In this tutorial, we will use the Python Requests library in order to fetch data from the Wikidata API.
We will learn in detail how the Wikidata API works and how to gather important data from the “Google LLC” Wikidata page using Python.
What is the Wikidata API?
The Wikidata API is an Application Programming Interface use to query the Wikidata Knowledge Base.
Wikidata API VS Wikipedia API
While the Wikipedia API allows you to query the content that you find on the actual Wikipedia page, the Wikidata API allows you to query the data behind that is used to build content across the MediaWiki organisation (wikitravel, wikipedia, wikispecies, etc.).
So, with the Wikidata API, you can, in a way query the Wikipedia content, but with wikipedia, you may not be able to query some of the data in wikidata.
Requests VS API Wrappers
Many tutorials on the Web will the you to install Python wrapper APIs such as mkwikidata or pywikibot, but I always prefer to use requests to fetch the API endpoint myself as the learning curve is a lot smaller and it does not rely on libraries that install lots of things that you don’t need.
What you Will Learn
In this tutorial, you will learn to use Python fetch some of the information that I deem Important within Wikidata, using its API.
How the Wikidata API works?
The Wikidata API is an Open API that allows you to query its data by fetching the following endpoint.
https://www.wikidata.org/w/api.php
To this endpoint, parameters can be added to the request to tell which data is required and in which format. Parameters are all the element after the question mark (?) and separated by ands (&) in the URL.
For example, if you open the following URL in your browser, you will have fetched the Wikidata API.
https://www.wikidata.org/w/api.php?action=wbsearchentities&format=json&search=Google&language=en
The result of the API was returned to you in a JSON format that can be parsed to get the underlying data.

Wikidata API Sandbox
To practice with the Wikidata API you can use Python or the Wikidata API sandbox that provides a user interface to make requests to the API.
Wikidata Actions
The Wikidata action parameter is used to define what action that you want the API to do. The action that you chose will influence the way the data can be queried.
The two main actions covered in this tutorial are:
- wbsearchentities
- wbgetentities
But there are many more possible actions…
Wbsearchentities
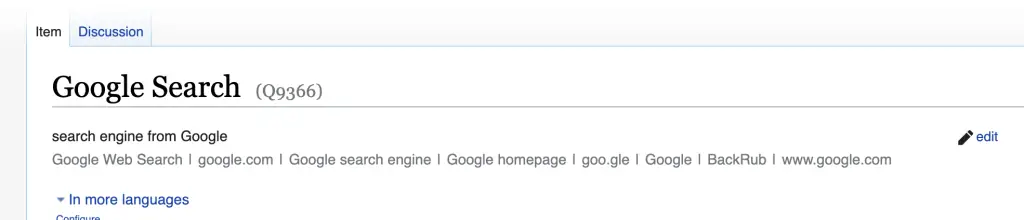
The wbsearchentities searches for entities using labels and aliases. This helps you to discover the entity ID using free text.
For example, using the search term “Google” to find that it’s entity ID is Q9366.
Wbgetentities
The wbgetentities action helps you get the data for the Wikibase entities for which you know the ID.
This helps you query all the data available for a given wikidata ID.
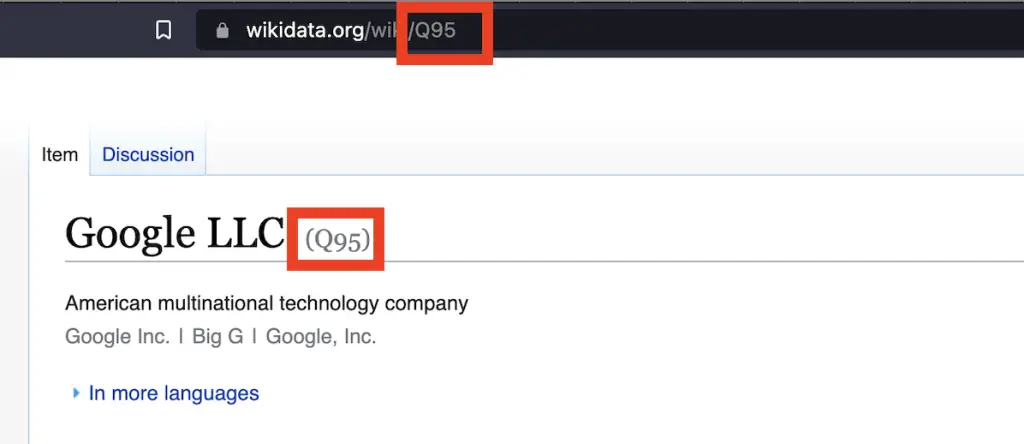
The wikidata ID is either found with the Wbsearchentities API, or in the URL or the title of the Wikidata page.
