What if I tell you that you could rank #1 on Google and get 0 clicks. It would be an obvious statement to experienced SEOs.
What if I can tell you that you improve your CTR by knowing which keywords have no snippets?
Now we talk.
First, what we are going to do is to find when a keyword has a lot of ads. Second, We are going to see which snippets are getting shown for a given list of keyword. Last, we’re going to look the real average position of the first organic result on Google.
Beware: by scraping Google, you may get your IP blocked. It is preferable to use proxies and IP rotation, or use a service such as Apify to handle the hurdle for you. See how to scrape Google without getting blocked.
Overview of the Google Search Engine Result Page (SERP)
When we look at the there is lot more that goes on than the simple top 10 organic results.
To understand the real position of an organic result using Xpath, we first need to understand how the SERPs results are displayed in Google.
There are five big sections in Google SERPs:
- The Content Navigation Bar
- The Top Ads Section
- The Search Results
- The Bottom Ad Section
- The Complementary Results (Knowledge Panel)

1. The Content Navigation Bar
The content navigation bar has the div ID “extabar” and appear usually on queries that obviously call for a list, such as “Movies 2019”, “Best Books 2019” or “SEO blogs”.
2. The Top Ads Section
The top ads section has the div ID “tvcap“. Usually, this shows Google Ads Results (id="tads"), but it can also contain Google Shopping results (class="cu-container") on top of the regular Google Ads.
3. The Search Results
The search results has the div ID “search”. This is what we understand as the organic search results, and is the most complex of them all.
In this section, you can find the top 10 organic results (the regular blue links that we are used to). But, you can find a lot of different modules called “Featured Snippets“. Here’s a non-exhaustive list of what we can find in this section:
- Regular Search Results
- Google Map’s Local Pack
- Google Jobs
- People Also Ask Boxes
- Quick Answers
- Top Stories
- Videos
- News
4. The Bottom Ads Section
The bottom ads section has the div ID “bottomads“. Exactly like top Google Ads Results, but at the bottom of the top 10 results.
Here, I will not cover this part, since I don’t believe they impact the organic CTR enough to be in the model.
5. The Complementary Results (Knowledge Panel)
I call it the Complementary Results, because this is what Google calls it in its code, but this is what we know to be the famous “Knowledge Panel“.
This decreases organic CTR a lot, so we need to add it to the model.
Methodology
Now that we know the stuff that can appear on top of the organic search results , we need to look at what has a real impact on organic Click-Through-Rate (CTR).
- Google For Jobs
- Google Shopping ad
- Google Ads
- People Also Ask
- Content navigation bar
- Local packs
- Knowledge Panel
To find pages that have a chance to result in a click, we are going to get to see the position of the first results and substract everything that can impact its CTR.
Real Position = Position of first organic result – Google Jobs – Google Ads – Google Shopping – People Also Ask – Content Navigation Bar – Local Pack
Tracking
To see if it is working, pages that got featured snippets out (when I wrote this post).
- https://www.google.ca/search?q=best+movies+2019 (Content Navigation Bar)
- https://www.google.ca/search?q=jobs (Google Ads + Google Jobs)
- https://www.google.ca/search?q=jean+christophe+chouinard (Knowledge Panel)
- https://www.google.ca/search?q=buy+laptop (Google Shopping + Local Pack)
- https://www.google.com/search?q=div+containing+a+node+xpath (People Also Ask)
- https://www.google.com/search?q=emploi+vente+a+quebec+jobillico (Google Jobs not position 1)
Set-up Screaming Frog
Google can ban your IP temporarily if you try to scrape their content. You need a proper set-up to crawl them using Screaming Frog so you don’t get the Captcha out for crawling too fast. Thanks to Patrick Landgridge for the set-up details.
