
A headless browser is a web browser without a graphical user interface (GUI). Simply put, it is an invisible browser that runs in the background without you seeing it (headless mode).
Headless browsers provide automated control of the web browser from the command-line interface or network communication, with or without the use of a web browser framework. It is often used to perform automated UI tests in a faster way, when JavaScript needs to be executed or to prevent web scraping from being detected.
The first headless web browser, PhantomJS, was created by Ariya Hidayat in 2011. Since then, other headless browsers such as Headless Chrome and Headless Firefox were developed.
This article was written in partnership with Manthan Koolwal, founder of Scrapingdog
Why use a Headless Browser?
Headless browsers are often used to automate tasks that require web browsers (e.g. website testing, web scraping, etc.). Headless browsers can be used to:
- Perform automated tests on a website
- Perform web scraping with JavaScript Enabled
- Perform web scraping undetected.

Now, why would you use this headless browser for scraping instead of making the traditional XHR request? Well, many modern websites use JavaScript to load and display content dynamically. Headless browsers can execute JavaScript, allowing them to render and process pages just like a regular browser. If a website heavily relies on JavaScript to load content, a headless browser ensures that you capture the fully rendered page.
Headless Browser Frameworks (Examples)
According to Google trends, the most popular headless browser framework is Selenium. The most common headless browser frameworks are:
- Selenium Headless Browser
- Puppeteer Headless Browser
- Playwright Headless Browser
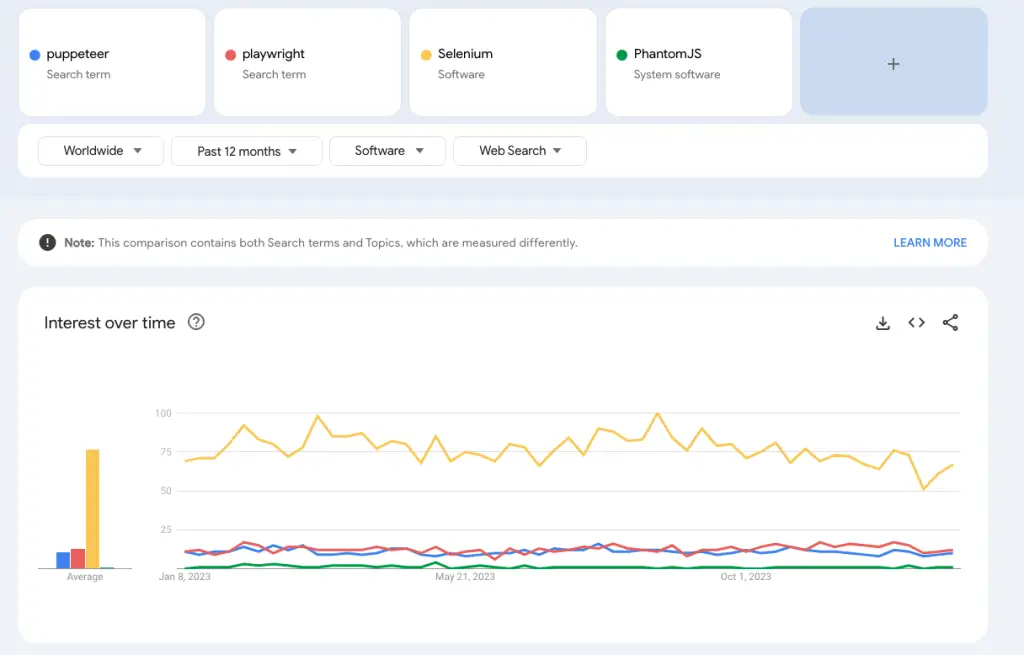
They are frameworks that developers use to control headless browsers. These tools allow to perform automated actions, tests and data scraping for example.
Headless Browsers in Web Scraping
Headless browsers are useful in web scraping. Some websites use anti-scraping measures that can detect and block requests coming from automated scripts. Headless browsers can emulate human-like behaviour, making it harder for websites to distinguish between scraping bots and genuine users. This is another advantage of using the headless browser for scraping.
Since there is no GUI, the resources consumed by the browser will be much less while scraping any website at scale. You can run multiple instances of the browser without worrying about the CPU usage.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.