How to Use the Wikidata API with Python
Now, I will showcase an example of how one can query the important data from the Wikidata API using Python by attempting to get info from the Google LLC wikidata page.
Make a Function to Fetch the API
This function uses the Python requests library to fetch the wikidata endpoint.
The params argument will be provided in the next step and will add the parameters (after the ? in the URL) to the endpoint URL.
Just think of the URL you copied and pasted in the browser earlier.
The try and except keywords are used to prevent the code from breaking in case there is an error with the request.
import requests
def fetch_wikidata(params):
url = 'https://www.wikidata.org/w/api.php'
try:
return requests.get(url, params=params)
except:
return 'There was and error'
Fetch wbsearchentities to Get the Entity ID
We can’t fetch all the wikidata content if we don’t know the ID that we want to fetch.
Thus, we need to use wbsearchentities to get the ID.
To do so, we will create a Python dictionary with the required parameters to be added to the URL. Each key, value of the dictionary will be a parameter (separated by &s in the URL).
# What text to search for
query = 'Google LLC'
# Which parameters to use
params = {
'action': 'wbsearchentities',
'format': 'json',
'search': query,
'language': 'en'
}
# Fetch API
data = fetch_wikidata(params)
#show response as JSON
data = data.json()
data
It will return something like this.
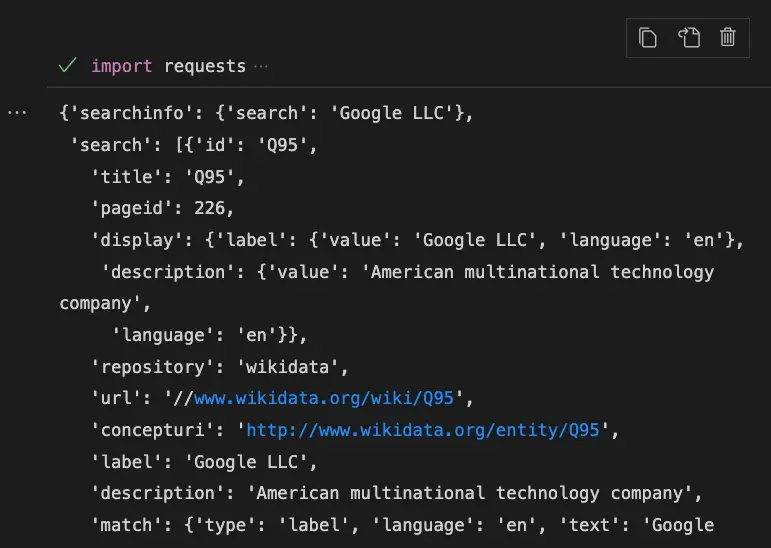
Parse the Wikidata search JSON
The search API will return a JSON with three main blocks that you can view by using data.keys():
- searchinfo: what you searched for
- search: result of your search
- success: whether your query worked
Within the search block, you will get a list of items that satisfies your search (search results) that you can select with its index.
data['search'][0] # select first search result
data['search'][1] # select second search result
For each item, you can select informations such as the title, the id and the language.
data['search'][0]['id'] # select first search result ID
# 'Q95'
This is the ID that we need in order to query the API using the wbgetentities action.
