Selenium is a Python library that is used in web scraping as well as browser-automation tasks.
In this tutorial, we will learn web scraping and automation with Selenium with Python code examples.
For this tutorial, you will first need to install Python.
Navigation
Show
What is Selenium Web Driver?
Selenium Web Driver is a framework that allows to automate the browser mainly for testing purposes. Selenium is also often used for web scraping purposes, mainly when JavaScript needs to be executed to gain access to the underlying content.
What is Web Scraping
Web scraping is the process of using a bot to extract data from a website and export it into a digestible format. A web scraper extracts the HTML code from a web page, which is then parsed to extract valuable information.
How is Selenium Useful in Web Scraping?
Selenium is a convenient framework to scrape information from a web page that requires JavaScript to be executed. Selenium uses a web browser to navigate to web pages, and thus execute all the JavaScript an return content that may not be available with simple HTTP requests.
Simple Web Scraping Example With Python Selenium
Let’s start with the simplified steps and an example of how to perform browser automation and web scraping with Python and Selenium.
Install Selenium in Terminal.
pip3 install selenium webdriver_managerAutomate the browser and scrape something from a Web Page.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
title = driver.title
print(title)
Crawler Test SiteNow, that we have seen what browser automation can do, let’s learn what exactly is selenium.
If you end up with an issue, a simple solution is to use webdriver without webdriver-manager.
from selenium import webdriver
driver = webdriver.Chrome()
Getting Started with Selenium
To use Selenium, you will need to install Python, the Selenium library and the Selenium Web Browser.
Install Selenium
Below you will learn how to install Selenium using pip and conda.
Install Selenium With Pip
To install Selenium with pip, open the Terminal or command line and type:
$ pip install SeleniumInstall Selenium With Anaconda
To install Selenium with conda, open the Anaconda Prompt and type:
$ conda install -c conda-forge seleniumNow that we have Selenium installed, we need to install a webdriver.
Install Selenium Webdriver
Selenium needs a webdriver to work with your browser.
You can Install Selenium Web Driver either from the documentation site or using webdriver-manager.
Using web driver manager is definitely the simplest way.
$ pip3 install webdriver-managerInstall Chrome Driver in Python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Create Driver Instance
driver = webdriver.Chrome(service=service)
# Get Web Page
driver.get('https://www.crawler-test.com')
time.sleep(1)
driver.quit()
How To Use Selenium Web Driver
To use Selenium Web Driver, you need to install the library, install a web driver, create an instance of a web driver and then execute any of the available Selenium driver methods on the driver object.
Step 1: Import the Webdriver Library
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
Step 2: Create the Web Driver Instance
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
Step 3: Use the get() method to load a website
driver.get('https://www.crawler-test.com')
Step 3: Use the attributes and methods to access element or execute actions
# .title attribute to print the title of the page
print(driver.title)
# Quit() method to close the browser
driver.quit()
Now, we will learn how to use the Selenium web driver for automation tasks and web scraping purposes.
To use selenium web driver you will need to learn how to:
- Open and close your browser with Selenium
- Open a Web Page With Selenium
- Find HTML Elements in Selenium (by tag name, id, class, xpath or CSS selector)
- Interact With Elements in Selenium (clicking on links, filling forms)
Open And Close Your Browser
To open and close your browser using selenium, use the quit() method on the webdriver.Chrome() object.
To simply close a window or tab, use the close() method.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
driver.get('https://www.crawler-test.com')
time.sleep(1)
driver.quit()
A browser will open with some kind of mention that Chrome is being controlled by automated test software and then it will close.

If you don’t close the driver, the browser will stay open.
Running Selenium with a Context Manager
A better option to run Selenium is to use a context manager that will automatically open and close the driver while it is needed.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
Context manager is a good practice as it prevents users from forgetting to close the driver, and closing it even if the enclosed code triggers exceptions (just like below).
