In this tutorial, we will learn how to use Google’s Indexing API with Python.
What is the Indexing API?
The indexing API is an Application Programming Interface that allows site owners to notify Google when pages are added or removed. This allows Google to instantly index any webpage. It is mainly used for short-lived content such as job postings and news articles.
When using the indexing API, Google will prioritise these URLs to be crawled and indexed above others.
With the indexing API, you can:
- Update URLs in the index
- Remove URLs from the index
- Get the status of the latest request
- Send batch requests to reduce the number of API calls.
Requirements
For this tutorial, you will need a few things:
- Have Python installed
- Full or Owner permission level to Google Search Console
Check if you Have Access Levels to Run the API
Go to the Google Indexing API playground.
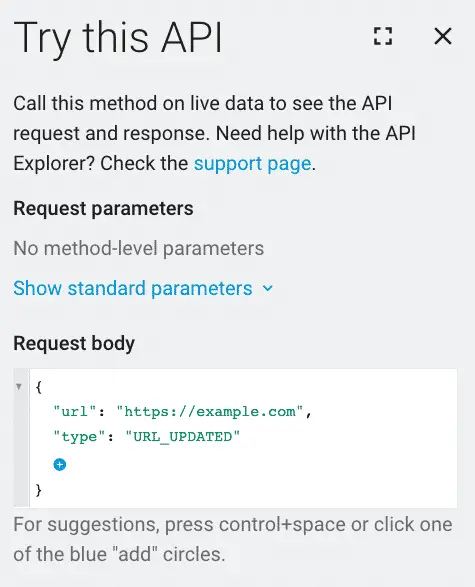
Add this request body.
{
"url": "https://example.com",
"type": "URL_UPDATED"
}
If the status code is 200, then you have everything that you need to proceed.

Create your API project
Go to Google developer console and create a new project.
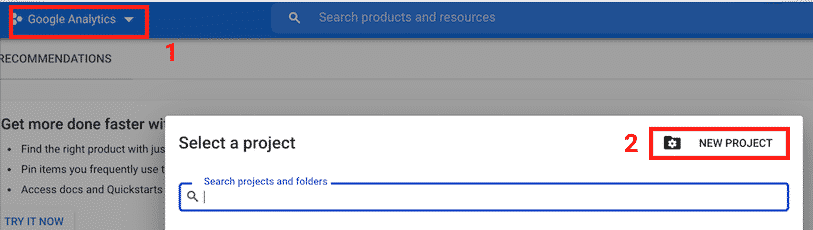
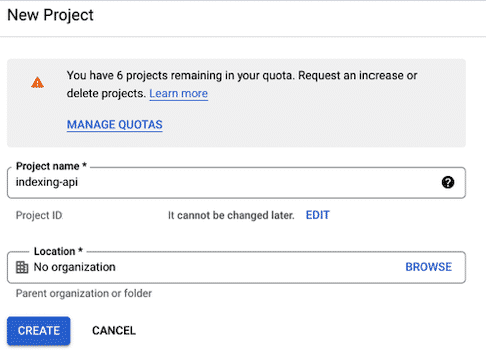
Give it a name and click “CREATE”.
Create a service account
The service account will act as the email that will interact with the indexing API.
Make sure that you are in the project that you just created.
Go to create the API credentials.
Click on “Manage service accounts”.
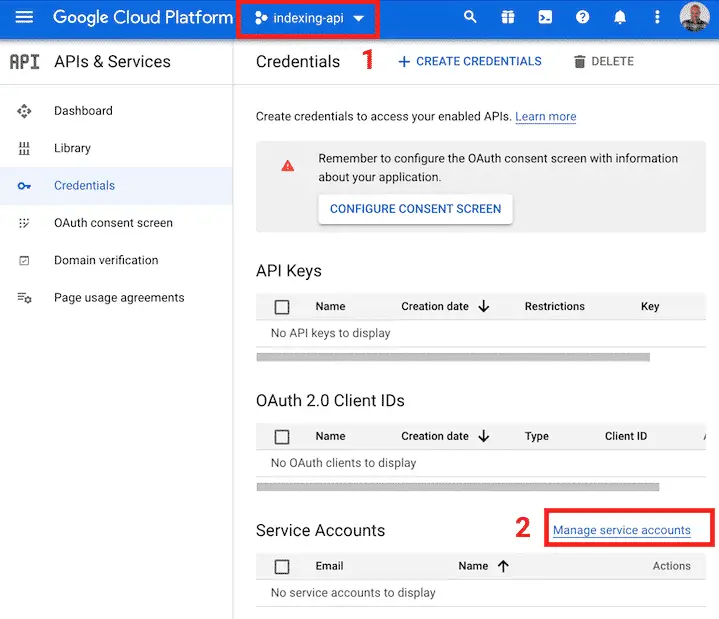
Click on “CREATE SERVICE ACCOUNT”.
