WGET is a free tool to crawl websites and download files via the command line.
In this wget tutorial, we will learn how to install and how to use wget commands with examples.
Navigation Show
What is Wget?
Wget is free command-line tool created by the GNU Project that is used todownload files from the internet.
- It lets you download files from the internet via FTP, HTTP or HTTPS (web pages, pdf, xml sitemaps, etc.).
- It provides recursive downloads, which means that Wget downloads the requested document, then the documents linked from that document, and then the next, etc.
- It follows the links and directory structure.
- It lets you overwrite the links with the correct domain, helping you create mirrors of websites.
What Is the Wget Command?
The wget command is a tool developed by the GNU Project to download files from the web. Wget allows you to retrieve content and files from web servers using a command-line interface. The name “wget” comes from “World Wide Web” and “get”. Wget supports downloads via FTP, SFTP, HTTP, and HTTPS protocols.
Wget is used by developers to automate file downloads.
Install Wget
To install wget on Windows, install the executable file from eternallybored.org. To install wget on Mac, use the brew install wget command on Mac. Make sure that it is not already installed first by running the wget -V command in the command line interface. For more details on how to install Wget, read one of the following tutorials.
Downloading Files From the Command Line (Wget Basics)
Let’s look at the wget syntax, view the basic commands structure and understand the most important options.
Wget Syntax
Wget has two arguments: [OPTION] and [URL] .
wget [OPTION]... [URL]...
- [OPTION] tells what to do with the [URL] argument provided after. It has a short and a long-form (ex:
-Vand--versionare doing the same thing). - [URL] is the file or the directory you wish to download.
- You can call many OPTIONS or URLs at once.
View WGET Arguments
To view available wget Arguments, use the wget help command:
wget -h
The output will show you an exhaustive list of all the wget command parameters.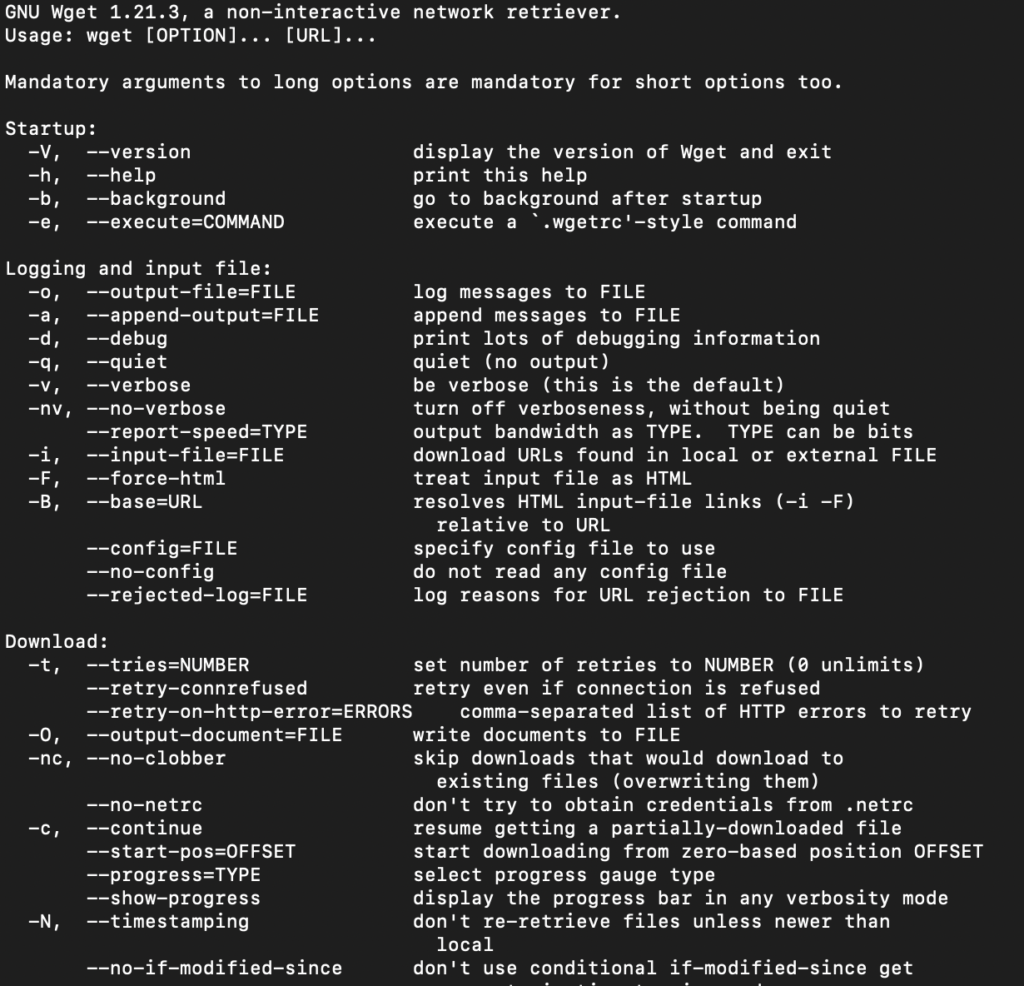
14 Wget Examples to Extract Web Pages
Here are the 11 best things that you can do with Wget:
- Download a single file
- Download a files to a specific directory
- Rename a downloaded files
- Define User Agent
- Extract as Googlebot
- Extract Robots.txt when it changes
- Convert links on a page
- Mirror a single page
- Extract Multiple URLs from a list
- Limit Speed
- Number of attempts
- Use Proxies
- Continue Interrupted Downloads
- Extract Entire Website
Download a single file with Wget
$ wget https://example.com/robots.txt
Download a File to a Specific Output Directory
Here replace <YOUR-PATH> by the output directory location where you want to save the file.