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
# Force Trigger an exception
time.sleep(3)
a = 1/0
Open a Web Page With Selenium
To open a web page with Selenium Web Driver, use the get() method on the driver object.
driver.get(url)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
Find HTML Elements in Selenium
To find an HTML element from a web page with Selenium, use the find_element() and the find_elements() method on the driver object with the first argument being the element to find and the second argument its value.
driver.find_element('link text', 'Title Empty')
Finding Elements with XPath
To find HTML elements using XPath in Selenium, use the By class from webdriver.common.by.
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
Finding Elements with CSS Selector
To find HTML elements using the CSS Selector syntax in Selenium, use By.CSS_SELECTOR as the first argument of the find_element() method.
content = driver.find_element(By.CSS_SELECTOR, 'p.content')
Finding Elements by Tag Name
To find HTML elements by Tag Name in Selenium, use By.TAG_NAME as the first argument of the find_element() method.
from selenium.webdriver.common.by import By
heading1 = driver.find_element(By.TAG_NAME, 'h1')
Finding Elements by Class Name
To find HTML elements by Class Name in Selenium, use By.CLASS_NAME as the first argument of the find_element() method.
content = driver.find_element(By.CLASS_NAME, 'content')
Interact With Elements in Selenium
Selenium allows to interact with the browser and offers methods such as the click() and the send_keys() methods.
How to Click on a Link with Selenium
You can click on a link automatically with Selenium with this process:
- Open web driver and go to URL
- Find an element and store it in a variable
- Click the link
# Clicking on Links with Selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
# 1. Go to URL
url = 'https://www.crawler-test.com'
driver.get(url)
time.sleep(1)
# 2. Find element by its link text
link_text = driver.find_element(By.LINK_TEXT, 'Title Empty')
# 3. Click on the link
link_text.click()
time.sleep(1)
How to Click a Link in a New Tab with Selenium
To open a Link in a new tab in Selenium use the Keys class with command + enter on Mac and Control + Enter on Windows.
from selenium.webdriver.common.keys import Keys
link = driver.find_element(By.LINK_TEXT, 'Title Empty')
link.send_keys(Keys.COMMAND + Keys.ENTER) # Mac
link.send_keys(Keys.CONTROL + Keys.ENTER) # Windows
How to Fill a Form or a Search Box with Selenium
To fill a form or a search box with Selenium, find the form input and the form button identifiers (such as the tag id or class). Then, use the send_keys() method to fill the input object and then use the click() method on the button object to submit the form.
Find the id of the form
To do this, right-click on the search box and click inspect element.
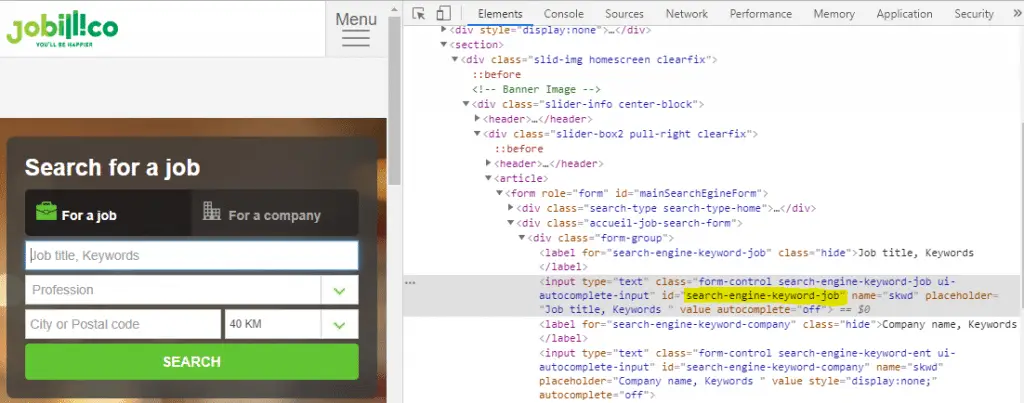
Note the ID of the Input element.
Repeat the process to find the ID of the button.
