
LinkedIn has a ton of data to offer. However, to have this data, you must either extract it manually or scrape it.
Doing manually is good, but it is prone to error, tedious, and not scalable. In this tutorial, we will be using Python and scraping LinkedIn jobs using it.
Further, in this tutorial, I will explain how you can scale this method, bypassing the limitations of scraping LinkedIn jobs using Python. And later, we will store this data for analysis purposes in a CSV file.
For this tutorial, we will use LinkedIn Job Scraping API which will help us scrape job data from LinkedIn without getting blocked.
Install Python and Download Libraries
We will use Python 3.x for this tutorial. You can install Python or use Google Colab. See how to install Python. After this create a folder in which you will keep the Python scripts. I am naming this folder as jobs. In Terminal Type:
$ mkdir jobsThen download the following libraries.
- requests: This will be used for creating an HTTP connection with the LinkedIn Jobs Scraping API.
- Pandas: This will be used to convert JSON data into a CSV file.
Finally, you have to sign up for the free pack of Scrapingdog. With the free pack, you get 1000 credits which is enough for testing purposes. This tutorial, will take less than 40 credits.
Understanding Requests to LinkedIn API
Before we start scraping the jobs let’s look at the documentation first. We can see that there are four required parameters that needs to be passed while making the GET request.
How to Scrape LinkedIn Jobs with Python
To scrape Linkedin jobs with Python, you will need an proxy service API key, a Linkedin geoid and a job query to fill the LinkedIn search bar.
For this tutorial, we we are going to scrape jobs offered by Google in the USA, using the Scraping Dog proxy service.
How to Find LinkedIn Jobs Geo ID
To find the GeoId inside LinkedIn jobs, open the LinkedIn jobs search page and check the geoid parameter inside the URL.

As you can see the geoId of the USA is 103644278. The geoid for Canada is 101174742.
Scraping Your First LinkedIn Jobs Page
To scrape your first LinkedIn jobs page, define the API endpoint and create a parameter dictionary that contains the API key, the job search term, the LinkedIn geoid and the page number from the paginated results. Then, use Python requests to fetch the Scraping Dogs API.
import requests
# Define Scraping Dog API Key
api_key = 'you-API-key'
# Define the URL and parameters
url = "https://api.scrapingdog.com/linkedinjobs/"
geo_id = '101174742' #Canada. US: "103644278"
params = {
"api_key": api_key,
"field": "Google",
"geoid": geo_id,
"page": "1"
}
# Send a GET request with the parameters
response = requests.get(url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Access the response content
google_jobs = response.json()
print(google_jobs)
else:
print("Request failed with status code:", response.status_code)
