In this tutorial, you will learn what web scraping is and how to scrape websites with Python.
Navigation
Show
For this tutorial, you will need to have Python installed.
What is Web Scraping
Web scraping is the process of using a bot to extract data from a website and export it into a digestible format. A web scraper extracts the HTML code from a web page, which is then parsed to extract valuable information.
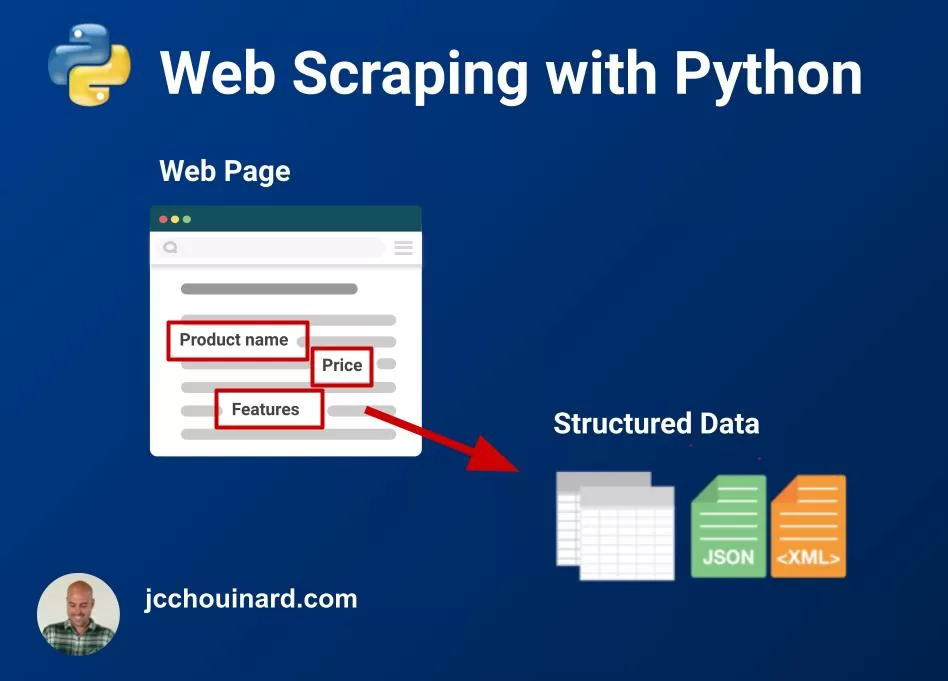
In a nutshell, the meaning of web scraping is extracting data from a website.
How Python can be Used for Web Scraping
Python is a popular programming language used in web scraping because it has multiple libraries available to handle HTTP requests, HTML parsing and browser-based frameworks to scrape rendered versions of web pages.
Tools and Libraries Available for Web Scraping
The most useful libraries and frameworks available in Python for web scraping are:
- Requests
- BeautifulSoup
- Scrapy
- Selenium
- Urllib3
- Lxml

How Web Scraping Works
Web scraping works by extracting the content of a web page using HTTP requests and then parse the resource (e.g. HTML, json, etc.) in order to extract valuable information
- Request the content of a webpage (
requests) - Download the HTML
- Parse the HTML (
BeautifulSoup) - Extract the elements from the parsed content
Install Python Web Scraping Libraries
Use pip to install the Python web scraping libraries: requests, beautifulsoup, urllib, and scrapy.
$ pip3 install requests urllib3 beautifulsoup4 scrapy lxml pyOpenSSL
Python Web Scraping Example
The simplest way to do web scraping in Python is to fetch a web page with Python requests and parse the HTML of the page with BeautifulSoup. The example below will show you how to do both before we dive into more detailed web scraping examples.
Extracting the HTML of a Webpage with Requests
The first step in web scraping is to extract the HTML of the page. This can be done through HTTP requests or browser-based applications. In this example, we use python requests to perform an HTTP request and get the HTML of a web page in the HTTP response.
# Making an HTTP Request
import requests
# Define URL to fetch
url = 'https://crawler-test.com/'
# Make the Request
r = requests.get(url)
# Print the outpout
print('Status code: ', r.status_code)
print('Type: \n', type(r.text))
print('Text: \n', r.text[:200])
Output:
Status code: 200
Type:
<class 'str'>
Text:
<!DOCTYPE html>
<html>
<head>
<title>Crawler Test Site</title>
<meta content="en" HTTP-EQUIV="content-language"/>
<link type="text/css" href="/css/app.css" rel="styleshe
Parsing the HTML with BeautifulSoup
The second step in web scraping is to extract information from a document. This is called parsing. In this example, we use python BeautifulSoup library to parse the HTML of the page return previously in the HTTP response.
