The Python requests library is an HTTP requests library in Python.
Python Requests Example
import requests
url = 'https://crawler-test.com/'
r = requests.get(url)
r.text
In this tutorial, you will learn how to use the Python requests module with examples:
- Understand the structure of a request
- Make GET and POST requests
- Read and extract elements of the HTML of a web page
- Improve your requests
Navigation
Show
What is the Python Requests Library?
The python requests library, also known as python requests, is a HTTP library that allows users to send HTTP requests using Python. Its tagline “Python HTTP for Humans” represents well the simplicity of the package.
Let’s learn how to use Python Requests.
How to Use Python Requests
Follow these steps to use the Python requests module.
- Install the Python Requests Package
$ pip install requests - Import the Requests Module
import requests - Make a Request using the GET method
Use the GET method and store the response in a variable.
r = requests.get(url) - Read the response using request’s attributes and methods
You can interact with the Python request object using its attributes (e.g.
r.status_code) and methods (e.g.r.json()).
Download and Install Python Requests
Use pip to install the latest version of python requests.
$ pip install requests
For this guide, you will need to install Python and install the following packages.
$ pip install beautifulsoup4
$ pip install urllib
Import the Request Module
To import the requests library in Python use the import keyword.
import requests
Python Requests Functions
Below are listed the Python requests functions:
- get: Sends a GET requests to a given URL. E.g.
get(url, parameters, arguments) - post: Sends a POST request to publish specified data to a given URL. E.g.
post(url, data, json, arguments) - put: Sends a PUT request to replace data at a given URL. E.g.
put(url, data, arguments) - patch: Sends a PATCH request to make partial changes to the data of a given URL. E.g
patch(url, data,arguments) - delete: Sends a DELETE request to delete data from a given URL. E.g
delete(url, arguments) - head: Sends a HEAD request to a given URL. This is similar to a GET request, but without the body. E.g.
head(url, arguments) - options: Specify communication options for a given URL. E.g.
options(url) - Request: Creates request object by specifying the method to choose.
We will now view some examples of requests functions in Python.
Python Get Requests
The python requests get() function sends GET requests to a web server for a given URL, set of parameters and arguments. The get() function follows this pattern:
get(url, parameters, arguments)
How to Send Get Requests in Python
To send GET requests in Python, use the get() function with the URL that you want to retrieve information from.
import requests
url = 'https://crawler-test.com/'
response = requests.get(url)
print('URL: ', response.url)
print('Status code: ', response.status_code)
print('HTTP header: ', response.headers)
Output:
URL: https://crawler-test.com/
Status code: 200
HTTP header: {'Content-Encoding': 'gzip', 'Content-Type': 'text/html;charset=utf-8', 'Date': 'Sun, 03 Oct 2021 23:41:59 GMT', 'Server': 'nginx/1.10.3', 'Vary': 'Accept-Encoding', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'SAMEORIGIN', 'X-XSS-Protection': '1; mode=block', 'Content-Length': '8098', 'Connection': 'keep-alive'}
Post Requests
The python requests post() function sends POST requests to a web server to publish specified data to a given URL. The post() function follows this pattern:
post(url, data, json, arguments)
How to Send Post Requests in Python
To send POST requests in Python, use the post() function. Add the URL and a dictionary representation of the data to be published to the data parameter.
import requests
url = 'https://httpbin.org/post'
payload = {
'name':'Jean-Christophe',
'last_name':'Chouinard',
'website':'https://www.jcchouinard.com/'
}
response = requests.post(url, data = payload)
response.json()
Output:
{'args': {},
'data': '',
'files': {},
'form': {'last_name': 'Chouinard',
'name': 'Jean-Christophe',
'website': 'https://www.jcchouinard.com/'},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Content-Length': '85',
'Content-Type': 'application/x-www-form-urlencoded',
'Host': 'httpbin.org',
'User-Agent': 'python-requests/2.24.0',
'X-Amzn-Trace-Id': 'Root=1-615a4271-417e9fff3c75f47f3af9fde2'},
'json': None,
'origin': '149.167.130.162',
'url': 'https://httpbin.org/post'}
Python Response Object’s Methods and Attributes
The python.response object contains the server’s response to the HTTP request.
You can investigate the details of the Response object by using help().
import requests
url = 'https://crawler-test.com/'
response = requests.get(url)
help(response)
In this tutorial we will look at the following:
- text, data descriptor : Content of the response, in unicode.
