In this tutorial, you will learn what Xpath is and how to leverage Xpath in web scraping.
XPath allows you to locate exact elements within an HTML document. It is also supported by most web scraping tools, making it a super useful tool for web scraping.
Navigation
Show
What is Xpath
Xpath, or XML Path Language, is a query language that can be used to access different elements and attributes of an XML or an HTML document.
The Xpath notation is used to navigate nodes in a path like syntax and using conditions to extract specific information.
Why Xpath is Useful in Web Scraping
XPath is very useful in web scraping. Xpath allows you to:
- locate the element you want to extract from a webpage,
- identify and extract data from HTML and XML documents quickly.
- automate the scraping of webpages.
Simplest Way to Find the XPath in Chrome
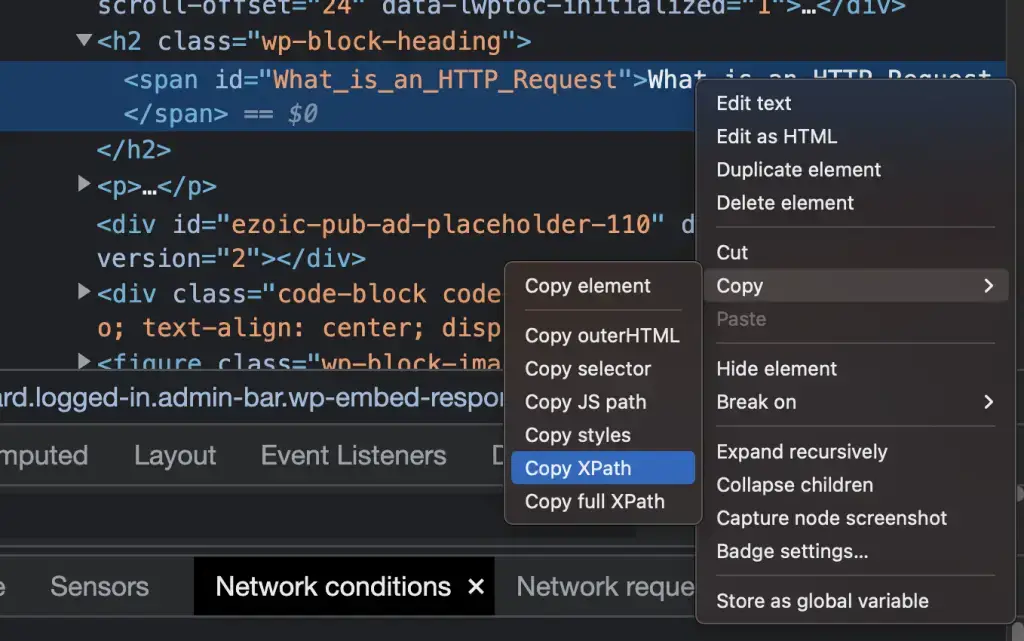
Chrome DevTools as an incredible feature that allows you to find the XPath of any DOM element without any prior knowledge.
Open Chrome DevTool with Command + Shift + I, or by using right-click > inspect.
Then right click on any element in the DOM and select Copy > Copy XPath.
Basics of XPath Expressions
Xpath expressions are strings used to describe the location of an element (node), or multiple elements, within an HTML (or XML) document.
For example, the xpath below locates the h1, found within the HTML body element:
//html/body/h1
Basic Structure of the XPath Expression
The basic structure of an XPath expression is similar to the structure used to navigate a URL.
The XPath expression is represented by a series of steps. Each step is separated by forward slashes (/), which moves forward one generation.
Each step contains any of these elements:
- element name: html, body, div, etc.,
- attribute name: id, class, href, etc.,
- function call: text(), count(), etc.,
- wildcard character: *.
Brackets ([]) can be used after a tag name to define which sibling should be chosen.
Take the Xpath expression below shows how to select the first div of the body element.
//html/body/div[1]
Unlike Python that uses zero-based indexing, the index in XPath starts at 1.

- The double-slash “
//” means to look at all the elements within the HTML code. - the
html/body/divshows the path from the root to the tag we want to select
XPath Wildcards
XPath wildcards are special characters used to match one or multiple elements and attributes in markup documents. The two main wildcards used in XPath expressions are:
- double slash (//)
- the asterisk (*)
Double-Slash (//)
The double-slash is a wildcard that can be used to find all future generations of elements within the entire HTML. It is useful to find relative path.