This code will return all the jobs offered by Google in the USA. Once you run this code you will find this response on your console.
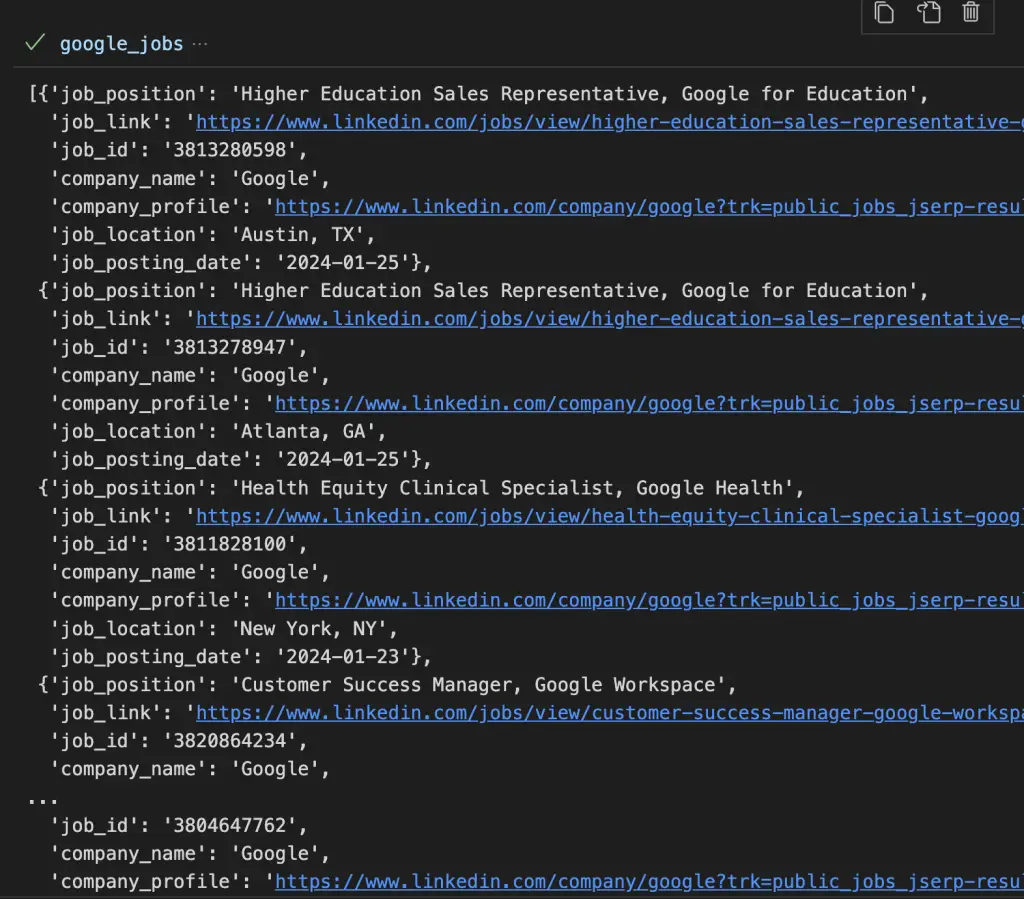
The API response contains the following fields:
- job_position,
- job_link,
- job_id,
- company_name,
- company_profile,
- job_location
- job_posting_date.
Fetching a Specific Job Title on LinkedId
It is not necessary to pass the company name all the time. You can even pass the job title as the value of the field parameter.
import requests
api_key = 'you-API-key'
url = "https://api.scrapingdog.com/linkedinjobs/"
geo_id = '101174742'
params = {
"api_key": api_key,
"field": "Product Manager", # job title here
"geoid": geo_id,
"page": "1"
}
# Send a GET request with the parameters
response = requests.get(url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Access the response content
pm_jobs = response.json()
print(pm_jobs)
else:
print("Request failed with status code:", response.status_code)
For every page number, you will get a maximum of 25 jobs. Now, the question is how to scale this solution to collect all the jobs from the API.
How to Extract LinkedIn Jobs at Scale
To extract all the jobs on Linkedin at scale for a specific geoId and search term, we will run an infinite while loop. In this example, we will extract all the jobs for jobs at Google in the USA found on Linkedin jobs by following these steps:
- Create a function to store the LinkedIn data
- Create an infinite while loop to Scrape Each Search Page
- Extract and store the LinkedIn data
1. Create a function to Store the LinkedIn Data
The first step is to create a function that will store the data. Thus, if something breaks, you will still have data stored for each loop.
This will create a Pandas DataFrame from the data we return. If a file already exists, it will read it, and append the data to the existing file. If not, it will create a new one.
import pandas as pd
import requests
import sys
def process_json_data(data, csv_filename="linkedin_jobs.csv"):
# Convert the list of dictionaries to a Pandas DataFrame
df = pd.DataFrame(data)
try:
# Try to read an existing CSV file
existing_df = pd.read_csv(csv_filename)
# Append the new data to the existing DataFrame
updated_df = pd.concat([existing_df, df], ignore_index=True)
# Save the updated DataFrame back to the CSV file
updated_df.to_csv(csv_filename, index=False)
print(f"Data appended to {csv_filename}")
except FileNotFoundError:
# If the CSV file does not exist, create a new one
df.to_csv(csv_filename, index=False)
print(f"Data saved to a new CSV file: {csv_filename}")
return df
2. Create an Infinite While Loop to Scrape Each Search Page
Now, we will create an infinite while loop to scrape each search page. This while loop will run until the length of the data array comes to zero. Because we dont want to spend all your API credits for this tutorial, I will add the sys.exit() line to the end, stopping after the first loop. Remove that line to scrape all of LinkedIn Jobs.