- content, data descriptor : Content of the response, in bytes.
- url, attribute : URL of the request
- status_code, attribute : Status code returned by the server
- headers, attribute : HTTP headers returned by the server
- history, attribute : list of response objects holding the history of request
- links, attribute : Returns the parsed header links of the response, if any.
- json, method : Returns the json-encoded content of a response, if any.
Access the Response Methods and Attributes
The response from the request is an object in which you can access its methods and attributes.
You can access the attributes using the object.attribute notation and the methods using the object.method() notation.
import requests
url = 'http://archive.org/wayback/available?url=jcchouinard.com'
response = requests.get(url)
response.text # access response data atributes and descriptors
response.json() # access response methods
{'url': 'jcchouinard.com',
'archived_snapshots': {'closest': {'status': '200',
'available': True,
'url': 'http://web.archive.org/web/20210930032915/https://www.jcchouinard.com/',
'timestamp': '20210930032915'}}}
Process the Python Response
How to Access the JSON of Python Requests
In Python requests, the response.json() method allows to access the JSON object of the response. If the result of the request is not written in a JSON format, the JSON decoder will return the requests.exceptions.JSONDecodeError exception.
How to Show the Status Code of a Python Request
To show the status code returned by a Python get() request use the status_code attribute of the response Object.
import requests
url = 'https://crawler-test.com/'
r = requests.get(url)
r.status_code
# 200
How to Get the HTML of the Page with Python Requests
To get the HTML of a web page using python requests, make a GET request to a given URL and the text attribute of the response Object to get the HTML as Unicode and the content attribute to get HTML as bytes.
import requests
url = 'https://crawler-test.com/'
r = requests.get(url)
r.text # get content as a string
r.content # get content as bytes
How to Show the HTTP header of a GET Request
To show the HTTP headers used in a Python GET request, use the headers attribute of the response Object.
import requests
url = 'https://crawler-test.com/'
r = requests.get(url)
r.headers
{'Content-Encoding': 'gzip', 'Content-Type': 'text/html;charset=utf-8', 'Date': 'Tue, 05 Oct 2021 04:23:27 GMT', 'Server': 'nginx/1.10.3', 'Vary': 'Accept-Encoding', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'SAMEORIGIN', 'X-XSS-Protection': '1; mode=block', 'Content-Length': '8099', 'Connection': 'keep-alive'}
How to Show HTTP Redirects with Python Requests
To show HTTP redirects that happened during a Python get() request, use the history attribute of the response Object. Create a for loop on the response.history and get the .url and .status_code attributes of each element of the history.
import requests
url = 'https://crawler-test.com/redirects/redirect_chain_allowed'
r = requests.get(url)
for redirect in r.history:
print(redirect.url, redirect.status_code)
print(r.url, r.status_code)
https://crawler-test.com/redirects/redirect_chain_allowed 301
https://crawler-test.com/redirects/redirect_chain_disallowed 301
https://crawler-test.com/redirects/redirect_target 200
Parse the HTML with Requests and BeautifulSoup
To parse the HTML of Python requests, use the lxml or the BeautifulSoup library on the response object.
BeautifulSoup is a Python library that allow you to parse HTML and XML to pull data from them. BeautifulSoup can be used to parse the HTML returned in the Python Response object.
How the Python Response Object Returns the HTML
The Python Response object, returns the HTML from the URL passed in the get() request as Unicode or Bytes.
The textual format of the returned HTML makes it hard to extract information from it.
from bs4 import BeautifulSoup
import requests
# Make the request
url = 'https://crawler-test.com/'
r = requests.get(url)
r.text[:500]
'<!DOCTYPE html>\n<html>\n <head>\n <title>Crawler Test Site</title>\n \n <meta content="en" HTTP-EQUIV="content-language"/>\n \n <link type="text/css" href="/css/app.css" rel="stylesheet"/>\n <link type="image/x-icon" href="/favicon.ico?r=1.6" rel="icon"/>\n <script type="text/javascript" src="/bower_components/jquery/jquery.min.js"></script>\n \n <meta content="Default description XIbwNE7SSUJciq0/Jyty" name="description"/>\n \n\n \n <link rel="alternate" media'
How to Parse HTML with BeautifulSoup
To parse the HTML returned from a get() request, pass the response.text attribute to the BeautifulSoup class of the bs4 library. Use the ‘html.parser’ argument to parse the HTML.