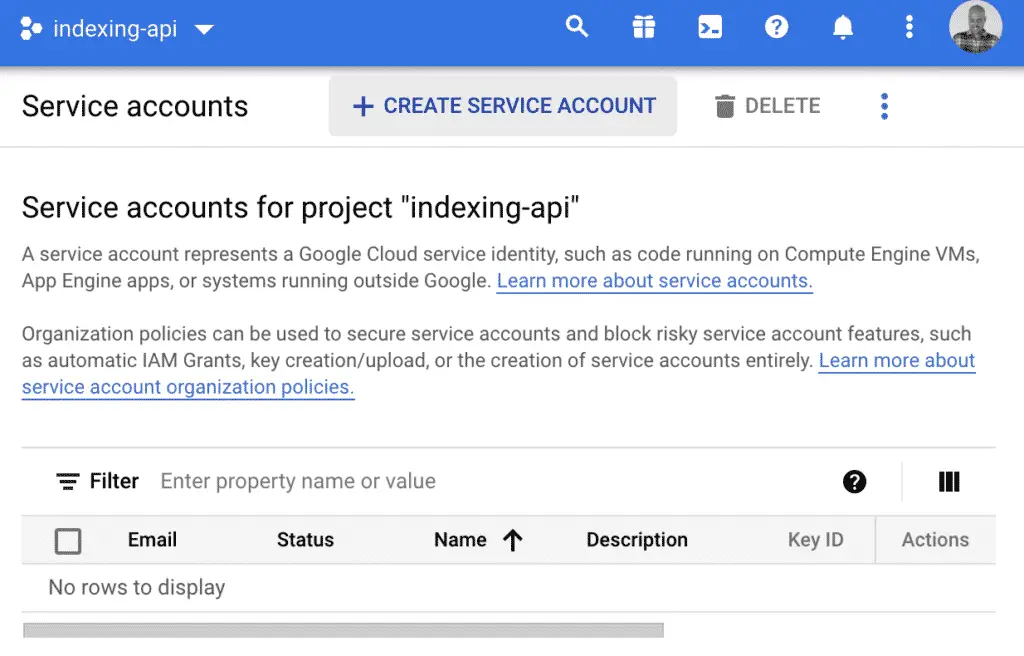
Then, create the service account with the information that you want.
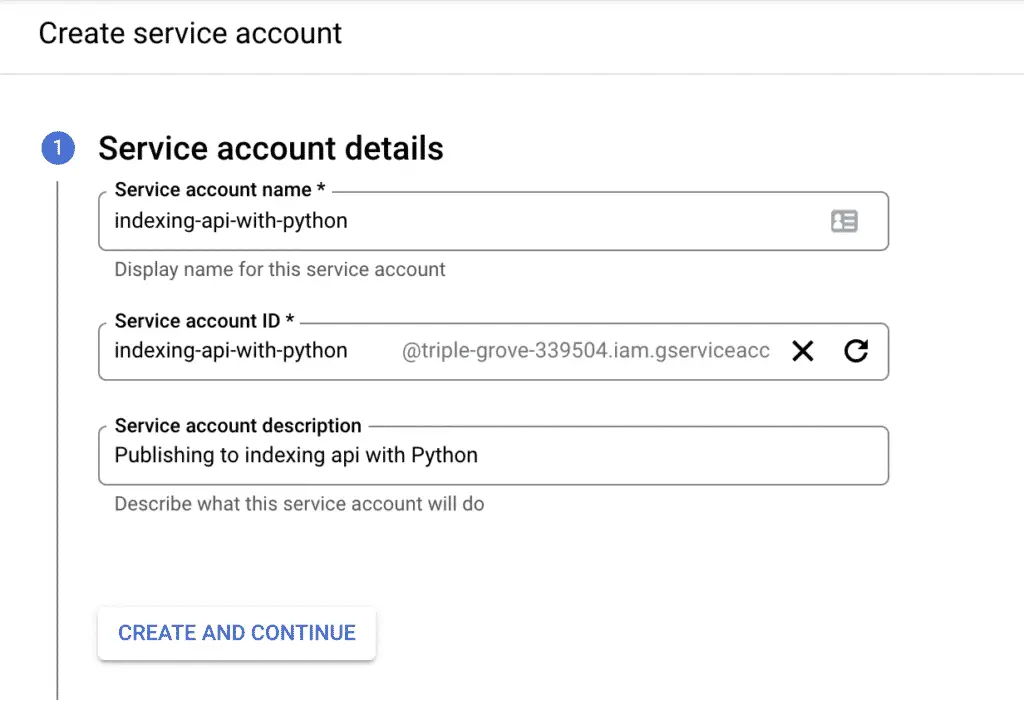
Select the “Owner” role.