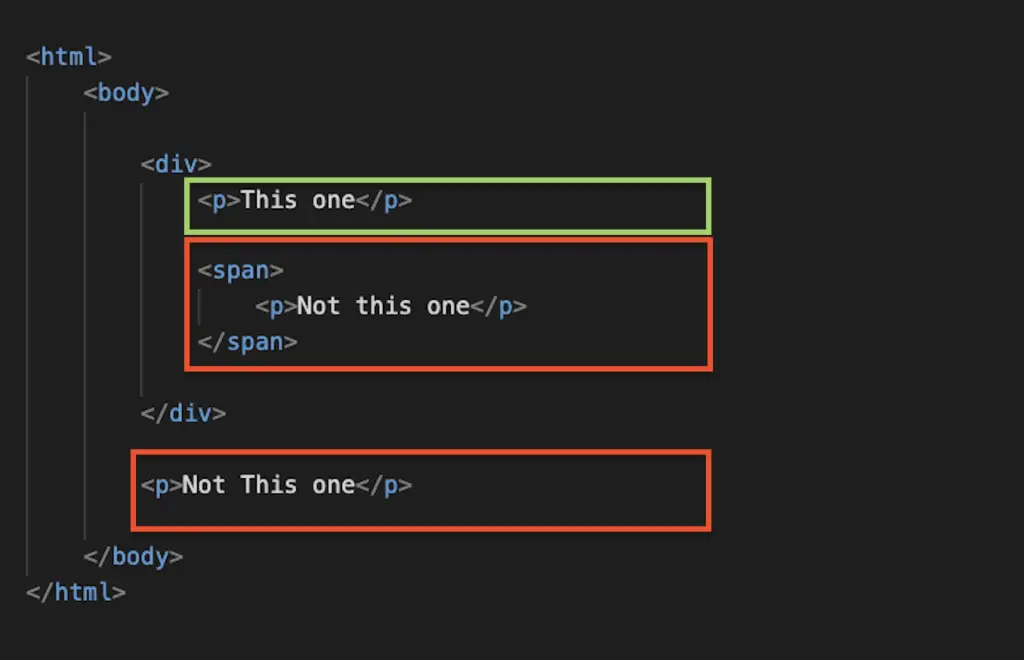
For example, this XPath would selects all the <p> tags within a div.
//html/body/div/p
Any <p> tag outside of a div, or inside a tag within a div would be excluded:
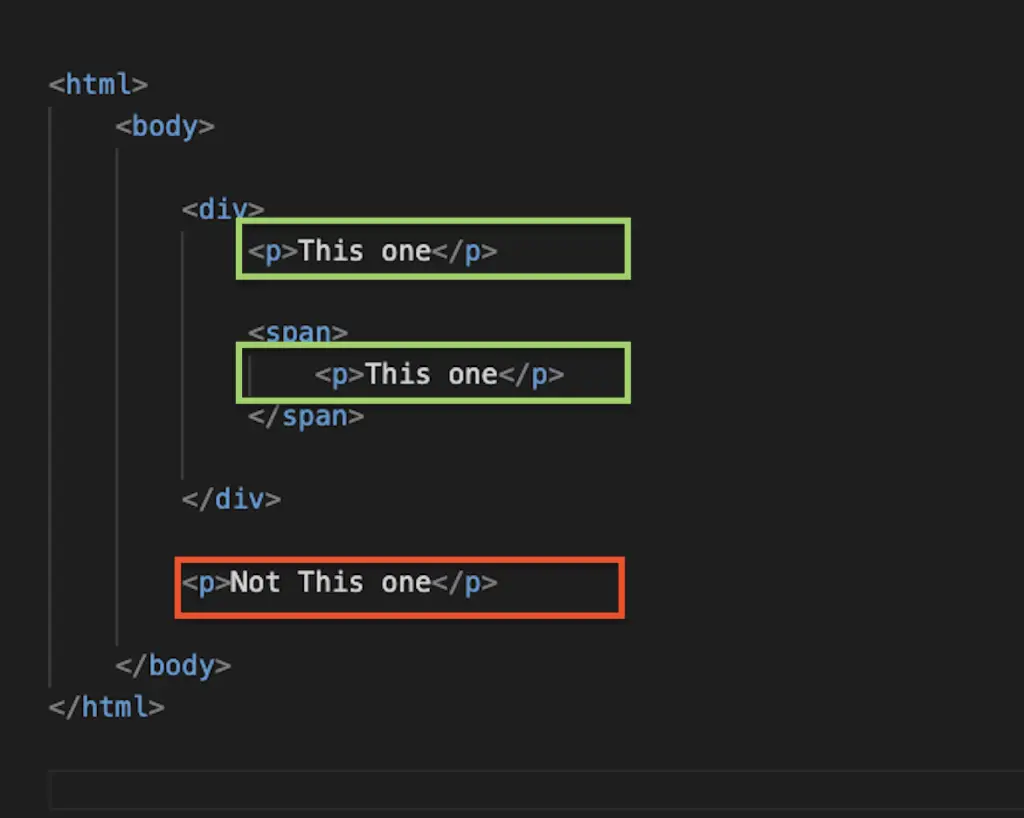
You could work around that using the double-slash. The notation below would select any <p> tag within the HTML.
