
In this post, I will show you how to make an API call with Reddit API and Python using Pushshift.io.
We will extract data from Reddit API to find out which subreddit has the most activity for your search term.
We will also return the topmost upvoted comments.
Special thanks to Duarte O.Carmo who developed the code for this post (find a link to his work at the end).
If you know nothing about Python, make sure that you start by reading the complete guide on Python for SEO.
Getting Started
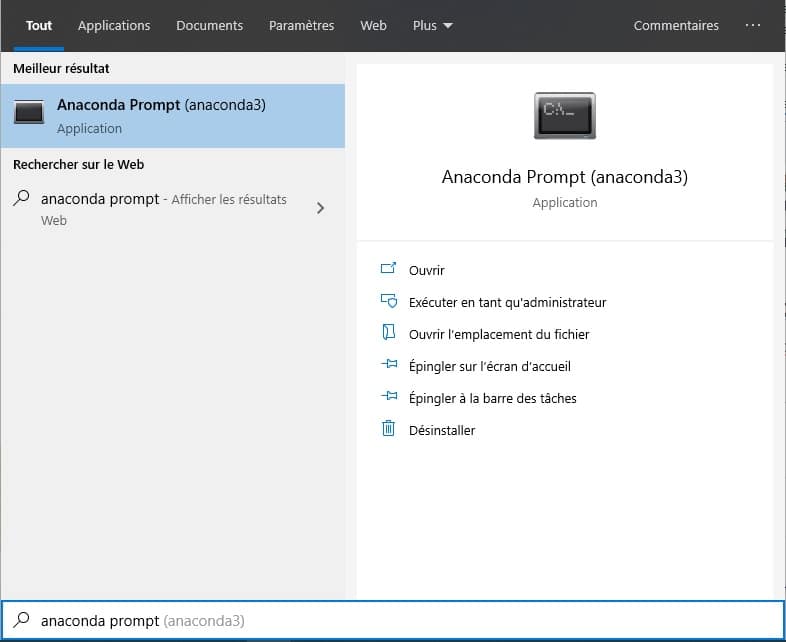
Before you can run the script, make sure that you have installed Python with Anaconda.
You will also need to install plotly and requests with conda.
To do so, go to the Anaconda Prompt and type these commands.
conda install -c plotly plotly
conda install -c anaconda requests
Make Your First Reddit API Call (Easy Way)
To call the Reddit API and extract the data, we will use an API called Pushshift.io.
The easiest way to use the API is with requests.
If you want to get the most recent comments with the word “SEO”, you could use this function.
import requests
query="seo" #Define Your Query
url = f"https://api.pushshift.io/reddit/search/comment/?q={query}"
request = requests.get(url)
json_response = request.json()
json_response
This will get you a JSON file to work with.
You can do much more by adding parameters:
- Grab data for a specific date range in the past
- Filter by subreddits
- Search for comments
- Exclude authors
Learn more by reading the introduction to the Pushshift post on Reddit.
Get More From The Reddit API
Now, I will show you (step-by-step) how to extract usable information from Reddit and visualize the data with Python.
Step #1: Create a Function to Call Pushshift API
To make it easier to work with the Reddit API using Pushshift, we will create a function to call the API when we need it.
This function is letting us define the payload parameters, the arguments with kwargs and the type of data we want to extract using data_type.
def get_pushshift_data(data_type, **kwargs):
"""
Gets data from the pushshift api.
data_type can be 'comment' or 'submission'
The rest of the args are interpreted as payload.
Read more: https://github.com/pushshift/api
"""
base_url = f"https://api.pushshift.io/reddit/search/{data_type}/"
payload = kwargs
request = requests.get(base_url, params=payload)
return request.json()
This function will return a JSON.