You can skip the next step and create the service account.
Create API Keys
First, store the email ending in “gserviceaccount.com” for later use. For the newly created service account, you will need to create the API keys that will act as the username and password for your application.
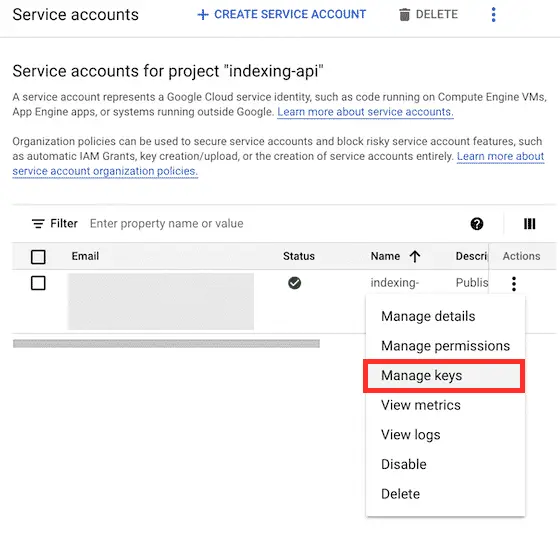
Click on “ADD KEY” > “Create new key”.
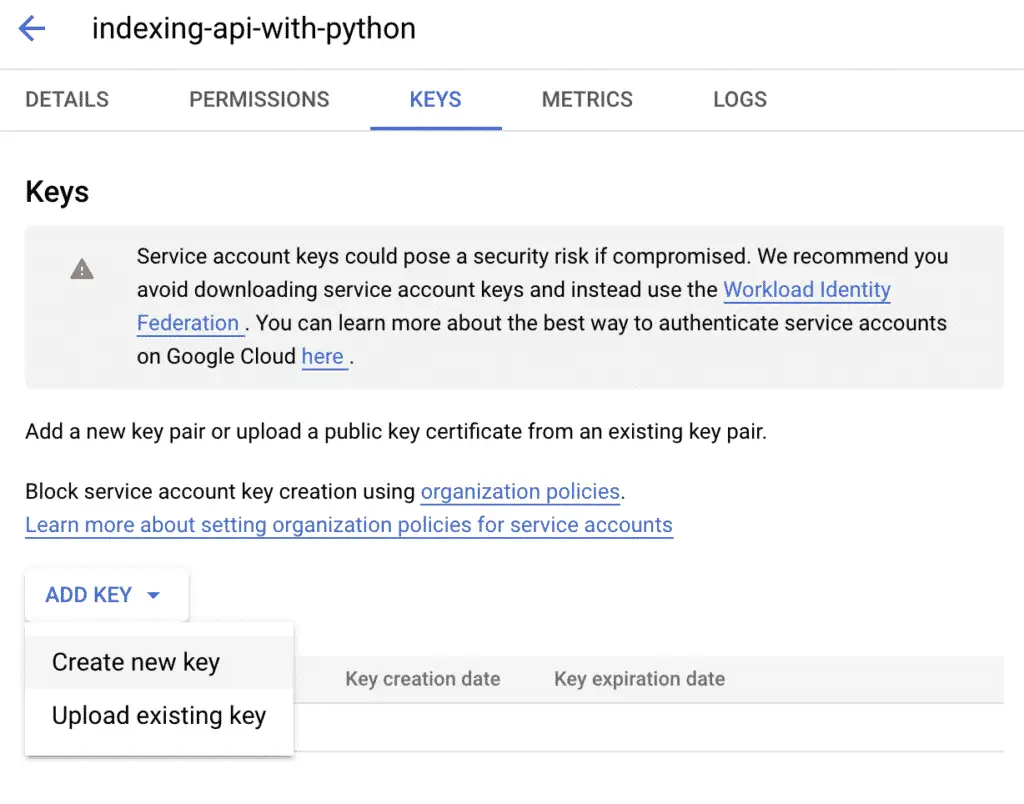
Select JSON for your private key, and then click on “CREATE”.

