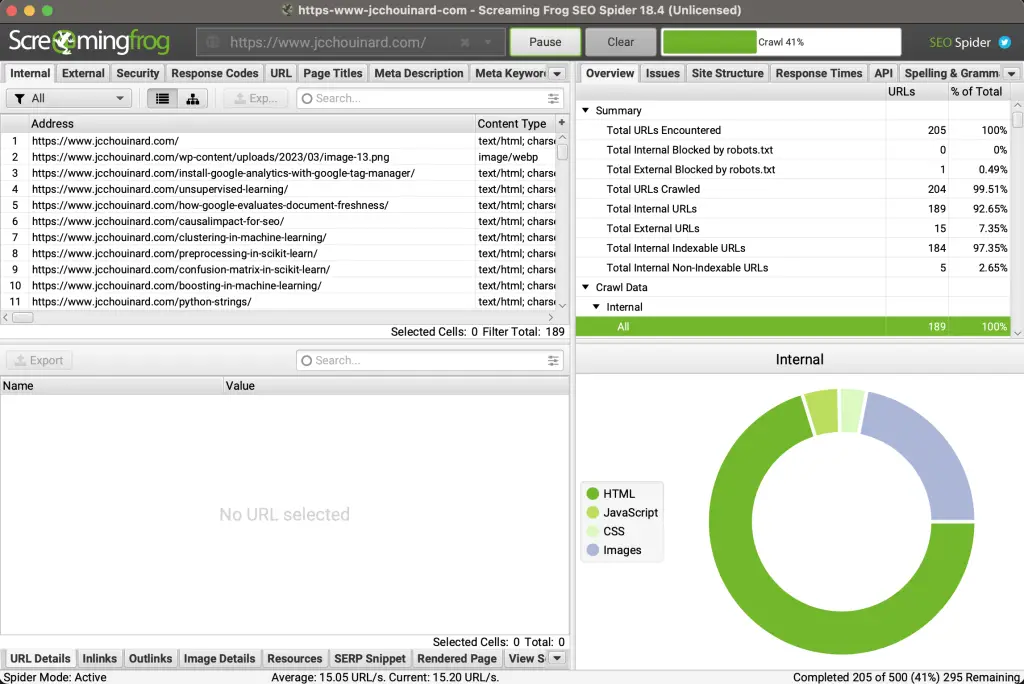
My all-time favourite web crawler is Screaming Frog, which is downloaded as a local application.
It is the best value to feature that I have seen so far. There is a free version that allows you to crawl up to 500 URLs.
All you have to do is add your URL and start the web crawler.
It will run, discover all your pages by crawling URLs and will report on various SEO metrics that you can use to improve your website.
There are options in Screaming Frog to personalize what you scrape using XPath or Regular Expressions. Check out this tutorial by Lazarina Stoy to learn how to scrape a website with Screaming Frog.
If you are searching for a cloud based web crawler instead, the best value for your buck is definitely JetOctopus.
Web Scraping with Wget
To scrape a web page or website with Wget, install the library and use the wgetc command in the Terminal.
Wget is free command-line tool created by the GNU Project that is used to download files from the internet.
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
$ brew install wget
$ wget https://www.jcchouinard.com/robots.txt
Web Scraping with Python Requests
To perform web scraping in Python, use an HTTP request library (e.g. requests) along with a parser library (e.g. BeautifulSoup) or use a browser-based library (e.g. Selenium).
I have a video tutorial to teach you how to do web scraping with the Python requests library (an alternative is the requests-HTML library).
Essentially all you need is to:
Install the requests library
$ pip install requests
Run this code to fetch a web page.
# import the request library
import requests
# Define your URL
url = 'https://crawler-test.com/'
# Fetch the page
response = requests.get(url)
# Show the Response
response.text
The output is the HTML of the web page in unicode (text) format.
You will need to parse the HTML using something like BeautifulSoup.
Web Scraping with BeautifulSoup
In the above, we have seen how to use the requests library to fetch a web page and show the textual representation of the HTML.
Now, I will show you how to parse the HTML of the page using BeautifulSoup.
First, Install the BeautifulSoup library.
$ pip3 install beautifulsoup4
Then all you need to do is to import bs4, parse the page with it and use the BeautifulSoup methods to get various HTML tags from the page.
# Fetch the HTML
import requests
url = 'https://crawler-test.com/'
response = requests.get(url)
# Import BeautifulSoup
from bs4 import BeautifulSoup
# Parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Extract any HTML tag
soup.find('title')
To learn more read the article on web scraping with BeautifulSoup.
Web Scraping with Selenium
Whenever you need the page to be rendered in order to get some element, you can use a browser application such as Selenium to perform Web Scraping.
Selenium opens a browser and loads a web page, just like you would do when you browse the web. Thus, they render the page so that you can scrape anything on it. Selenium is incredible to automate any browser activities. Alternatives to Selenium are Playwright and Puppeteer.
To use Selenium in Web Scraping, you need to install:
$ pip3 install webdriver-manager Selenium
And then run this code to show the H1 of the page for example.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# Install Webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# Fetch page
driver.get('https://crawler-test.com/')
try:
# Get the span element
elem = driver.find_element(By.TAG_NAME, 'h1')
# Show scraped content
print(elem.text)
except Exception as e:
print('There was an error', e)
# Quit browser when done
driver.quit()
If you want to learn more, you can read my article on how to use selenium with Python.