$ wget ‐P <YOUR-PATH> https://example.com/sitemap.xml
Rename Downloaded File when Retrieving with Wget
To output the file with a different name:
$ wget -O <YOUR-FILENAME.html> https://example.com/file.html
Define User Agent in WGET
Identify yourself. Define your user-agent.
$ wget --user-agent=Chrome https://example.com/file.html
Extract as Googlebot with Wget Command
$ wget --user-agent="Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://example.com/path
Use Wget to Extract Robots.txt When it Changes
Let’s extract robots.txt only if the latest version in the server is more recent than the local copy.
First time that you extract use -S to keep a timestamps of the file.
$ wget -S https://example.com/robots.txt
Later, to check if the robots.txt file has changed, and download it if it has.
$ wget -N https://example.com/robots.txt
Wget command to Convert Links on a Page
Convert the links in the HTML so they still work in your local version. (ex: example.com/path to localhost:8000/path)
$ wget --convert-links https://example.com/path
Mirror a Single Webpage in Wget
To mirror a single web page so that it can work on your local.
$ wget -E -H -k -K -p --convert-links https://example.com/path
Extract Multiple URLs with Wget
Add all urls in a urls.txt file.
https://example.com/1
https://example.com/2
https://example.com/3
$ wget -i urls.txt
Limit Speed of Extraction in Wget
To be a good citizen of the web, it is important not to crawl too fast by using --wait and --limit-rate.
--wait=1: Wait 1 second between extractions.--limit-rate=10K: Limit the download speed (bytes per second)
Define Number of Retry Attempts in Wget
Sometimes the internet connection fails, sometimes the attempts it blocked, sometimes the server does not respond. Define a number of attempts with the -tries function.
$ wget -tries=10 https://example.com
How to Use Proxies With Wget?
To set a proxy with Wget, we need to update the ~/.wgetrc file located at /etc/wgetrc.
You can modify the ~/.wgetrc in your favourite text editor.
$ vi ~/.wgetrc # VI
$ code ~/.wgetrc # VSCode
And add these lines to the wget parameters:
use_proxy = on
http_proxy = http://username:password@proxy.server.address:port/
https_proxy = http://username:password@proxy.server.address:port/
Then, by running any wget command, you’ll be using proxies.
Alternatively, you can use the -e command to run wget with proxies without changing the environment variables.
wget -e use_proxy=yes -e http_proxy=http://proxy.server.address:port/ https://example.com
How to remove the Wget proxies?
When you don’t want to use the proxies anymore, update the ~/.wgetrc to remove the lines that you added or simply use the command below to override them:
$ wget --noproxy
Continue Interrupted Downloads with Wget
When your retrieval process is interrupted, continue the download with restarting the whole extraction using the -c command.
$ wget -c https://example.com
Using Wget to Extract an Entire Site (Proceed with Caution)
Recursive mode extract a page, and follows the links on the pages to extract them as well.
This is extracting your entire site and can put extra load on your server. Be sure that you know what you do or that you involve the devs.
$ wget --recursive --page-requisites --adjust-extension --span-hosts --wait=1 --limit-rate=10K --convert-links --restrict-file-names=windows --no-clobber --domains example.com --no-parent example.com
| Command | What it does |
|---|---|
| –recursive | Follow links in the document. The maximum depth is 5. |
| –page-requisites | Get all assets (CSS/JS/images) |
| –adjust-extension | Save files with .html at the end. |
| –span-hosts | Include necessary assets from offsite as well. |
| –wait=1 | Wait 1 second between extractions. |
| –limit-rate=10K | Limit the download speed (bytes per second) |
| –convert-links | Convert the links in the HTML so they still work in your local version. |
| –restrict-file-names=windows | Modify filenames to work in Windows. |
| –no-clobber | Overwrite existing files. |
| –domains example.com | Do not follow links outside this domain. |
| –no-parent | Do not ever ascend to the parent directory when retrieving recursively |
| –level | Specify the depth of crawling. |
(Extra) Run Spider Mode
$ wget --spider -r https://example.com -o wget.log
Wget VS Curl
Wget’s strength compared to curl is its ability to download recursively. This means that it will download a document, then follow the links and then download those documents as well.