Save the file somewhere safe.
Enable Indexing API
Now, the API needs to be enabled in your project for you to use it.
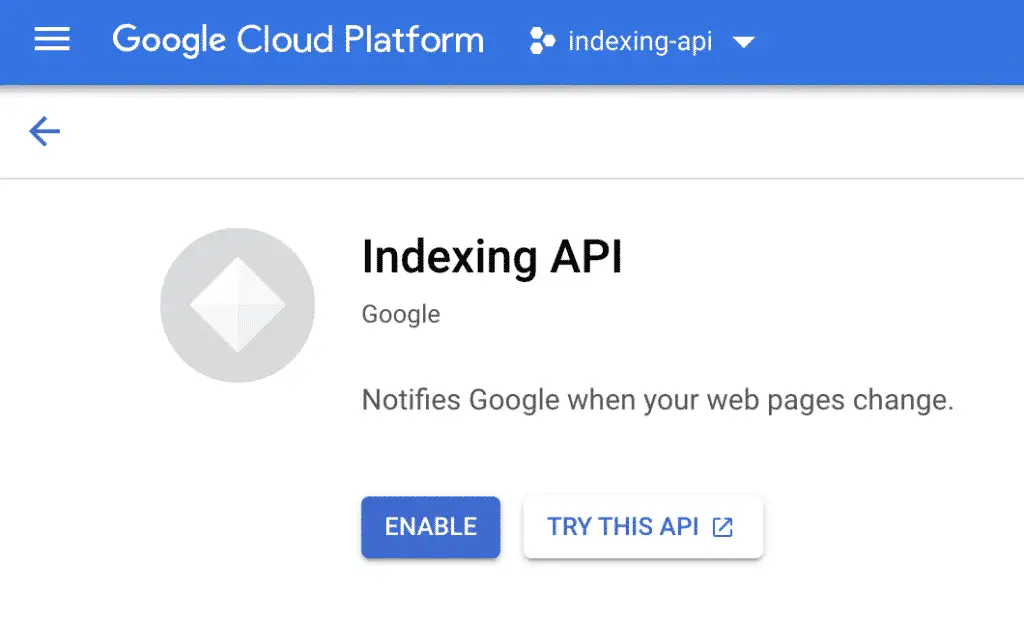
Go to the indexing API library and enable it in your project.
Make sure that you are in the “indexing-api” project and click on “ENABLE”.
Give Owner Status to the Service Account
For the indexing API to work properly, you need to give ownership to your service account email in the webmaster center.
Go to Webmaster Center.
Add the property that you want to use the indexing API on, or choose from the list.
Go to “Verified Owners” and click on “Add an owner”.
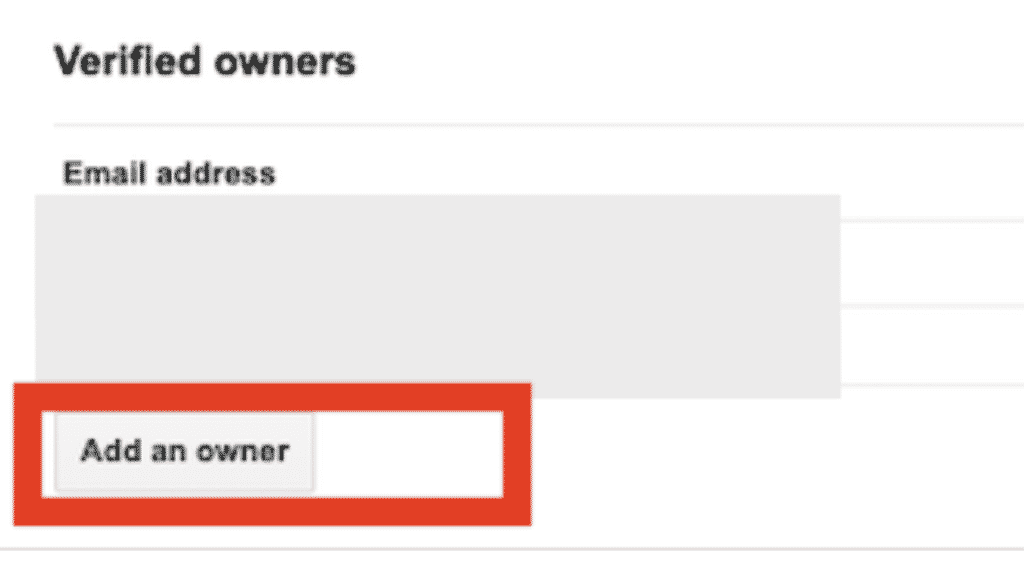
And add the service account. This is the email ending in “gserviceaccount.com” that you have created. You can find it in the credentials tab.