# Parse the HTML
soup = BeautifulSoup(r.text, 'html.parser')
soup
This will return a soup object that can be used to extract data from it.
<!DOCTYPE html>
<html>
<head>
<title>Crawler Test Site</title>
<meta content="en" http-equiv="content-language"/>
<link href="/css/app.css" rel="stylesheet" type="text/css"/>
...
</html>
The output is easier to interpret now that it was parsed with BeautifulSoup.
You can extract tag using the find() or find_all() methods.
soup.find('title')
Output:
<title>Crawler Test Site</title>
soup.find_all('meta')
Output:
[<meta content="en" http-equiv="content-language"/>,
<meta content="Default description XIbwNE7SSUJciq0/Jyty" name="description"/>,
<meta content="nositelinkssearchbox" name="google"/>,
<meta content="0H-EBys8zSFUxmeV9xynoMCMePTzkUEL_lXrm9C4a8A" name="google-site-verification"/>]
Or, even select the attributes of the tag.
soup.find('meta', attrs={'name':'description'})
Output:
<meta content="Default description XIbwNE7SSUJciq0/Jyty" name="description"/>
To extract the main SEO tags from a web page, use requests along with the BeautifulSoup parsing library. The find() method of the soup object will allow you to extract HTML tags such as the H1, the title, the meta description, and other important SEO tags.
from bs4 import BeautifulSoup
import requests
# Make the request
url = 'https://crawler-test.com/'
r = requests.get(url)
# Parse the HTML
soup = BeautifulSoup(r.text, 'html.parser')
# Get the HTML tags
title = soup.find('title')
h1 = soup.find('h1')
description = soup.find('meta', attrs={'name':'description'})
meta_robots = soup.find('meta', attrs={'name':'robots'})
canonical = soup.find('link', {'rel': 'canonical'})
# Get the text from the HTML tags
title = title.get_text() if title else ''
h1 = h1.get_text() if h1 else ''
description = description['content'] if description else ''
meta_robots = meta_robots['content'] if meta_robots else ''
canonical = canonical['href'] if canonical else ''
# Print the tags
print('Title: ', title)
print('h1: ', h1)
print('description: ', description)
print('meta_robots: ', meta_robots)
print('canonical: ', canonical)
Output:
Title: Crawler Test Site
h1: Crawler Test Site
description: Default description XIbwNE7SSUJciq0/Jyty
meta_robots:
canonical:
Extracting all the links on a page
from bs4 import BeautifulSoup
import requests
from urllib.parse import urljoin
url = 'https://crawler-test.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
links = []
for link in soup.find_all('a', href=True):
full_url = urljoin(url, link['href']) # join domain to path
links.append(full_url)
# Show 5 links
links[:5]
Output:
['https://crawler-test.com/',
'https://crawler-test.com/mobile/separate_desktop',
'https://crawler-test.com/mobile/desktop_with_AMP_as_mobile',
'https://crawler-test.com/mobile/separate_desktop_with_different_h1',
'https://crawler-test.com/mobile/separate_desktop_with_different_title']
Python Requests Headers
HTTP requests headers are used to pass additional information with an HTTP request or response, without changing the behaviour of the request. Request headers are simply passed to the request.
How to Add Requests Readers to Python Request
To add a request headers to your GET and POST requests, pass a dictionary to the headers parameter of the get() and post() functions.
import requests
url = 'http://httpbin.org/headers'
# Add a custom header to a GET request
r = requests.get(url, headers={"Content-Type":"text"})
# Add a custom header to a POST request
r = requests.post(url, headers={'Authorization' : 'Authorization': 'Bearer {access_token}'})
How to Add an Access Token to the Headers of the Request
To add an Access Token to a Python request, pass a dictionary to the params parameter of the get() request.
import requests
url = 'http://httpbin.org/headers'
access_token = {
'Authorization': 'Bearer {access_token}'
}
r = requests.get(url, headers=access_token)
r.json()
{'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Authorization': 'Bearer {access_token}',
'Host': 'httpbin.org',
'User-Agent': 'python-requests/2.24.0',
'X-Amzn-Trace-Id': 'Root=1-615aa0b3-5c680dcb575d50f22e9565eb'}}
Query String Parameters
The query parameters allow you to customize your Python request by passing values to the query string parameters.