- Configuration > Spider > Rendering > JavaScript
- Configuration > robots.txt > Settings > Ignore robots.txt
- Configuration > User-Agent > Present User Agents > Chrome
- Configuration > Speed > Max Threads = 1 > Max URI/s = 0.5
Count the Real Position of an Organic Result
The count the position of the first real organic result, we need to look at what beat position #1 keyword.
count(//div[contains(@class,'bkWMgd') and contains(.//h2,'Web results')][1]/preceding-sibling::*)+1+count(//div[@id="tads"]/ol/li)+count(//div[@id="tvcap"]/div[@class="cu-container"])+count(//div[@id="extabar"])
Position #1 Keyword
By using this XPath formula, you could get the real position of any result in Google.
count(//div[contains(@class,'bkWMgd') and contains(.//h2,'Web results')][1]/preceding-sibling::*)+1
or
(//div[contains(@class,'r')]/a[contains(@ping,"/url")]/@href)[1]
Position #2 Keyword
count(//div[contains(@class,'bkWMgd') and contains(.//h2,'Web results')][2]/preceding-sibling::*)+1
Position #X Keyword
count(//div[contains(@class,'bkWMgd') and contains(.//h2,'Web results')][X]/preceding-sibling::*)+1
Google Jobs
Show if Google Jobs is shown in the search results
count(//div[contains(@class,'bkWMgd') and .//div[contains(@class,'BjJfJf gsrt cPd5d')]])
Show which employers rank the Google Jobs Top 3 Pack for a given keyword.
count(//div[contains(@class,'bkWMgd') and .//div[contains(@class,'BjJfJf gsrt cPd5d')]])
Extract Job titles from Job Pack.
//div[contains(@class,'BjJfJf gsrt cPd5d')]
Google Shopping
count(//div[@id="tvcap"]/div[@class="cu-container"])
Google Ads
Show the number of ads everywhere on page 1.
count(//li[@class='ads-ad'])
Show the number of Ads at the top for a given keyword.
count(//div[@id="tads"]/ol/li)
Show the number of Ads at the bottom for a given keyword.
count(//div[@id="bottomads"]/ol/li)
Extract Ads Title
//li[@class='ads-ad']/div/a/h3
People Also Ask
count(//div[contains(@class,'bkWMgd') and contains(.//h2,'People also ask')])
Content Navigation Bar
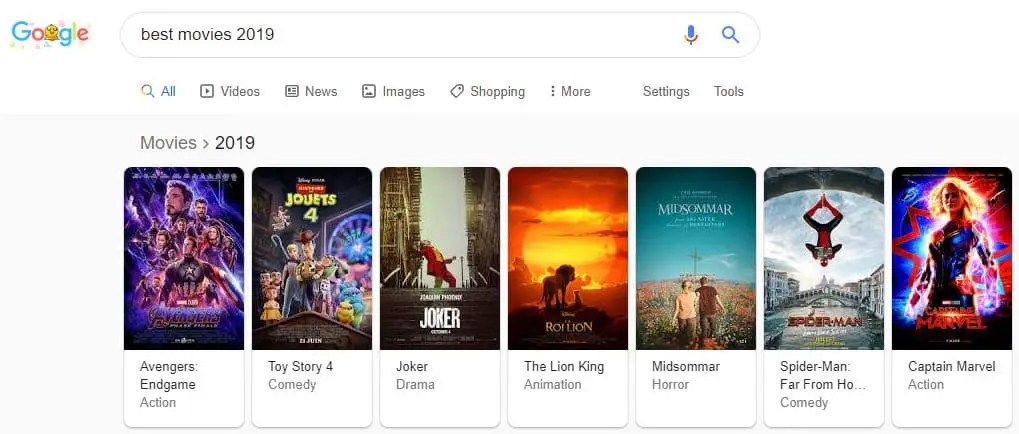
count(//div[@id="extabar"])
Local Pack
count(//div[contains(@class,'bkWMgd') and contains(.//h2,'Local results')])
Articles Related to Web Scraping

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.