Fill the Form in Selenium
# Clicking on Links with Selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
# Go to URL
url = 'https://www.jobillico.com'
driver.get(url)
# Find element by its ID
search_box = driver.find_element(By.ID, 'search-engine-keyword-job')
# Fill the form
search_box.send_keys('python')
time.sleep(1)
# Get Button ID
button_id = driver.find_element(By.ID, 'btn-search-engine')
# Click The Button
button_id.click()
time.sleep(3)
Execute the Form by Simulating the ENTER key
You can also use Keys to submit the form. This will simulate a user that presses the ENTER key.
from selenium.webdriver.common.keys import Keys
search_box.send_keys(Keys.ENTER)
These are some of the many ways that could work with any form. The next example uses another way using the submit()function instead.
How to Get Current URL in Selenium
To show the current URL of a web page in Selenium, use the current_url attribute on the driver object.
driver.current_url
How to Get All Links from a Web Page with Selenium
To get all thinks from all links from a web page in Selenium, use the find_elements() method, with the By.XPATH argument and then loop through each link to get the href attribute.
links = driver.find_elements(By.XPATH, '//a[@href]')
for link in links
print(link.get_attribute('href'))
Example
# Get All Links with Selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
# Store ID of the current window
links = driver.find_elements(By.XPATH, '//a[@href]')
hrefs = []
for link in links:
hrefs.append(link.get_attribute('href'))
hrefs
How to Switch to a New Window or Tab
To switch to a new window or tab in Selenium use the switch_to.window() or the switch_to.new_window() methods on the web driver object.
Create a New Tab or Window and Switch to It
To create and switch to a new window or tab in Selenium use the switch_to.new_window() method on the web driver object with 'window' or 'tab' as its argument.
# Open a new tab and switch to new tab
driver.switch_to.new_window('tab')
# Open a new window and switch to new window
driver.switch_to.new_window('window')
Get ID of current Window
# Store ID of the current window
current_window = driver.current_window_handle
Switch to An Existing Window or Tab
To switch to an existing window or tab in Selenium, use the window_handles attribute on the driver object and loop through each of the handles until the handle is not equal to the current window handle.
# Get All Links with Seleniums
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
# Store ID of the current window
current_window = driver.current_window_handle
# Find links
links = driver.find_elements(By.XPATH, '//a[@href]')
# open first 3 links
for link in links[:3]:
link.send_keys(Keys.COMMAND + Keys.ENTER)
time.sleep(3)
# Get open tabs ids
handles = driver.window_handles
for handle in handles:
if handle == current_window:
continue
else:
driver.switch_to.window(handle)
time.sleep(3)
break
Close a Window or Tab
driver.close()
#Switch back to the old tab or window
driver.switch_to.window(original_window)
How to Wait for a Page to Load in Selenium
The simplest way to see if a page is loaded is to use WebDriverWait with the until() method. The until() method should try to find an element on page that should be there before doing anything else.
In the example below, we will wait a maximum of 3 seconds until it finds an H1 on the page.
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(service=service)
url = 'https://www.crawler-test.com'
driver.get(url)
h1 = WebDriverWait(driver, timeout=3).until(lambda d: d.find_element(By.TAG_NAME, 'h1'))
print(h1.text)
driver.quit()
A less efficient way is to add time.sleep(). However, we have no way of knowing how long the page will take to load.
Stop Selenium Loading Web Page with Timeout
To limit the amount of time allowed to load a web page in selenium, use the set_page_load_timeout() method.
# Maximum wait time for a page load
with webdriver.Chrome(service=service) as driver:
url = 'https://www.jcchouinard.com/learn-selenium-python-seo-automation/'
driver.set_page_load_timeout(0.5)
driver.get(url)
The above will throw an exception, so you won’t be able to to do anything with it.
Use Eager Loading
The eager loading options waits until the initial HTML document has been completely loaded and parsed and then discards the rest.
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
options = Options()
options.page_load_strategy = 'eager'
url = 'https://www.jcchouinard.com/learn-selenium-python-seo-automation/'
# Maximum wait time for a page load
with webdriver.Chrome(service=service, options=options) as driver:
driver.get(url)
How to Scroll Down with Selenium
To scroll down a page in Selenium Python, use the execute_script() method with the window.scrollTo() JavaScript function.
driver.execute_script("window.scrollTo(0, Y)")
Where Y can be replace by the pixel height (e.g. 500) where you want to scroll to. On top of it, you can scroll down the bottom of the page using document.body.scrollHeight.