Most API requests require to add query parameters to the request. This is the case with the Wikipedia API.
How to Add Parameters to the URL of a Python Request
To add query string parameters to a Python requests, pass a dictionary of parameters to the params argument. Here is how the request url looks like.
import requests
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action': 'query',
'format': 'json',
'titles': 'Requests (software)',
'prop': 'extracts'
}
response = requests.get(url, params=params)
print('Request URL:', response.url)
# Result
Request URL: https://en.wikipedia.org/w/api.php?action=query&format=json&titles=Requests+%28software%29
data = response.json()
page = next(iter(data['query']['pages'].values()))
print(page['extract'][:73])
How to Handle Exception Errors in with Requests
To deal with exceptions raised using Python requests, surround your request with the try and except statements.
import requests
url = 'bad url'
try:
r = requests.get(url)
except Exception as e:
print(f'There was an error: {e}')
There was an error: Invalid URL 'bad url': No schema supplied. Perhaps you meant http://bad url?
How to Change User-Agent in Your Python Request
To change the user-agent of your Python request, pass a dictionary to the headers parameter of the get() request.
import requests
url = 'https://www.reddit.com/r/python/top.json?limit=1&t=day'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
r = requests.get(url, headers=headers)
How to Add Timeouts to a Request in Python
To add a timeout to a Python request, pass a float value to the timeout parameter of the get() request.
import requests
url = 'https://httpbin.org/delay/3'
try:
r = requests.get(url, timeout=0.1)
except Exception as e:
print(e)
r.status_code
HTTPConnectionPool(host='httpbin.org', port=80): Max retries exceeded with url: /basic-auth/user/pass (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x7fb03a7fa290>, 'Connection to httpbin.org timed out. (connect timeout=0.1)'))
401
How to use Proxies with Python Requests
To use proxies with the Python requests, pass a dictionary to the proxies parameter of the get() request.
import requests
url = 'https://crawler-test.com/'
proxies = {
'http': '128.199.237.57:8080'
}
r = requests.get(url, proxies=proxies)
You can find free proxies from proxyscrape (may already be blocked). If you start to scale however, you will need a premium proxy service.
- Apify WebScraper (15$/GB)
- Oxylabs (15$/GB, Pay as You Go)
- Bright Data (15$/GB, Pay as You Go)
- SmartProxy (12.5$/GB, Pay as You Go)
- ScrapingBee (49$/month, monthly credits)
Python Requests Sessions
The Python requests Session() object is used to make requests with parameters that persist through all the requests in a single session.
How to use the Requests Session Object (Example)
# Request Session example
import requests
url = 'https://httpbin.org/headers'
# Create HTTP Headers
access_token = {
'Authorization': 'Bearer {access_token}'
}
with requests.Session() as session:
# Add HTTP Headers to the session
session.headers.update(access_token)
# Make First Request with session.get()
r1 = session.get(url)
# Make Second Request
r2 = session.get(url)
# Show HTTP Headers
print('r1: ', r1.json()['headers']['Authorization'])
print('r2: ', r2.json()['headers']['Authorization'])
r1: Bearer {access_token}
r2: Bearer {access_token}
How to Retry Failed Python Requests
import requests
from requests.adapters import HTTPAdapter, Retry
s = requests.Session()
retries = Retry(total=3,
backoff_factor=0.1,
status_forcelist=[500,502,503,504])
s.mount('http://', HTTPAdapter(max_retries=retries))
s.mount('https://', HTTPAdapter(max_retries=retries))
try:
r = s.get('https://httpstat.us/500')
except Exception as e:
print(type(e))
print(e)
How To Log All Requests From The Python Request Library
Use the logging library to log all requests and set the level keyword of the basicConfig() method to logging.DEBUG.
import requests
import logging
logging.basicConfig(level=logging.DEBUG)
urls = [
'https://www.crawler-test.com',
'https://www.crawler-test.com/status_codes/status_500',
'https://www.crawler-test.com/mobile/separate_desktop'
]
for url in urls:
r = requests.get(url)
Other HTTP Methods in the Requests Module
On top of GET and POST Requests, the Python library allows to use other popular HTTP functions such as HEAD, PUT, DELETE, PATCH and OPTIONS.
requests.head('https://httpbin.org/get') # Get request HTTP header
requests.put('https://httpbin.org/put', data={'key':'value'}) # Create new resource with payload
requests.delete('https://httpbin.org/delete') # Delete resource
requests.patch('https://httpbin.org/patch', data={'key':'value'}) # Partial modification
requests.options('https://httpbin.org/get') # Specify communication options
Python Requests Best Practices
There are best practices you should follow when using the Python requests library:
- Always use timeouts to avoid code being stuck while loading a web page.
