In this tutorial, we will use Python to extract data from the Wikipedia API.
You will learn how to interact with the API using Python and Requests without installing Wikipedia wrappers.
- Get abstract from Wikipedia page
- Make a search with the Wikipedia API
- Extract the entire text content from a Wikipedia page
- Find all links on the page
- Get all links in the Wikipedia sidebar and infobox
- Read the entities on Wikipedia
Navigation
Show
What is the Wikipedia API?
The Wikipedia API (official documentation) is supported by the MediaWiki’s API and provide access to Wikipedia and other MediaWiki data without interacting with the user interface.
Getting Started
For this tutorial, you will need to install Python and install the requests package.
Alternatively, you may want to experiment with Wikipedia API sandbox that provides a UI to send requests to the API.
Wikipedia Actions
In this article, we will look at two of the possible actions of the API:
query: allows to fetch information about a wiki and the data stored in it.parse: allows to parse the actual HTML of the page. This will be useful to workaround some of the pitfalls of thequeryaction.
Structure of the Wikipedia API endpoint
All MediaWiki APIs follow the same endpoint pattern:
https://www.example.org/w/api.php
To which parameters are added to define what to extract.
How to make a request to the Wikipedia API?
To call the Wikipedia API, append the needed parameters to the endpoint, just like the example below:
Then parse the response.
Get abstract from Wikipedia Page
To get the abstract from a Wikipedia page, use the action parameter along with the titles, the prop=extracts, exintro and explaintext parameters.
The format parameter lets you define the output format of the data, in this case json.
import requests
subject = 'Python (programming language)'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action': 'query',
'format': 'json',
'titles': subject,
'prop': 'extracts',
'exintro': True,
'explaintext': True,
}
response = requests.get(url, params=params)
data = response.json()
page = next(iter(data['query']['pages'].values()))
print(page['extract'][:73])
Here is the result.
Python is an interpreted high-level general-purpose programming language.
Get Full Text From Wikipedia Page
To get the full text from a Wikipedia page, use the action=parse parameter and then parse the response with lxml.
import requests
from lxml import html
subject = 'Python (programming language)'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action': 'parse',
'format': 'json',
'page': subject,
'prop': 'text',
'redirects':''
}
response = requests.get(url, params=params).json()
raw_html = response['parse']['text']['*']
document = html.document_fromstring(raw_html)
text = ''
for p in document.xpath('//p'):
text += p.text_content() + '\n'
print(text)
Make a search with the Wikipedia API
When you need to search Wikipedia articles for a specific term, use the srsearch parameter.
import requests
query = 'python'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action':'query',
'format':'json',
'list':'search',
'utf8':1,
'srsearch':query
}
data = requests.get(url, params=params).json()
for i in data['query']['search']:
print(i['title'], ' - Word count: ', i['wordcount'])
Output:
Python (programming language) - Word count: 11636
Python - Word count: 247
Monty Python - Word count: 16764
Reticulated python - Word count: 4608
PYTHON - Word count: 600
History of Python - Word count: 2891
Ball python - Word count: 2195
Burmese python - Word count: 4644
Python molurus - Word count: 1162
Monty Python and the Holy Grail - Word count: 4896
Extract the entire text content from a Wikipedia page
With the parse action, we will get the entire HTML of a Wikipedia page and parse it with BeautifulSoup.
import requests
from bs4 import BeautifulSoup
subject = 'Machine learning'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action': 'parse',
'page': subject,
'format': 'json',
'prop':'text',
'redirects':''
}
response = requests.get(url, params=params)
data = response.json()
raw_html = data['parse']['text']['*']
soup = BeautifulSoup(raw_html,'html.parser')
soup.find_all('p')
text = ''
for p in soup.find_all('p'):
text += p.text
print(text[:58])
print('Text length: ', len(text))
Output:
Machine learning (ML) is the study of computer algorithms
Text length: 44216
Find all links on the page
Get all the links on a Wikipedia page using the query action.
Let’s introduce two new parameters of the query action: pllimit and redirects.
The pllimit allows you to make extractions that go beyond the limits imposed by the API in a single query. Then plcontinue allows you to loop each page to extract more information.
The redirects parameter makes sure that the redirections are followed to the end URL.
import requests
subject = 'Machine learning'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action': 'query',
'format': 'json',
'titles': subject,
'prop': 'links',
'pllimit': 'max',
'redirects':''
}
response = requests.get(url=url, params=params)
data = response.json()
pages = data['query']['pages']
page = 1
page_titles = []
for key, val in pages.items():
for link in val['links']:
page_titles.append(link['title'])
while 'continue' in data:
plcontinue = data['continue']['plcontinue']
params['plcontinue'] = plcontinue
response = requests.get(url=url, params=params)
data = response.json()
pages = data['query']['pages']
page += 1
for key, val in pages.items():
for link in val['links']:
page_titles.append(link['title'])
page_titles[:3]
Output:
['ACM Computing Classification System', 'ACM Computing Surveys', 'ADALINE']
To get the links in the sidebar, use the parse action instead of the query action.
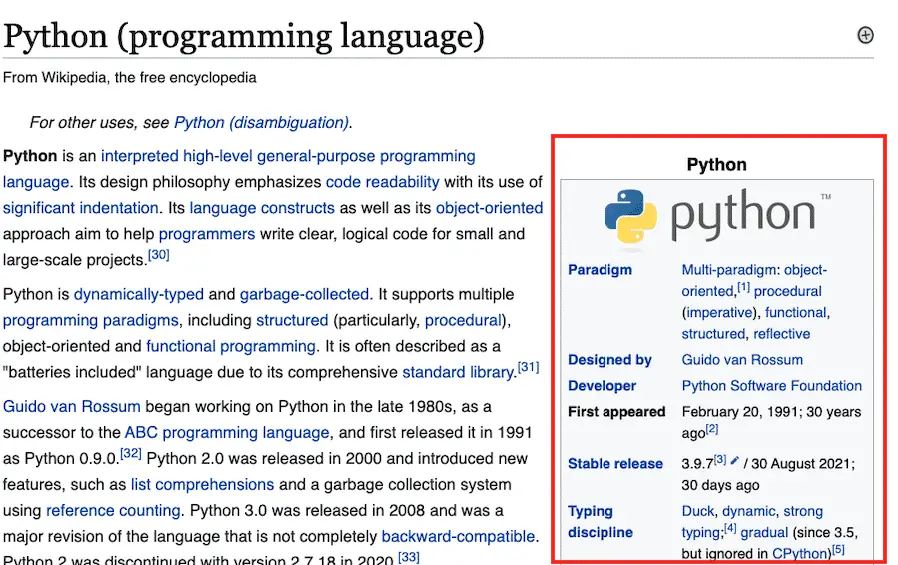
Why not use query?
We could use query and target that section, but the pitfall becomes apparent.
import requests
subject = 'Python (programming language)'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action':'query',
'prop':'revisions',
'format':'json',
'rvprop':'content',
'titles':subject,
'rvsection':0,
'redirects':''
}
data = requests.get(url, params=params).json()
data['query']['pages']['23862']['revisions'][0]['*'][:800]
Then, instead of getting usable format, we end up with data with dynamic variables like this {{}} and this [[]].