# Parsing an HTML
from bs4 import BeautifulSoup
# Parse the HTML
soup = BeautifulSoup(r.text, 'html.parser')
# Show type of the soup object
print('Type: \n', type(soup))
# Show HTML title
soup.find('title')
Output:
Type:
<class 'bs4.BeautifulSoup'>
<title>Crawler Test Site</title>
Now that we know the basics of scraping a web page with Python, let’s look at the multiple techniques we can do to perform web scraping.
Understand HTML, CSS, JavaScript and Xpath
Before you can get started with Web Scraping in Python, you will need to have at least some basic understanding of what HTML, CSS, JavaScript and Xpath are.
With this understanding, you will be able to leverage the source code and the DOM to automate data extraction from a website.
HTML for Web Scraping
HTML stands for HyperText Markup Language is a markup language used for creating web pages.
When you use a browser to open a web page, its main purpose is to interpret HTML, CSS and JavaScript files and convert them into a usable website.
Below is how the browser will display the HTML, where the <title> tag is visible in the browser tab, and the <h1> is visible on the page.
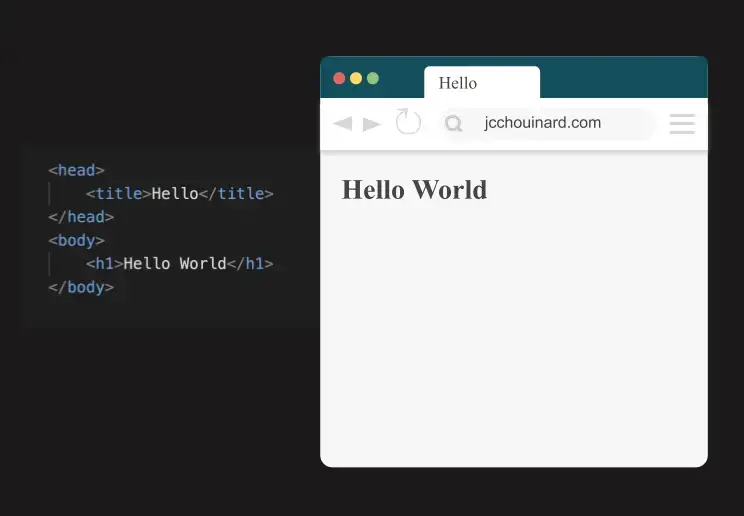
The HTML contains HTML tags (surrounded by <>) that provide the tree-like structure of the web page.
The HTML tags are in well-structured format that what we can use to extract the information from a webpage.
How to use HTML Tags in Web Scraping with Python
To use scrape data from a web page using the HTML tags in Python, use the .find('tag_name')
# Show HTML title
soup.find('title')
If you want to learn more about HTML, read the following article about the basics of html for web scraping.
CSS for Web Scraping
CSS, or Cascading Style Sheets, is used in web development to describe how elements are displayed on a screen.
For example, in CSS, you could use this rule to apply a color to all links on a page that have a class named “myclass”.
a.myclass {
color: blue;
}
CSS Selectors are another structured format that can be used in web scraping to locate and extract elements within an HTML document.
In Web scraping, you can use the CSS selectors that was used to change the style of the page in order to find any element of this selector.
How to use CSS Selectors in Web Scraping with Python
In Python, to extract data from an HTML document using its CSS selector, use the select() method of the BeautifulSoup library
soup.select('a.myclass')
You can also use the .css() method on the scrapy Selector object.
from scrapy import Selector
sel = Selector(text=html)
sel.css('p.hello').extract()
If you want to learn more about how to use CSS selectors in Web Scraping, read my article titled: “Basics of CSS Locators for Web Scraping“.
XPath for Web Scraping
Xpath is a query language that can be used to access different elements and attributes of an XML or an HTML document.
Xpath expressions are strings used to describe the location of an element (node), or multiple elements, within an HTML (or XML) document.
XPath allows you to locate exact elements within an HTML document. It is also supported by most web scraping tools, making it a super useful tool for web scraping. For example, the xpath below locates the h1, found within the HTML body element:
//html/body/h1
How to use XPath in Web Scraping with Python
To parse the HTML of a web page with XPath in Python, use the lxml Python library:
from lxml import html
# Parse HTML with XPath
content = html.fromstring(r.content)
panels = content.xpath('//*[@class="panel-header"]')
You can also use the .xpath() method on the scrapy Selector object.
from scrapy import Selector
sel = Selector(text=html)
sel.xpath('//p').extract()
If you want to learn more about how to use XPath in Web Scraping, read my article titled: “Basics of Xpath for Web Scraping“.