//p
Alternatively, you can restrict to a specific element. For instance, select all the <p> tags that are within a div:
//html/body/div//p
Asterisk (*)
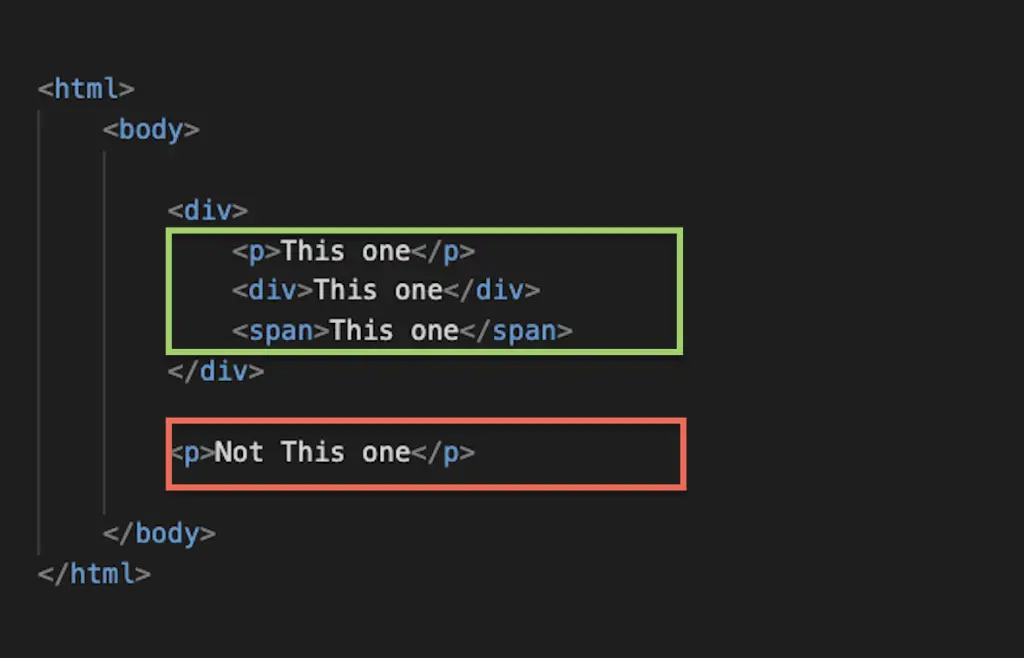
The asterisk is a wild card that can be used in XPath to match any element node HTML (or XML) document. For example, you can use the asterisk to select all the children of an element:
//html/body/div/*
Xpath Operators
You can used logical and comparison operators in XPath expressions.
- logical operators: and, or,
- comparison operators: =, <, >
Using these operators, you can be start creating more complex XPath expressions.
Logical Operators
Logical operators like “and” and “or” can be used to select elements that satisfy certain conditions.
For example, if you have a div with 4 paragraphs and want to select the 1st and the last.
<div>
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<p>Paragraph 3</p>
<p>Paragraph 4</p>
</div>
You could use the “and” logical operator in XPath to combine the expressions.