# Get All Links with Seleniums
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(3)
Run Selenium in Headless Mode
To run Selenium Headless, use the Options class and set the .headless attribute to True. Running Selenium in headless mode allows to run the browser in the background without seeing the browser window.
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
url = 'https://www.jcchouinard.com/python-for-seo/'
options = Options()
options.headless = True
# options.add_argument("--window-size=1920,1200")
driver = webdriver.Chrome(options=options,executable_path='/usr/local/bin/chromedriver')
driver.get(url)
time.sleep(3)
t = driver.title
print(f'Title: {t}')
driver.quit()
Selenium Web Scraping Project with Python
In this web scraping project with Python and Selenium, we will learn how to extract common meta tags and HTML tags from a web page and end the project by storing a screenshot of the page.
Here are the methods to scrape the most common HTML elements on the web page such as the title, h1, metad description, canonical and href links.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# Set up Selenium Chrome WebDriver
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
# Navigate to the web page
url = 'https://www.crawler-test.com' # Replace with the desired URL
driver.get(url)
# Extract the elements
title = driver.find_element(By.TAG_NAME, "title").text
# Get Meta Description
meta_description = driver.find_element(By.CSS_SELECTOR, "meta[name='description']").get_attribute("content")
h1 = driver.find_element(By.TAG_NAME, "h1").text
#canonical = driver.find_element(By.CSS_SELECTOR, "link[rel='canonical']").get_attribute("href")
#meta_robots = driver.find_element(By.CSS_SELECTOR, "meta[name='robots']").get_attribute("content")
href_links = [link.get_attribute("href") for link in driver.find_elements(By.TAG_NAME, "a")]
# Print the extracted elements
print("Title:", title)
print("Meta Description:", meta_description)
print("H1:", h1)
#print("Canonical:", canonical)
#print("Meta Robots:", meta_robots)
print("List of href links:")
for link in href_links:
print(link)
# Quit the WebDriver
driver.quit()
Save a Screenshot With Selenium in Python
To save a screenshot of a web page using Selenium in Python, use the save_screenshot() method.
driver.save_screenshot('crawler-test.png')
Full example of saving a screenshot with Selenium (Python):
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
url = 'https://www.crawler-test.com'
driver.get(url)
driver.save_screenshot('crawler-test.png')
Web Scraping with Selenium and BeautifulSoup
It is better to use Selenium built-in methods than BeautifulSoup to parse the HTML of the page, but if you still prefer using BeautifulSoup, simply pass the page_source attribute of the driver to the BeautifulSoup object.
BeautifulSoup(driver.page_source)from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Set up Selenium Chrome WebDriver
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
# Navigate to the web page
url = 'https://www.crawler-test.com' # Replace with the desired URL
driver.get(url)
soup = BeautifulSoup(driver.page_source)
print(soup.find('h1'))
Selenium Automation Project with Python
In this section, we will learn Selenium with an easy automation project in Python by searching for something on Google and clicking on the first search result.
Search For Something On Google Using Selenium
To search for something on Google using Python and Selenium, use the find_element(), send_keys() and submit() methods on the driver object.
Do not repeat this action too often without using proxies or you will hit Captchas and risk being blocked.
Here are the steps to perform Google search with Selenium:
- Open a Web Browser
- Go to Google.com
- Search for a Query String
- Close the Browser
# Clicking on Links with Selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
# Go to URL
url = 'https://www.google.com/'
driver.get(url)
# Find element by its Nme
search_box = driver.find_element(By.NAME, 'q')
# Fill the form
search_box.send_keys('Learn Selenium with jcchouinard')
time.sleep(1)
# Simulate pressing ENTER
search_box.submit()
time.sleep(5)
Open The First Result In Google With Python
To click on the first search result in Google with Selenium use Xpath to select the first search result.
Even if you know nothing about Xpath, you can reuse some xpath functions for Google or read my tutorial on web scraping with XPath.