- Keep a log about each request and response in case your code breaks (timestamp, url, status code, etc.)
- Handle potential exceptions by using try/except to define what should happen if code broke.
- Perform unit tests using try/except to check if some important portion of the page exists. If a change in the page happen in the future, you should be alerted so that the code don’t break.
- Use the head() function when you don’t need to fetch the body of the page in order to improve requests performance.
Python Requests Cheatsheet
This cheatsheet shows you commonly used requests functions in Python along with what each argument does. Note that optional arguments defined by **kwargs are described in the “Common Parameters for all Methods” section.
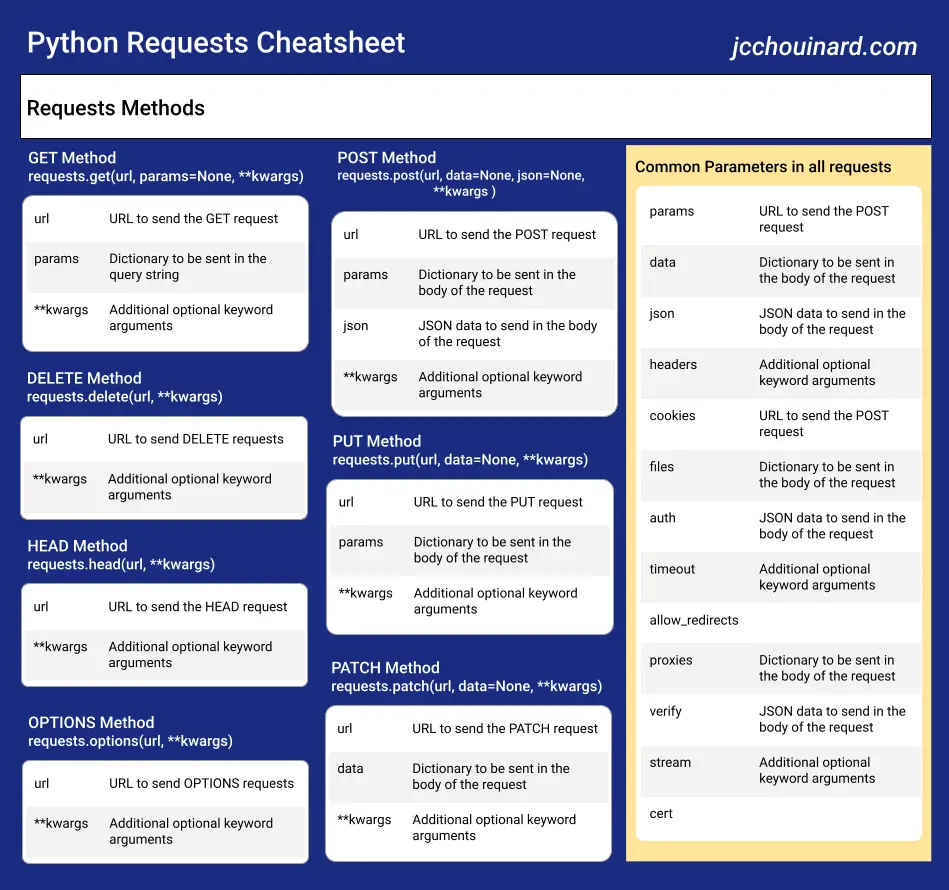
Requests Functions
GET Function
requests.get(url, params=None, **kwargs)
- url: The URL to send the GET request to.
- params: Dictionary or bytes to be sent in the query string of the request URL.
- **kwargs: Additional optional keyword arguments.
POST Function
requests.post(url, data=None, json=None, **kwargs)
- url: The URL to send the POST request to.
- data: Dictionary, bytes, or file-like object to send in the body of the request.
- json: JSON data to send in the body of the request.
- **kwargs: Additional optional keyword arguments.
PUT Function
requests.put(url, data=None, **kwargs)
- url: The URL to send the PUT request to.
- data: Dictionary, bytes, or file-like object to send in the body of the request.