The position() function call just checks the position of the selected node. We’ll learn more about function calls later in the tutorial.
//div/p[position()=1 and position()=4]
Comparison Operators
Comparison operators like “=”, “>” and “<” can be used to select elements that satisfy certain conditions.
Using the same structure of paragraph as above, you could select element for which the position is above 3:
//div/p[position() > 3]
Selecting Attributes in XPath
To select the attribute of an HTML or XML tag, you can use the @ symbol in XPath.
- @id: select tag id
- @class: select class id
- @href: select href attribute.
- etc.
This example shows how to use the square brackets notation to select the attributes of a tag.
//html/body/div[@class='content']
This expression selects all the <div> HTML tags that have a class attribute with “content” as its value.

The “@class='content'” is the attribute value of the div tag. The @ represents “attribute”.
Xpath Functions
XPath has various functions that can be used to further enhance node navigation. Let’s check out some of the important function calls you can use in XPath
- text()
- contains(@attribute-name, “expression”)
- count()
- starts-with()
- etc.
Text()
The text() function selects the text of an element. For example, the following XPath expression would return the entire HTML block.
//h1
Output:
<h1>My Title</h1>
Using the text function allows you to select only the text of the HTML element.
//h1/text()
Output:
My Title
Contains()
The contains() function checks if a the element contains a specified substring and uses this format:
contains(@attribute-name, "expression")
For example, to select all the elements that contain a string, e.g. all the links whose href attribute contains the string “contact”
//a[contains(@href, 'contact')]
Count()
The count() function allows you to count the nodes that match your XPath expression.
For example, you can count the number of links on the page:
count(//a)
Starts-with()
The starts-with() function checks if a string starts with something.
For example, you can extract any <div> element for which the class starts with the string “this”.
//div[starts-with(@class, 'this')]
Python Scraping XPath with Scrapy
Scrapy allows you to scrape content using XPath with the xpath() method from the Selector class.
from scrapy import Selector
html = '''<html>
<head>
<title>Title of your web page</title>
</head>
<body>
<h1>Heading of the page</h1>
<p id="first-paragraph" class="paragraph">Paragraph of text</p>
<p class="paragraph">Paragraph of text 2</p>
<div><p class="paragraph">Nested paragraph</p></div>
<a href="/a-link">hyperlink</a>
</body>
</html>'''
# Instantiate Selector
sel = Selector(text=html)
sel.xpath('//h1/text()').extract()
['Heading of the page']
Top 50 Most Used XPath Notations in Web Scraping
//– Selects nodes in the document from the current node that match the selection no matter where they are*– Selects all child nodes of the current node@– Selects attributes of the current node..– Selects the parent of the current node.– Selects the current node//tagname– Selects all nodes with the specified tagname//tagname[@attribute='value']– Selects all nodes with the specified tagname and attribute value//tagname[contains(@attribute,'value')]– Selects all nodes with the specified tagname and attribute containing the specified value//tagname[@attribute1='value1' and @attribute2='value2']– Selects all nodes with the specified tagname and multiple attributes//tagname[position()=1]– Selects the first occurrence of the specified tagname//tagname[last()]– Selects the last occurrence of the specified tagname//tagname[position()>1]– Selects all occurrences of the specified tagname except the first one//tagname[@attribute1='value1'][@attribute2='value2']– Selects all nodes with the specified tagname and both attributes//tagname[@attribute1='value1' or @attribute2='value2']– Selects all nodes with the specified tagname and either attribute//tagname[starts-with(@attribute,'value')]– Selects all nodes with the specified tagname and attribute starting with the specified value//tagname[ends-with(@attribute,'value')]– Selects all nodes with the specified tagname and attribute ending with the specified value//tagname[substring(@attribute,start,length)='value']– Selects all nodes with the specified tagname and attribute substring matching the specified value//tagname/text()– Selects the text content of all nodes with the specified tagname//tagname[@attribute]/text()– Selects the text content of all nodes with the specified tagname and attribute//tagname[@attribute='value']/text()– Selects the text content of all nodes with the specified tagname and attribute value//tagname/following-sibling::siblingtagname– Selects all siblings after the current node with the specified