Ways to do Web Scraping in Python
There are multiple ways to do web scraping in Python. You can use a programming language to make HTTP requests, use a web browser with a plugin, use a browser application or work use a web crawler.
- Simple HTTP Requests (e.g
requestslibrary) - Using a web browser (e.g.
Selenium) - Using a web crawler (e.g. Scrapy)
Web Scraping with HTTP Requests in Python
You can use HTTP requests in Python to communicate with the server using the requests library in Python.
All you have to do is send an HTTP request for a given URL, and the web server will return a response with the content on the page.
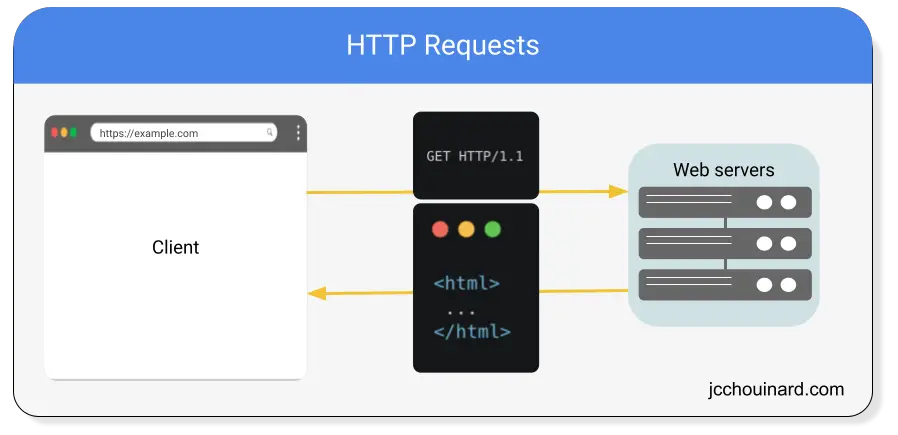
HTTP requests don’t allow you to view a rendered version of the page (once JavaScript is executed).
When some of the content is hidden behind JavaScript, you will want to use a browser application to scrape the website.
Web Scraping with a Browser in Python
It is possible to scrape a website by installing an application that loads your browser (just like you would do it when you open Chrome), and let you to interact with the website using Python.
This is incredibly useful when you need to load JavaScript on a page, add login information, or automate experimentations on your website.
There are many applications that can be used for browser-based web scraping and automation:
- Selenium
- Playwright
- Puppeteer
Web Scraping using Web Crawlers in Python
Web crawlers such as Screaming Frog are essentially web scrapers. They are much more powerful than homemade web scrapers. You can build your own web crawler in Python, but bear in mind that it can become very complex, very fast.
Using a solution like Scrapy makes building a web crawler in Python easier.
Python Web Scraping Libraries
Python has an extensive set of libraries that you can use in Web Scraping:
- Requests
- BeautifulSoup
- lxml
- Selenium
- Scrapy
- Requests-HTML
In most web scraping project you will only need a few of those libraries. Here are example web scraping library set-ups (from the simplest to the hardest to implement):
- Use Python
requestslibrary with a parser library such asBeautifulSouporlxml - Use
Requests-HTMLwith its built-in parsing methods - Use
Seleniumwith its built-in parsing methods - Use
Scrapywith its built-in parsing methods
Python Web Scraping with Requests
To perform web scraping in Python, use an HTTP request library (e.g. requests) along with a parser library (e.g. BeautifulSoup) or use a browser-based library (e.g. Selenium).
I have a video tutorial to teach you how to do web scraping with the Python requests library (an alternative is the requests-HTML library).
Essentially all you need is to:
Install python
Install the requests library
$ pip install requests
Run this code to fetch a web page.
# import the request library
import requests
# Define your URL
url = 'https://crawler-test.com/'
# Fetch the page
response = requests.get(url)
# Show the Response
response.text
The output is the HTML of the web page in unicode (text) format.
Python Web Scraping with BeautifulSoup
To parse the HTML of the page using BeautifulSoup in Python, install the library, fetch the HTML with an HTTP request library and parse the HTML using the BeautifulSoup() class on the HTML.
First, Install the BeautifulSoup library.
$ pip3 install beautifulsoup4
After, import bs4, parse the page with it and use the BeautifulSoup methods to get various HTML tags from the page.
# Fetch the HTML
import requests
url = 'https://crawler-test.com/'
response = requests.get(url)
# Import BeautifulSoup
from bs4 import BeautifulSoup
# Parse the HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Extract any HTML tag
soup.find('title')
To learn more read the article on web scraping with BeautifulSoup
Python Web Scraping with lxml
In Python, the lxml library is a parsing library that can be used to extract information from HTML or XML. The lxml library can be used as an alternative to the BeautifulSoup library.
