In this tutorial, you will learn what CSS Locators are and how to leverage CSS Selectors in web scraping.
CSS Selectors allow you to locate exact elements within an HTML document. It is also supported by most web scraping tools, making it a super useful tool for web scraping.
What is a CSS Selector
CSS Selectors use the Cascading Style Sheets rules to locate elements in an HTML document.
For example, in CSS, you could use this rule to apply a color to all links on a page that have a class named “myclass”.
a.myclass {
color: blue;
}
Similarly, in Web scraping, you can use the same CSS selector to display all the links with the same class:
a.myclass
Why CSS Selectors are Useful in Web Scraping
CSS Selectors are very useful in web scraping. CSS Selectors allow you to:
- locate the element you want to extract from a webpage,
- identify and extract data from HTML documents quickly.
- automate the scraping of webpages.
Simplest Way to Find CSS Selectors in Chrome
Chrome DevTools as an incredible feature that allows you to find the CSS selectors of any DOM element without any prior knowledge.
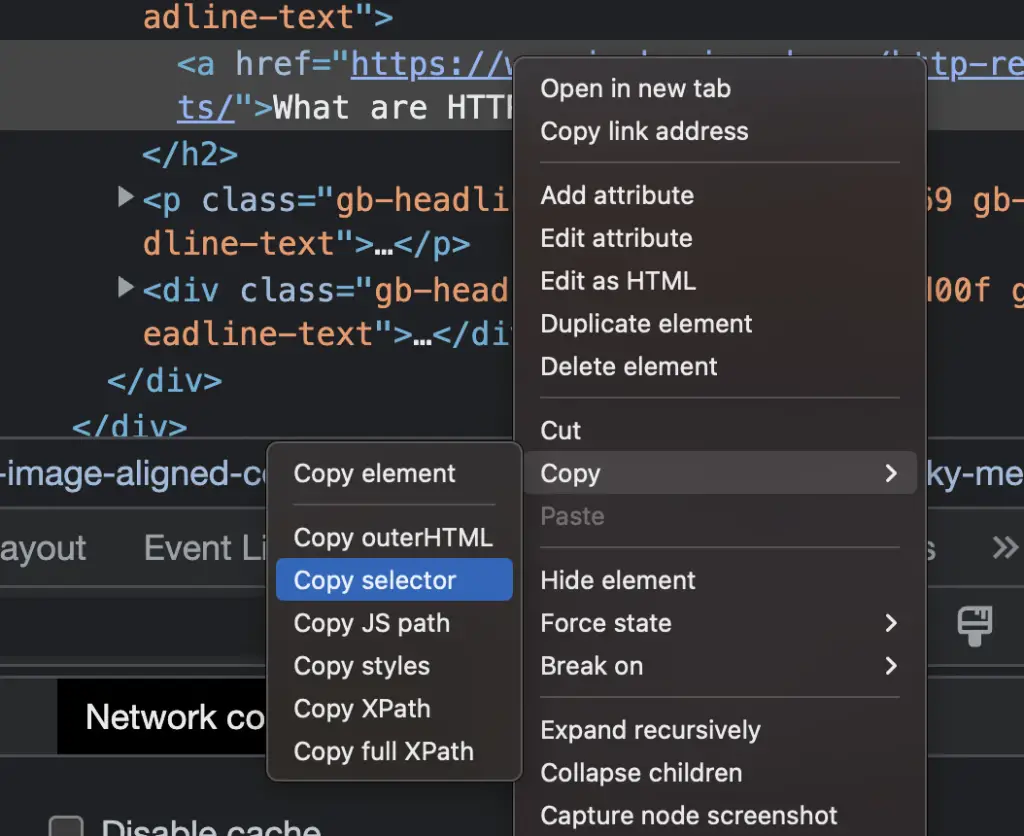
Open Chrome DevTool with Command + Shift + I, or by using right-click > inspect.
Then right click on any element in the DOM and select Copy > Copy Selector.
Basics of CSS Selectors
CSS selectors are patterns used to describe the location of element(s) within an HTML document.
They consist of one or more elements separated by a white space.
The last element on the right of the selector expression is the element that you want to select
For example, the CSS Selector below locates the h1, found within the HTML body element:
html > body > h1
Basic Structure of the CSS Selectors
The basic structure of an CSS Selectors is similar to the structure used in XPath, or the structure to navigate a URL where the > symbol replaces the slash symbol (/).
xpath: /html/body/p
CSS selector: html > body > p
The CSS locator is represented by a series of steps. Each step is separated by the greater-than (>) symbol, which moves forward one generation.
Types of CSS Selectors (Filters)
There are several types of CSS selectors that can be used to target HTML elements on a web page.
- Tag Selector
- Class Selector
- ID Selector
- Attribute Selector
- Descendant Selector
- Child Selector
- Pseudo-Class Selector
Basic CSS Selectors Cheatsheet
| Selector | Description | Example | Explanation |
|---|---|---|---|
| Tag Selector | Selects elements based on their tag name. | p | Selects all <p> elements. |
| Class Selector | Selects elements based on their class name. | .example | Selects all elements with the class name “example”. |
| ID Selector | Selects an element based on its ID. | #example | Selects the element with the ID “example”. |
| Attribute Selector | Selects elements based on their attribute and value. | [type="text"] | Selects all elements with the attribute “type” and value “text”. |
| Descendant Selector | Selects elements that are descendants of another element. | div p | Selects all <p> elements that are descendants of a <div> element. |
| Child Selector | Selects elements that are direct children of another element. | ul > li | Selects all <li> elements that are direct children of a <ul> element. |
| Pseudo-Class Selector | Selects elements based on their state or position in the document. | a:hover | Selects all <a> elements when the mouse is hovering over them. |
Tag Selector
Tag selectors can be used to target specific HTML elements.