Run the Indexing API in Python
To publish to the indexing API with Python we will use the oauth2client, the httplib2 and json libraries. To install them with pip:
$ pip install oauth2client httplib2
Then, here’s the Python code for the extraction.
from oauth2client.service_account import ServiceAccountCredentials
import httplib2
import json
url = 'https://www.example.com/'
JSON_KEY_FILE = "credentials.json"
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
# Authorize credentials
credentials = ServiceAccountCredentials.from_json_keyfile_name(JSON_KEY_FILE, scopes=SCOPES)
http = credentials.authorize(httplib2.Http())
# Build the request body
print(url)
content = {}
content['url'] = url
content['type'] = "URL_UPDATED"
json_content = json.dumps(content)
response, content = http.request(ENDPOINT, method="POST", body=json_content)
result = json.loads(content.decode())
Send Batch Requests to the Indexing API with Python
Now, you can send batch requests to up to 100 URLs in a single request.
from oauth2client.service_account import ServiceAccountCredentials
from googleapiclient.discovery import build
from googleapiclient.http import BatchHttpRequest
import httplib2
import json
requests = {
'https://www.jcchouinard.com/':'URL_UPDATED',
'https://www.jcchouinard.com/about/':'URL_UPDATED'
}
JSON_KEY_FILE = "credentials.json"
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
# Authorize credentials
credentials = ServiceAccountCredentials.from_json_keyfile_name(JSON_KEY_FILE, scopes=SCOPES)
http = credentials.authorize(httplib2.Http())
# Build service
service = build('indexing', 'v3', credentials=credentials)
def insert_event(request_id, response, exception):
if exception is not None:
print(exception)
else:
print(response)
batch = service.new_batch_http_request(callback=insert_event)
for url, api_type in requests.items():
batch.add(service.urlNotifications().publish(
body={"url": url, "type": api_type}))
batch.execute()
Indexing API Endpoints
With Google’s indexing API, you are allowed to do 2 things:
- Publish updates for specific URLs
- Get information about the latests change to a URL
- Execute batch requests
Publishing Endpoint
To publish updates, create POST requests to this API endpoint:
https://indexing.googleapis.com/v3/urlNotifications:publish
Within the body of the request, you can define two parameters:
URL_UPDATED: Update the URL in the indexURL_DELETED: Remove the URL from the index
Metadata Endpoint
To get information about the latest HTTP request, create a GET request to this API endpoint:
https://indexing.googleapis.com/v3/urlNotifications/metadata
Batch Requests Endpoint
To send batch request to the indexing API, make POST requests to this API endpoint:
https://indexing.googleapis.com/batch
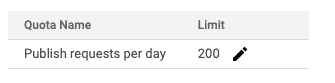
Indexing API Quotas
Google’s Indexing API imposes quotas on the number of possible requests. The default number of requests per day is 200. If you need to increase your quota, you will need to submit a request to Google.
That being said, the indexing API allows batch requests. That allows for requests in batches of 100 URLs, which combined, allows 20K URLs to be updated per day.
Indexing API Errors
- Status code
403. Status: PERMISSION_DENIED. Multiple causes: unsufficient access level, indexing API not enabled in ceveloper console - Status code
429. Status: RESOURCE_EXHAUSTED. Rate limiting because your quota is exceeded.
- Status code
403. Status: PERMISSION_DENIED. Multiple causes: unsufficient access level, indexing API not enabled in ceveloper console - Status code
400. Status: INVALID_ARGUMENT. Body of the request has an issue. Check if it follows the right format.
See additional indexing API errors.
Indexing API Does Not Mean Indexed Content
Even when using the Google Indexing API, Google will still prioritise the URLs to be indexed. Not everything will be indexed, at least not instantly.