- **kwargs: Additional optional keyword arguments.
DELETE Function
requests.delete(url, **kwargs)
- url: The URL to send the DELETE request to.
- **kwargs: Additional optional keyword arguments.
HEAD Function
requests.head(url, **kwargs)
- url: The URL to send the HEAD request to.
- **kwargs: Additional optional keyword arguments.
OPTIONS Function
requests.options(url, **kwargs)
- url: The URL to send the OPTIONS request to.
- **kwargs: Additional optional keyword arguments.
PATCH Function
requests.patch(url, data=None, **kwargs)
- url: The URL to send the PATCH request to.
- data: Dictionary, bytes, or file-like object to send in the body of the request.
- **kwargs: Additional optional keyword arguments.
Common Parameters for all Requests Functions
- params: Dictionary or bytes to be sent in the query string of the request URL.
- data: Dictionary, bytes, or file-like object to send in the body of the request.
- json: JSON data to send in the body of the request.
- headers: Dictionary of HTTP headers to send with the request.
- cookies: Dictionary or CookieJar object to send with the request.
- files: Dictionary of ‘name’: file-like-objects for multipart encoding upload.
- auth: Authentication credentials as a tuple or an object returned by
requests.authmodule. - timeout: Timeout value in seconds for the request.
- allow_redirects: Whether to follow redirects or not.
- proxies: Dictionary mapping protocol to the URL of the proxy.
- verify: Either a boolean, string, or a
RequestsSSL/TLS Certificate to verify the request. - stream: Whether to enable streaming of the response content.
- cert: SSL/TLS client certificate file (
.pem) or tuple of both the certificate and key files.
Response Methods and Attributes
response.close(): Close the connection to the serverresponse.iter_content()response.iter_lines()response.json()response.raise_for_status()response.headers(): Return a dictionary of the response headers.response.text: Return the response content as a string.response.content: Return the response content as bytes.response.url: Return the URL of the response.response.encoding: Return the encoding of the response.response.ok: Return True if the response status code is less than 400response.cookies: Return a dictionary of the response cookies.
Tutorials using Requests
- Wikipedia API with Python
- Read RSS Feed with Python and Beautiful Soup
- How to Post on LinkedIn API With Python
- Reddit API Without API Credentials
- Send Message With Slack API and Python
- What GMB Categories are the Competition Using?
- Python Libraries for SEO – Beginner Guide
- Random User-Agent With Python and BeautifulSoup (by JR Oakes)
- Get BERT Score for SEO (by Pierre Rouarch)
Interesting work from the community
- How to Check Status Codes of URLs in a Sitemap via Python (by Koray Tuğberk GÜBÜR)
- Automatically Find SEO Interlinking Opportunities with Python (by Greg Bernhardt)
- Yoast SEO API Python example with Requests + Pandas (by Erick Rumbold)
- How To Download Multiple Images In Python (by James Phoenix)
- Google Autosuggest Trends for Niche Keywords (by Stefan Neefischer)
- Asynchronous Web Scraping Python (by James Phoenix)
Other Web Scraping Tutorials
Facts about Python Requests
| Python Requests Author | Kenneth Reitz |
| Python Requests Language | Python |
| Python Requests Functions | GET, POST, PUT, DELETE, PATCH, OPTIONS, HEAD |
| Python Requests Release | 2011-02-14 |
Request Properties
- apparent_encoding: Return the apparent encoding
- content: Return the content of the response, in bytes
- cookies: Show the object containing the cookies returned by the server
- elapsed: Time elapsed between when request is sent VS when response is returned
- encoding: Show encoding used to decode
r.text - headers: Return a dictionary of response headers
- history: Return a list of response objects containing the request history
- is_permanent_redirect: Show if URL is permanently redirected
- is_redirect: Show if URL is redirected
- links: Return the links HTTP header
- next: Return an object for the next request in a redirection
- ok: Show if status code is less than 400
- reason: Textual explanation of the status code
- request: Show the request object of the request sent for a given response
- status_code: Show the status code returned by the server
- text: Return the content of the response, in unicode
- url: Show the URL of the response
What’s Next
Conclusion
If you are looking for an alternative to the requests library, you may be interested in the requests-HTML library that provides some built-in HTML parsing options.
This library is not only useful for web scraping, but also for web development and any other endeavour that uses APIs.
We now conclude the introduction on the Python Requests library.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.