Alternatively, you can loop through the results to get all of them:
for elem in data['search']:
print(elem['id'])
Fetch wbgetentities to Get the Entity Data
The wbgetentities will allow you to fetch data fro one or multiple entities.
When fetching multiple item, separate each item with the (|) symbol.
params = {
'action': 'wbgetentities',
'ids': 'id1|id2|id3',
'format': 'json',
'languages': 'en'
}
Here I will fetch the Google LLC ID that we had from the previous response.
# Get ID from the wbsearchentities response
id = data['search'][0]['id']
# Create parameters
params = {
'action': 'wbgetentities',
'ids':id,
'format': 'json',
'languages': 'en'
}
# fetch the API
data = fetch_wikidata(params)
# Show response
data = data.json()
data
Output:
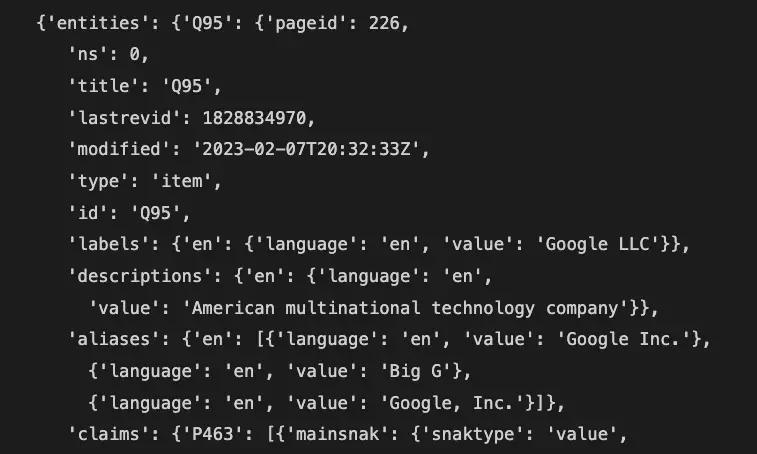
Parse the Get Entities Response
Now, to parse this response require some investigation work. You can explore the JSON response by using methods such as:
object.keys() # Show keys of the object
object[key_name] # Show values of the object key
One thing to bear in mind is that the claims key lists elements using the P123 format.
Here is an example:
data['entities'][id]['claims'].keys()
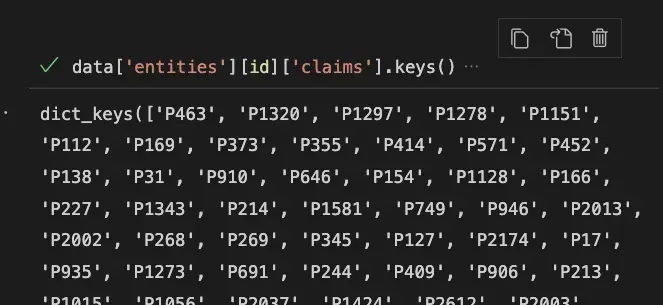
This ID is the Property ID that you can view by hovering over individual links in Wikidata.

By selecting the Property ID, you can get the elements that you see on the right.
data['entities'][id]['claims']['P361']
Because there is a single “part of” element that is “Big Tech”, there is only one when selecting the “part of” ID (P361).
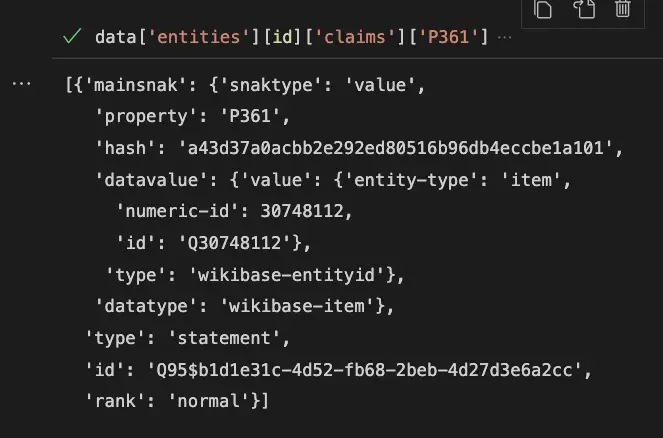
And, the ID of there”Big Tech” element is the same as the one that you see in the response above.