sibling tagname//tagname/preceding-sibling::siblingtagname– Selects all siblings before the current node with the specified sibling tagname//tagname/child::childtagname– Selects all child nodes of the specified tagname with the specified child tagname//tagname/descendant::descendanttagname– Selects all descendant nodes of the specified tagname with the specified descendant tagname//tagname/ancestor::ancestortagname– Selects all ancestor nodes of the specified tagname with the specified ancestor tagname//tagname[count(child::*)=0]– Selects all nodes with the specified tagname that have no child nodes//tagname[count(child::*)>0]– Selects all nodes with the specified tagname that have at least one child node//tagname[count(attribute::*)=0]– Selects all nodes with the specified tagname that have no attributes//tagname[count(attribute::*)>0]– Selects all nodes with the specified tagname that have at least one attribute//tagname[not(tagname2)]– Selects all nodes with the specified tagname that do not have the specified tagname2 as a child node//tagname[not(attribute)]– Selects all nodes with the specified tagname that do not have any attributes//tagname[not(@attribute='value')]– Selects all nodes with the specified tagname that do not have the specified attribute value//tagname[position() mod 2 = 0]– Selects all even-indexed nodes with the specified tagname//tagname[position() mod 2 = 1]– Selects all odd-indexed nodes with the specified tagname//tagname[position() < n]– Selects the first n occurrences of nodes with the specified tagname//tagname[position() > n]– Selects all occurrences of nodes with the specified tagname after the first n occurrences//tagname[@attribute][1]– Selects the first occurrence of nodes with the specified tagname and attribute//tagname[@attribute][last()]– Selects the last occurrence of nodes with the specified tagname and attribute//tagname[@attribute][position()=n]– Selects the nth occurrence of nodes with the specified tagname and attribute//tagname[@attribute][position()=last()-n+1]– Selects the nth to last occurrence of nodes with the specified tagname and attribute//tagname[position()=1]/following::siblingtagname[1]– Selects the first occurrence of the specified sibling tagname following the first occurrence of the specified tagname//tagname[position()=1]/following::siblingtagname[position()<n+1]– Selects the first n occurrences of the specified sibling tagname following the first occurrence of the specified tagname//tagname[position()=1]/following::siblingtagname[position()>n-1]– Selects all occurrences of the specified sibling tagname after the first n occurrences following the first occurrence of the specified tagname//tagname[contains(text(),'value')]– Selects all nodes with the specified tagname containing the specified text value//tagname[starts-with(text(),'value')]– Selects all nodes with the specified tagname starting with the specified text value//tagname[ends-with(text(),'value')]– Selects all nodes with the specified tagname ending with the specified text value//tagname[matches(text(),'pattern')]– Selects all nodes with the specified tagname matching the specified regular expression pattern in the text content//tagname[contains(translate(@attribute,'ABCDEFGHIJKLMNOPQRSTUVWXYZ','abcdefghijklmnopqrstuvwxyz'),'value')]– Selects all nodes with the specified tagname containing the specified case-insensitive attribute value//tagname[translate(@attribute,'ABCDEFGHIJKLMNOPQRSTUVWXYZ','abcdefghijklmnopqrstuvwxyz')='value']– Selects all nodes with the specified tagname having the specified case-insensitive attribute value//tagname[translate(text(),'ABCDEFGHIJKLMNOPQRSTUVWXYZ','abcdefghijklmnopqrstuvwxyz')='value']– Selects all nodes with the specified tagname
CSS Selector to XPath Conversion
| Equivalency | XPath Notation | CSS Selector |
|---|---|---|
| Select by element type | //div | div |
| Select by class name | //div[@class=”example”] | div.example |
| Select by ID | //*[@id=”example”] | #example |
| Select by attribute | //input[@name=”example”] | input[name=”example”] |
| Select by attribute value containing | //input[contains(@class, “example”)] | input[class*=”example”] |
| Select by attribute value starting with | //input[starts-with(@id, “example”)] | input[id^=”example”] |
| Select by attribute value ending with | //a[ends-with(@href, “example”)] | a[href$=”example”] |
| Select by sibling | //div/following-sibling::p | div + p |
| Select by descendant | //div//p | div p |
| Select by first child | //div/p[1] | div > p:first-child |
| Select by last child | //div/p[last()] | div > p:last-child |
Articles Related to Web Scraping
Conclusion
This is it we now have covered everything that you need to know about XPath in Web Scraping.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.