In a nutshell, to find the XPath of Google’s first search result, click on inspect on the first search result, right-click on the HTML element. Go to copy > Copy Xpath. You have however to look at the Selenium driver, not regular Chrome browser. Thus, run this outside the context manager first to inspect the DOM of Google search.
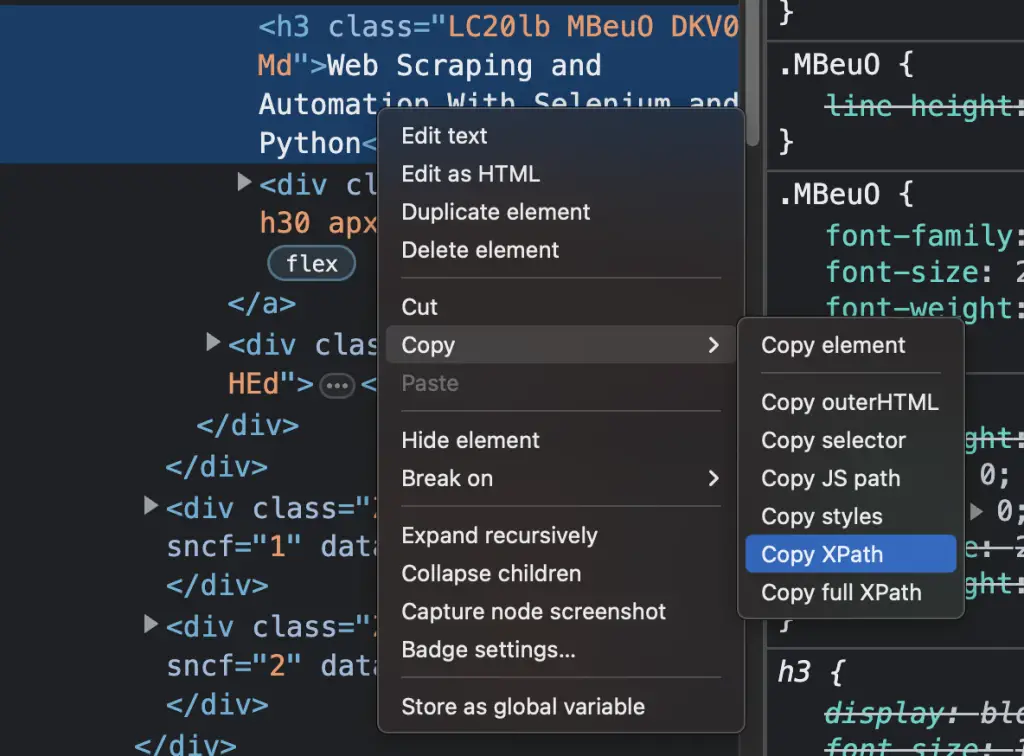
# Clicking on Links with Selenium
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# Install Webdriver
service = Service(ChromeDriverManager().install())
# Rune Selenium with a Context Manager
with webdriver.Chrome(service=service) as driver:
# Go to URL
url = 'https://www.google.com/'
driver.get(url)
# Find element by its Nme
search_box = driver.find_element(By.NAME, 'q')
# Fill the form
search_box.send_keys('Learn Selenium jcchouinard.com')
time.sleep(1)
# Simulate pressing ENTER
search_box.submit()
time.sleep(1)
# Get first element
first_result = driver.find_element(By.XPATH,'//*[@id="rso"]/div[1]/div/div/div[1]/div/div/div[1]/div/a/h3')
# Click On The Link
first_result.click()
time.sleep(3)
Automate Your Web Scraping Script
To automate the web scraping, schedule your python script on Windows task scheduler, or automate python script using CRON on Mac.
Selenium VS Requests for Web Scraping
While python requests is much more efficient in computational cost for both the client and the server, Selenium offers the capacity to render a web page before interacting with it. Thus, the Selenium framework is better than the Python HTTP requests library for projects where JavaScript needs to be executed.
However, Python requests is better for speed and efficiency when the project does not require to render the web page such as interacting with APIs, making head requests or fetching relatively simple HTML pages.
Articles Related to Web Scraping
Conclusion
Enjoyed this post? Tell me how you automate your SEO using Selenium webdriver and Python.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.