import sys
while True:
# We will add Python code here
# Stop after first loop,
sys.exit() # remove to fetch everything
3. Extract and Store the LinkedIn Data
To extract and store the LinkedIn data, add the API request and a Python storing function inside the while loop.
import pandas as pd
import requests
import sys
# Example usage inside your loop
page = 0
full_list = []
while True:
l = []
page += 1
url = "https://api.scrapingdog.com/linkedinjobs/"
params = {
"api_key": api_key,
"field": "SEO",
"geoid": geo_id,
"page": str(page)
}
print('Running page:', page)
# Send a GET request with the parameters
response = requests.get(url, params=params)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Access the response content
data = response.json()
for item in data:
l.append(item)
if len(data) == 0:
break
# Store data to CSV
df = process_json_data(l)
full_list.extend(l)
else:
print("Request failed with status code:", response.status_code)
if page == 2:
sys.exit() # Comment out to run the entire loop
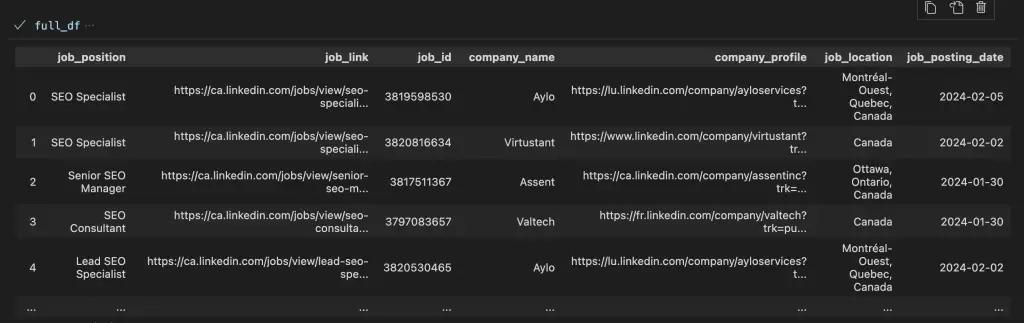
full_df = pd.DataFrame(full_list)
This code will keep running until the length of data is zero. break statement will stop the infinite while loop.
- At each iteration, it will fetch the API for a new page of 25 results, until all the page are scraped
- After each loop, it creates a Pandas DataFrame and store the data into a CSV file. This way, no progress is lost.
- There is a list (
l) for each loop, and a full list (full_list) to store all the data.
Benefits of Scraping LinkedIn Jobs
The benefits of scraping LinkedIn job listings are that it helps developers can create more efficient, targeted job boards that cater to the specific needs of various industries and job seekers. The collection of job data not only enhances the job search experience for individuals but also offers companies a more nuanced platform to find the right talent.
Scaling this operation through an API extends the utility of your initial scraping project, enabling you to handle larger volumes of data with greater efficiency.
This scalability is crucial to building a comprehensive job board that remains current with the ever-evolving job market on LinkedIn. An API-based approach allows for real-time updates and integration with other software tools, making your job board more dynamic and responsive to the needs of both job seekers and employers.
In this blog, we learned how you can scrape LinkedIn Jobs at scale using Python.
I hope you liked the tutorial, I will be writing more LinkedIn Tutorials shortly.
Happy Scraping!

Manthan Koolwal is a web scraping veteran for 8 years, crafted data pipelines for major companies. Founder of Scrapingdog, his SaaS venture, he pioneers simple solutions in the field.