The indexing priority is a lot higher than with regular indexation, but it is not foolproof.
In the words of Google’s Martin Splitt talking about the indexing API in the Future of SEO Search Off the Record Session:
pushing it to the API doesn’t mean that it gets indexed right away or indexed at all because there will be delays, there will be scheduling, there will be dismissal of spammy or bad URLs
Martin Splitt – Google
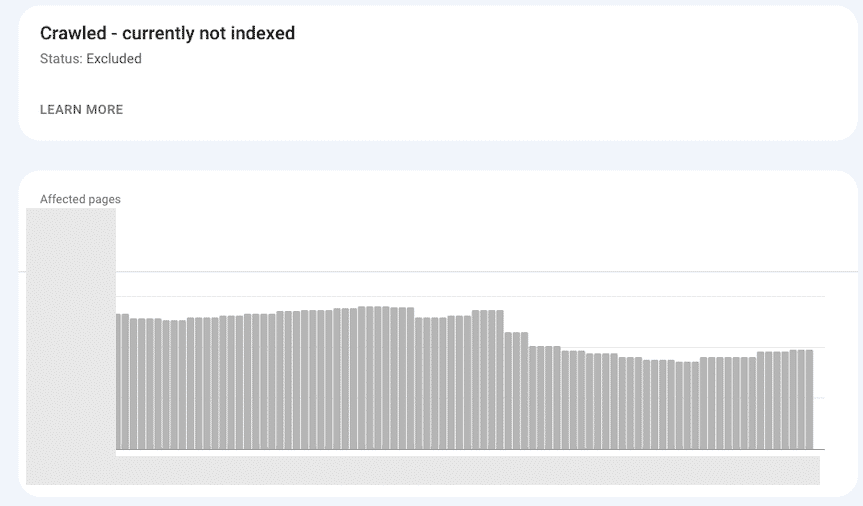
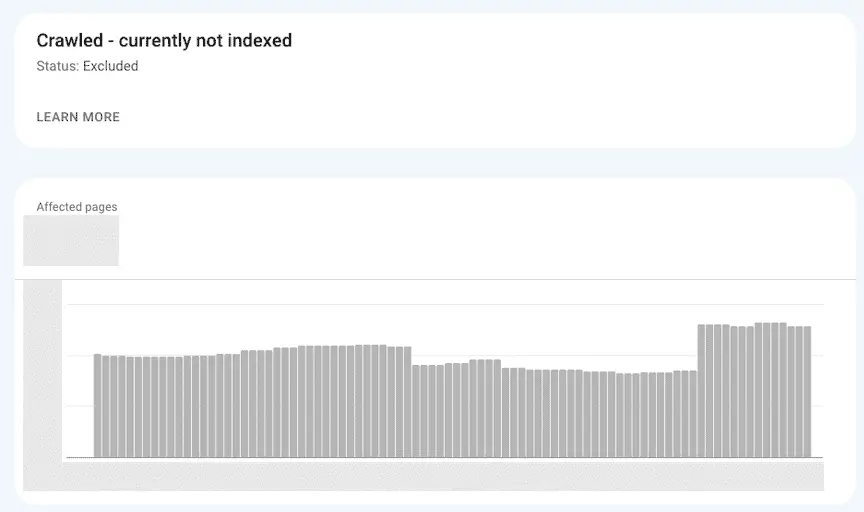
To validate this, as a small experiment, using the Indexing API, I tried to force Google to update some pages out of Crawled - currently not indexed.
The screenshot below shows that it worked well.
Then, on another site, I tried to scale up and send a lot more URLs gathered from my search logs.
The result was the opposite. Instead of decreasing the Crawled - currently not indexed category, it increased it. The interpretation of this is that I went either too fast, or sent too many irrelevant URLs with the API. Either way, the result wasn’t what I wanted.
Interesting Work in the Community
- Google’s Indexing API with NodeJS – Dave Sottimano
- Google’s Indexing API with .NET – Hamid Mosalla
- Google Indexing API tests with normal URLs, which have NEITHER job posting NOR livestream structured data – Tobias Willmann
- Rankmath’s indexing API built-in functionality
Conclusion
Google’s indexing API is not a “SEO Hack” that you can use to force Google to crawl and index your site more often. Google has some rules in place to prevent abuse. That being said, increased crawling does not mean better SEO. However, more requests do mean higher energy used and ecological impact. To learn more, read about the ecological impact of the web.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.