Which is not what we want.
There are 3 ways to work around this:
- Use the wikidata api to get the entites
- Use dbpedia to get a well formated entity format
- Parse the page
Here I will go with option 3, parsing the data and creating a Pandas DataFrame.
from bs4 import BeautifulSoup
import pandas as pd
import requests
subject = 'Machine Learning'
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action':'parse',
'prop':'text',
'format':'json',
'page':subject,
'section':0,
'redirects':''
}
data = requests.get(url, params=params).json()
soup = BeautifulSoup(data['parse']['text']['*'],'html.parser')
infobox = soup.find('table',{'class':'infobox','class':'sidebar'})
a_tags = infobox.find_all('a', href=True)
links = []
for tag in a_tags:
if not tag.text == '' and 'wiki' in tag['href']:
links.append({'anchor':tag.text, 'href':tag['href']})
pd.DataFrame(links).head()
Output:

Read the entities on Wikipedia
We have parsed the page. However there is another way to get entities from Wikipedia, and that is through the Dbpedia service.
For example, you can go to that link and see the entities you would get for the page that you want.
https://dbpedia.org/page/Machine_learning
To extract that data in a JSON format, you would use the /data/ path.
http://dbpedia.org/data/Machine_learning.json
import requests
query = 'Machine learning'
db_q = query.replace(' ', '_')
db = 'http://dbpedia.org'
url = db + f'/data/{db_q}.json'
data = requests.get(url).json()
data
Wikidata API VS Wikipedia API
While the Wikipedia API allows you to query the content that you find on the actual Wikipedia page, the Wikidata API allows you to query the data behind that is used to build content across the MediaWiki organisation (wikitravel, wikipedia, wikispecies, etc.).
So, with the Wikidata API, you can, in a way query the Wikipedia content, but with wikipedia, you may not be able to query some of the data in wikidata.
Interesting Work from the Community
- Wikipedia Search App using Python and Tkinter (by PyCodeMates)
- Topic modelling with the Wikipedia API and the Gensim Library (by Usman Malik)
- Auto-Generated Knowledge Graphs (by Chris Thornton on Towardsdatascience)
- Using Wikipedia API with Python for SEO (by Daniel Heredia Mejias)
- Using Wikipedia for Content Marketing, SEO (by Armando Roggio)
Conclusion
We have learned how to extract text, links and entities from Wikipedia, using their API. This is only scratching the surface, so share any cool ideas that you may come up with!

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.