Web Scraping with Scrapy
You can perform web scraping by creating your own custom web crawler in Python using Scrapy.
$ pip3 install scrapy pyOpenSSL lxml
A quick overview to show what you can do with Scrapy is by opening the Terminal and then run the scrapy shell command
$ scrapy shell
And try these few commands:
fetch('https://crawler-test.com/')
view(response)
response.status
print(response.text)
response.xpath('//title/text()').get()
You can also use the Scrapy Selector object with requests to scrape a web page.
from scrapy import Selector
import requests
url = 'https://crawler-test.com/'
response = requests.get(url)
html = response.content
sel = Selector(text = html)
sel.xpath('//a/@href').extract()
To learn more about how to use Scrapy, read my tutorial Web Scraping with Scrapy.
Main Ways to Extract Data From an HTML
There are three main ways to extract data from HTML.
- Scraping HTML tags
- Scraping using XPath
- Scraping using CSS Locators
Challenges of Web Scraping
Web scraping can be challenging.
Most websites work very hard to prevent web scraping. They use techniques like:
- blocking bots,
- using CDNs that block bots,
- introducing limits to the number of pages per seconds,
- using CAPTCHAs,
- blocking logins when using web browser automation applications
- fully blocking your IP address
Scrape a Website without Getting Blocked
There are three main ways that you can prevent your website from getting blocked.
1. Slow down your crawling (crawl delays)
2. Use proxy servers
3. Rotate IP addresses
If you introduce crawl delays to slow down you crawling of the website, you may not get blocked.
The only way to be sure not to get blocked however is to use proxies and rotate the IP addresses that you use.
Web Scraping Proxies
You can use scrapy proxies to use random proxies from a list of free proxies that you can find in the Internet. You can find free proxies from sites like proxyscrape (may already be blocked).
If you start to scale however, you will need a premium proxy service.
- Apify WebScraper (15$/GB)
- Oxylabs (15$/GB, Pay as You Go)
- Bright Data (15$/GB, Pay as You Go)
- SmartProxy (12.5$/GB, Pay as You Go)
- ScrapingBee (49$/month, monthly credits)
- Scraping Dog (30$/Month, monthly credits)
If you don’t know which to choose, I have a guide on how to choose the best proxy service.
Web Scraping Tools
The three best web scraping tools are the Python programming language, Octoparse and the common crawl.
Python has many libraries to be used in web scraping, such as Scrapy, Selenium, Requests and BeautifulSoup.
Octoparse offers built-in models for web scraping the biggest and most known websites on the internet, making web scraping so much easier.
The common crawl has already crawled the entire Internet, and make all that data open source. You may not need to scrape anything yourself.
Responsible Web Scraping
Scraping a website introduces a load on the host web servers, which will cost them money and can slow down their website. Scraping also have a cost on the environment as you browse the web at a faster scale than any user’s would.
There are many ways that you can scrape data from the web responsibly.
Gather Data That Already Exists
Many websites are already crawled very often and the data is already available so that you don’t have to scrape it yourself.
For example, the common crawl project have crawled most of the websites on the Internet and have made available their database to the public.
Example of already available datasets that can help you save a ton of time.
Use Available APIs
A lot of the websites that you may want to crawl have APIs available to give you access to their data,
These APIs are in a simple data format that reduces massively to load on the host’s servers while giving you access to a load of the underlying data that is used to build content on their sites. Scraping those APIs removes all the challenges of web scraping and reduce the cost on the host.
Don’t know how to use APIs? I have you covered. I probably have written the biggest library of API tutorials with Python available on the web.
- Wikipedia API
- Wikidata API
- Reddit API
- Facebook API
- Twitter API
- WordPress API
- Teleport API
- Flickr API
- Google Search Console API
- Google Analytics API
- Google Ads API with R
- Google My Business API
- Google Pagespeed API
- Google Indexing API
- Google URL Inspection API
- Gmail API
Respect Robots.txt
If you don’t respect robots.txt, you exposing yourself to a lawsuit.
Make sure that before every crawl, you fetch the robots.txt to see if you are allowed to fetch the page.
Why Use Web Scraping in Data Science
Web scraping is an essential technique used to gather data for data science. Web Scraping helps data scientists gather data to be used to draw insights from and to train their Machine learning models. It provides a way to automate data gathering from the Internet. It is the basis of how Large Language Models were all built.
How to Use Web Scraping for Machine Learning
To use web scraping for machine learning, either start with a set of features that you would need to train your model on and find which websites provide this data in a structured matter, either through their websites or via APIs. Then, spend time understanding how to parse the data that you need from the data source. Finally, create an automated bot with Python (or any other web scraping tool) to extract the required data.
Web Scraping Projects
If you are looking for ideas of web scraping projects, you can start by scraping one of the websites that were built for web scraping, and then move to scraping Google with Apify, Scrape LinkedIn jobs, or scrape Amazon products.
Conclusion
We have now covered everything that you need to know in web scraping.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.