Use Wget With Python
Wget is strictly command line, but there is a package that you can import the wget package that mimics wget.
import wget
url = 'http://www.jcchouinard.com/robots.txt'
filename = wget.download(url)
filename
Debugging: What to Do When Wget is Not Working
Wget Command Not Found
If you get the -bash: wget: command not found error on Mac, Linux or Windows, it means that the wget GNU is either not installed or does not work properly.
Go back and make sure that you installed wget properly.
Wget is not recognized as an internal or external command
If you get the following error
'wget' is not recognized as an internal or external command, operable program or batch file
It is more than likely that the wget package was not installed on Windows. Fix the error by installing wget first and then start over using the command.
Otherwise, it may also mean that the wget command is not not found in your system’s PATH.
Adding Wget to the System’s Path (Windows)
Adding the wget command to the system’s path will allow you to run wget from anywhere.
To add wget to the Windows System ‘s Path you need to copy the wget.exe file to the right directory.
- Download the wget file for Windows
- Press
Windows + Eto open File Explorer. - Find where you downloaded
wget.exe(e.g. Downloads folder) - Copy the
wget.exefile - Paste into the System Directory (System32 is already in your system’s path)
- Go to
C:\Windows\System32. - Paste your
wget.exefile into your System32 folder
- Go to
wget: missing URL
The “wget: missing URL” error message occurs when you run the wget command without providing a URL to download.
One of the use cases that I have seen this is when users used flags without the proper casing.
$ wget -v
# wget: missing URL
Above the casing of the v flag should not be lowercase, but uppercase.
$ wget -V
# No error
Or use the verbose way of calling it with the double-dash and full name.
$ wget --version
# No error
Alternatives to Wget on Mac and Windows
You can use cURL as an alternative of Wget command line tool. It also has to be installed on Mac, Linux and Windows.
Wget for Web Scraping
By allowing you to download files from the Internet, the wget command-line tool is incredibly useful in web scraping. It has a set of useful features that make web scraping easy:
- Batch Downloading:
wgetallows you to download multiple files or web pages in a single command. - Recursive Downloading: the
--recursiveflag inwgetallows you to follow links and download an entire website - Retries:
wgetis designed to handle unstable network connections and interruptions and retry failed extractions - Command-line options: Options are available to improve scraping capabilities (download speed, User-Agent headers, cookies for authentication, etc.).
- Header and User-Agent Spoofing: To avoid being blocked by websites when web scraping,
wgetallows you to change the User-Agent header to make your requests appear more regular users. - Limiting Server Load: By using the
--waitand--limit-rateoptions, you can control the speed at whichwgetfetches data.
About Wget
| Wget was developed by | Hrvoje Nikšić |
| Wget is Maintained by | Tim Rühsen and al. |
| Wget Supported Protocols | HTTP(S), FTP(S) |
| Wget was Created In | January 1996 |
| Installing Wget | brew install wget |
| Wget Command | wget [option]…[URL]… |
Wget FAQs
What is Wget Used For?
Wget is used to download files from the Internet without the use of a browser. It supports HTTP, HTTPS, and FTP protocols, as well as retrieval through HTTP proxies.
How Does Wget Work?
Wget is non-interactive and allows to download files from the internet in the background without the need of a browser or user interface. It works by following links to create local versions of remote web sites, while respecting robots.txt.
What is the Difference Between Wget and cURL?
Both Wget and cURL are command-line utilities that allow file transfer from the internet. Although, Curl generally offers more features than Wget, wget provide features such as recursive downloads.
Can you Use Wget With Python?
Yes, you can run wget get in Python by installing the wget library with $pip install wget
Does Wget Respect Robots.txt?
Yes, Wget respects the Robot Exclusion Standard (/robots.txt)
Is Wget Free?
Yes, GNU Wget is free software that everyone can use, redistribute and/or modify under the terms of the GNU General Public License
What is recursive download?
Recursive download, or recursive retrieval, is the capacity of downloading documents, follow the links within them and finally downloading those documents until all linked documents are downloaded, or the maximum depth specified is reached.
How to specify download location in Wget?
Use the -P or –directory-prefix=PREFIX. Example: $ wget -P /path <url>
Conclusion
This is it.
You now know how to install and use Wget in your command-line.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.