To use the lxml library in Python, fetch the page with the requests library and parse the HTML with the html.fromstring() method.
Install the lxml library with pip.
$ pip install lxmlParse the textual representation of HTML with the fromstring() method.
import requests
from lxml import html
r = requests.get()
tree = html.fromstring(r.text)
The advantage of lxml over BeautifulSoup is that it is possible to use XPath expressions to extract data.
# Parse with XPath in lxml
html.xpath('//*[@class="panel-header"]')
Python Web Scraping with Requests-HTML
The requests-HTML library is an HTML parser that lets you use CSS Selectors and XPath expressions to extract the information that you want from a web page. It also offers the capacity to perform JavaScript Rendering.
To scrape a web page in Python with the requests-HTML library, first install the required Python libraries and then use the HTMLSession() class initialize the session object. Then, perform a GET request using the .get() method.
Install libraries
pip install requests requests-HTML urlparse4Scrape the website using HTMLSession() in Python.
# Scrape website with Requests-HTML
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://crawler-test.com/')
r.html.find('title')[0].text
You may get the following error if you are using a Jupyter Notebook, in that case use the AsyncHTMLSession.
RuntimeError: Cannot use HTMLSession within an existing event loop.
Python Web Scraping with Selenium
To use the Selenium web browser application to perform Web Scraping in Python, install the required library and the web driver, instantiate the webdriver module and use the get() method to open the web browser to the web page that you want to extract information from.
Selenium works by opening a browser and loads a web page, just like you would do when you browse the web. This way, it renders the page so that you can scrape anything on it. Selenium is incredible to automate any browser activities.
To use Selenium in Python Web Scraping, you need to install:
$ pip3 install webdriver-manager Selenium
And then run this code to show the H1 of the page for example.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# Install Webdriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# Fetch page
driver.get('https://crawler-test.com/')
try:
# Get the span element
elem = driver.find_element(By.TAG_NAME, 'h1')
# Show scraped content
print(elem.text)
except Exception as e:
print('There was an error', e)
# Quit browser when done
driver.quit()
If you want to learn more, you can read my article on how to use selenium with Python.
Python Web Scraping with Scrapy
To scrape web pages with Scrapy in Python, create your own custom web crawler in Python. You will need to install the required library and use either the scrapy shell or the Selector() object.
First, install the required Python libraries.
$ pip3 install scrapy pyOpenSSL lxml
A quick overview to show what you can do with Scrapy is by opening the Terminal and then run the scrapy shell command
$ scrapy shell
And try these few commands:
fetch('https://crawler-test.com/')
view(response)
response.status
print(response.text)
response.xpath('//title/text()').get()
You can also use the Scrapy Selector object with requests to scrape a web page.
from scrapy import Selector
import requests
url = 'https://crawler-test.com/'
response = requests.get(url)
html = response.content
sel = Selector(text = html)
sel.xpath('//a/@href').extract()
To learn more about how to use Scrapy, read my tutorial Web Scraping with Scrapy.
Use Proxies in Web Scraping with Python
Web scraping with Python is very fast and puts a load on the hosts’s servers. Thus, companies are trying to block web scraping and bots as much as possible to reduce the costs and avoid slowing down their user experience.
In some cases they will add captchas, in other cases they will block the user agents or even block an IP entirely. Thus, it is important if you scale web scraping to use rotating IPs and proxies.
To use proxies in Python, you need to find either free proxies from sites like proxyscrape which a lot of them may already be blocked, or purchase a premium service which will provide you with the IPs that you need:
- Apify WebScraper (15$/GB)
- Oxylabs (15$/GB, Pay as You Go)
- Bright Data (15$/GB, Pay as You Go)
- SmartProxy (12.5$/GB, Pay as You Go)
- ScrapingBee (49$/month, monthly credits)
- Scraping Dog (30$/Month, monthly credits)
Once you have your proxies, you can use them with the Python requests by passing a dictionary to the proxies parameter of the get() request.
import requests
url = 'https://crawler-test.com/'
proxies = {
'http': '128.199.237.57:8080'
}
r = requests.get(url, proxies=proxies)
3 Python Web Scraping Projects
Here are3 examples of Python web scraping projects that you can try.
- Try one of the Best websites to practice web scraping to practice scraping with BeautifulSoup
- Try to scrape Google results using the Apify third-party tool
- Learn how to scrape LinkedIn jobs with Python
Conclusion
We have now covered how to do web scraping with Python.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.