For example, you could use the title, h1, p or a tag selectors in order to select each element.
<html>
<head>
<title>Title of your web page</title>
</head>
<body>
<h1>Heading of the page</h1>
<p id="first-paragraph" class="paragraph">Paragraph of text</p>
<p class="paragraph">Paragraph of text 2</p>
<div><p class="paragraph">Nested paragraph</p></div>
<a href="/a-link">hyperlink</a>
</body>
</html>
To select the h1, here is the selector that you would use.
h1<h1>Heading of the page</h1>
Class Selector
This example shows how to use the dot notation to select the elements with a certain class
This expression selects all the <p> HTML tags that have a class attribute with “paragraph” as its value.
p.paragraph
<p id="first-paragraph" class="paragraph">Paragraph of text</p>
<p class="paragraph">Paragraph of text 2</p>
<p class="paragraph">Nested paragraph</p>
ID Selector
An ID Selector uses the hashtag to target an element with its unique id.
p#first-paragraph<p id="first-paragraph" class="paragraph">Paragraph of text</p>
Attribute Selector
An attribute Selector selects elements based on their attribute and value.
It uses the syntax:
tag-name[attribute="attribute-value"]
Example:
a[href="/a-link"]
<a href="/a-link">hyperlink</a>
Descendant Selector
The descendant selector selects all descendants elements of another element.
This is done using the parent and the descendant tags with a space instead of a >.
body p
<p id="first-paragraph" class="paragraph">Paragraph of text</p>
<p class="paragraph">Paragraph of text 2</p>
<p class="paragraph">Nested paragraph</p>
Child Selector
The child selector selects elements that are direct children of another element.
body > p
The difference here is the any element that are not direct, e.g. nested elements like the p inside the div will not be selected.
<p id="first-paragraph" class="paragraph">Paragraph of text</p>
<p class="paragraph">Paragraph of text 2</p>
Pseudo-Class Selector
The pseudo-class selector uses the colon : to select elements based on their state or position in the document.
For example, you can define which sibling that you want to locate using the :nth-of-type(N).
The CSS expression below shows how to select the first div of the body element.
html > body > div:nth-of-type(1)
Unlike Python that uses zero-based indexing, the index in CSS Selectors starts at 1.

There are many pseudo-class selectors, some of which are described in this table.
| Pseudo-class Selector | Description |
|---|---|
| :hover | Selects an element when the mouse pointer hovers over it |
| :active | Selects an element when it is being activated (e.g. clicked on) |
| :visited | Selects a link that has been visited by the user |
| :focus | Selects an element when it has focus (e.g. when a form field is selected) |
| :first-child | Selects the first child element of its parent element |
| :last-child | Selects the last child element of its parent element |
| :nth-child(n) | Selects the nth child element of its parent element (where n is a number) |
| :nth-of-type(n) | Selects the nth element of its type (where n is a number) |
| :last-of-type | Selects the last occurrence of an element within its container (e.g. h2:last-of-type) |
Using CSS Selectors with Python
You can use CSS selectors when Web Scraping with BeautifulSoup or when Web Scraping with Scrapy.
Scraping CSS Selectors with BeautifulSoup
BeautifulSoup is not really allowing CSS selectors. To extract using CSS tag, you would need to do something like:
from bs4 import BeautifulSoup
import requests
# Fetch the HTML
url = 'https://crawler-test.com/'
response = requests.get(url)
# Parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Define CSS
soup.find_all("div", {"class":"panel-header"})
Scraping CSS Selectors with Scrapy
Scrapy allows you to scrape content using CSS selectors with the css() method from the Selector class.
from scrapy import Selector
html = '''<html>
<head>
<title>Title of your web page</title>
</head>
<body>
<h1>Heading of the page</h1>
<p id="first-paragraph" class="paragraph">Paragraph of text</p>
<p class="paragraph">Paragraph of text 2</p>
<div><p class="paragraph">Nested paragraph</p></div>
<a href="/a-link">hyperlink</a>
</body>
</html>'''
# Instantiate Selector
sel = Selector(text=html)
# define Selector class
css_selector = 'body > p#first-paragraph'
sel.css(css_selector).extract()
['<p id="first-paragraph" class="paragraph">Paragraph of text</p>']
Using CSS Selectors with JavaScript
Whatever way you are executing JavaScript (e.g. Chrome DevTools Console, NodeJS, etc.), you can use JavaScript the querySelector or querySelectorAll commands to locate HTML elements with their CSS selectors.
Here is an example using querySelectorAll to find all the links on a page.
var links = document.querySelectorAll('a');
var anchorText = [];
links.forEach(link => {
anchorText.push(link.textContent);
});
console.log(anchorText);
XPath to CSS Selector Conversion
| Equivalency | XPath Notation | CSS Selector |
|---|---|---|
| Select by element type | //div | div |
| Select by class name | //div[@class=”example”] | div.example |
| Select by ID | //*[@id=”example”] | #example |
| Select by attribute | //input[@name=”example”] | input[name=”example”] |
| Select by attribute value containing | //input[contains(@class, “example”)] | input[class*=”example”] |
| Select by attribute value starting with | //input[starts-with(@id, “example”)] | input[id^=”example”] |
| Select by attribute value ending with | //a[ends-with(@href, “example”)] | a[href$=”example”] |
| Select by sibling | //div/following-sibling::p | div + p |
| Select by descendant | //div//p | div p |
| Select by first child | //div/p[1] | div > p:first-child |
| Select by last child | //div/p[last()] | div > p:last-child |
Difference Between Xpath and CSS Selectors
The difference between XPath and CSS selectors is that with the XPath we can move forward and backward while a CSS selector can only move forward while XPath can be a bit more complex.
Articles Related to Web Scraping

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.