You would select all the “Part of” elements by using this list comprehension selection.
[v['mainsnak']['datavalue']['value']['id'] for v in data['entities'][id]['claims']['P361']]

Extracting the Most Useful Information
I will not go into the detail of each, but they all are parsed in similar matter.
I will however, give you the work for free my friends.
try:
title = data['entities'][id]['labels']['en']['value']
except:
title = 'not_found'
try:
alternate_names = [v['value'] for v in data['entities'][id]['aliases']['en']]
except:
alternate_names = 'not_found'
try:
description = data['entities'][id]['descriptions']['en']['value']
except:
description = 'not_found'
try:
twitter = data['entities'][id]['claims']['P2002'][0]['mainsnak']['datavalue']['value']
except:
twitter = 'not_found'
try:
facebook = data['entities'][id]['claims']['P2013'][0]['mainsnak']['datavalue']['value']
except:
facebook = 'not_found'
try:
linkedin = data['entities'][id]['claims']['P4264'][0]['mainsnak']['datavalue']['value']
except:
linkedin = 'not_found'
try:
youtube = data['entities'][id]['claims']['P2397'][0]['mainsnak']['datavalue']['value']
except:
youtube = 'not_found'
try:
instagram = data['entities'][id]['claims']['P2003'][0]['mainsnak']['datavalue']['value']
except:
instagram = 'not_found'
try:
subreddit = data['entities'][id]['claims']['P3984'][0]['mainsnak']['datavalue']['value']
except:
subreddit = 'not_found'
try:
instance_of = [v['mainsnak']['datavalue']['value']['numeric-id'] for v in data['entities'][id]['claims']['P31']]
except:
instance_of = 'not_found'
try:
part_of = [v['mainsnak']['datavalue']['value']['id'] for v in data['entities'][id]['claims']['P361']]
except:
part_of = 'not_found'
try:
founded_by = [v['mainsnak']['datavalue']['value']['numeric-id'] for v in data['entities'][id]['claims']['P112']]
except:
founded_by = 'not_found'
try:
nick_names = [v['mainsnak']['datavalue']['value']['text'] for v in data['entities'][id]['claims']['P1449']]
except:
nick_names = 'not_found'
try:
official_websites = [v['mainsnak']['datavalue']['value']for v in data['entities'][id]['claims']['P856']]
except:
official_websites = 'not_found'
try:
categories = [v['mainsnak']['datavalue']['value']['numeric-id'] for v in data['entities'][id]['claims']['P910']]
except:
categories = 'not_found'
try:
inception = data['entities'][id]['claims']['P571'][0]['mainsnak']['datavalue']['value']['time']
except:
inception = 'not_found'
try:
latitude = data['entities'][id]['claims']['P625'][0]['mainsnak']['datavalue']['value']['latitude']
longitude = data['entities'][id]['claims']['P625'][0]['mainsnak']['datavalue']['value']['longitude']
except:
latitude = 'not_found'
longitude = 'not_found'
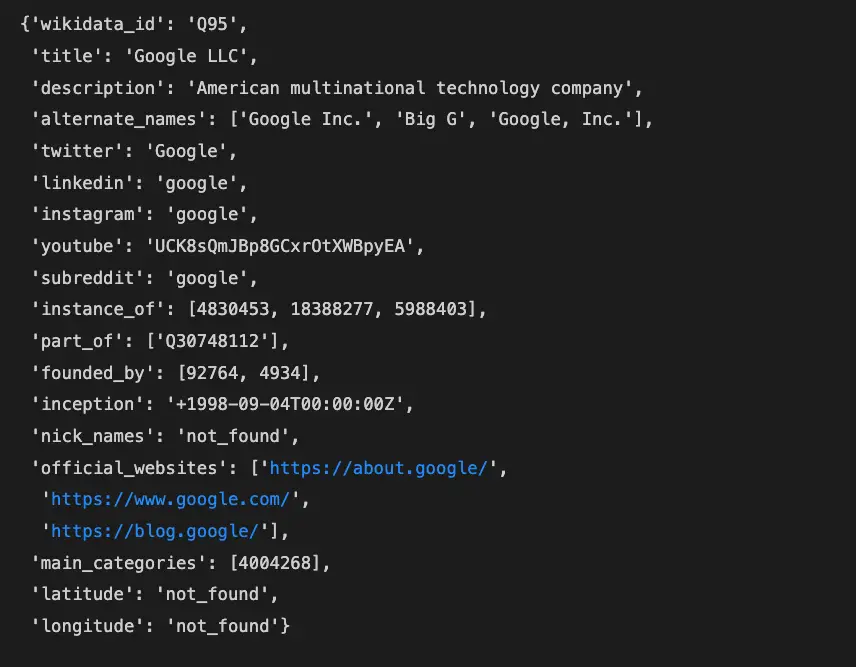
result = {
'wikidata_id':id,
'title':title,
'description':description,
'alternate_names':alternate_names,
'twitter':twitter,
'linkedin':linkedin,
'instagram':instagram,
'youtube':youtube,
'subreddit':subreddit,
'instance_of':instance_of,
'part_of':part_of,
'founded_by':founded_by,
'inception':inception,
'nick_names':nick_names,
'official_websites':official_websites,
'main_categories':categories,
'latitude':latitude,
'longitude':longitude
}
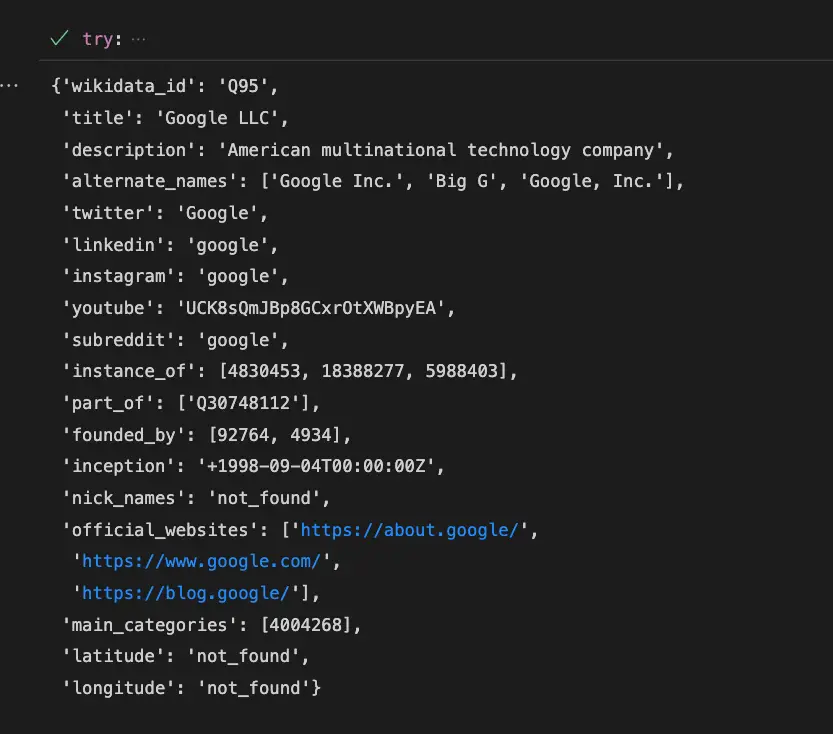
result
The result is the image shared at the beginning of the post.
Conclusion
We now have covered everything there is to know to get started with the Wikidata API with Python. Congratulations.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.