Step #2: Define Your Parameters
Let’s define our parameters.
data_type="comment" # give me comments, use "submission" to publish something
query="python" # Add your query
duration="30d" # Select the timeframe. Epoch value or Integer + "s,m,h,d" (i.e. "second", "minute", "hour", "day")
size=1000 # maximum 1000 comments
sort_type="score" # Sort by score (Accepted: "score", "num_comments", "created_utc")
sort="desc" # sort descending
aggs="subreddit" #"author", "link_id", "created_utc", "subreddit"
Step #3: Make the Reddit API Call
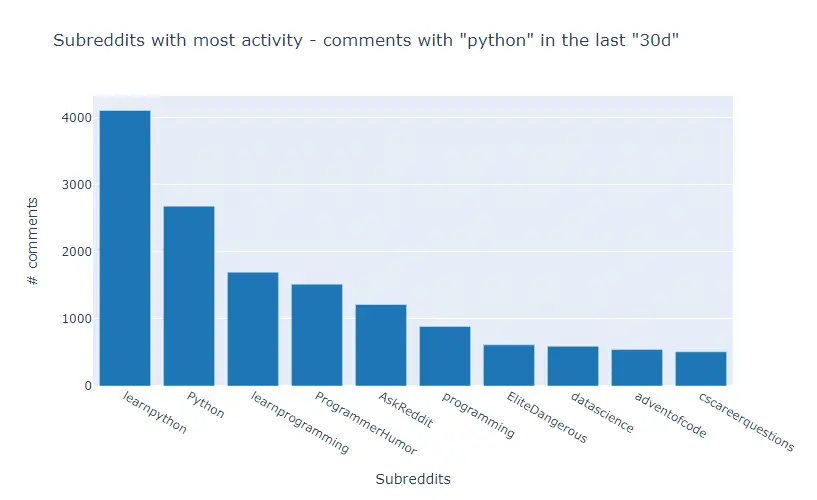
I will now extract a JSON file containing 1000 comments for the query “Python” in the last 30 days sorted by score.
get_pushshift_data(data_type=data_type,
q=query,
after=duration,
size=size,
sort_type=sort_type,
sort=sort)
Step #4: Find in Which Subreddit is Talking More About Your Keyword
Let’s find out in what subreddits the word ‘python’ appears more.
To extract this information, we need to call the API function.
data = get_pushshift_data(data_type=data_type,
q=query,
after=duration,
size=size,
aggs=aggs)
The aggs keyword asks Pushshift aggregate data into subreddits, which basically means, group the results by subreddit. (read about it in the documentation).
We will select the information that we need in the dictionary.
data = data.get("aggs").get(aggs)
Step #5: Add the Data to a Data Frame
The JSON file is a list of dictionaries.
We will transform this list into a pandas data frame and extract the top 10 subreddits talking about our keyword.
import pandas as pd
df = pd.DataFrame.from_records(data)[0:10]
df

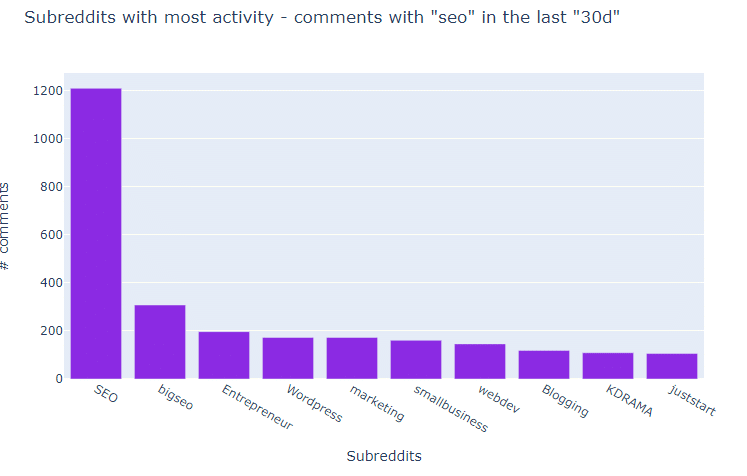
These are the subreddits where the word python appears most frequently in their comments.
Step #6: Plot the Data Using Plotly
To plot the best subreddits for your keyword, all you need is the plotly and this bit of code.
import plotly.express as px
px.bar(df, # our dataframe
x="key", # x will be the 'key' column of the dataframe
y="doc_count", # y will be the 'doc_count' column of the dataframe
title=f'Subreddits with most activity - comments with "{query}" in the last "{duration}"',
labels={"doc_count": "# comments","key": "Subreddits"}, # the axis names
color_discrete_sequence=["#1f77b4"], # the colors used
height=500,
width=800)
Step #7: Find the Most Up-Voted Comments
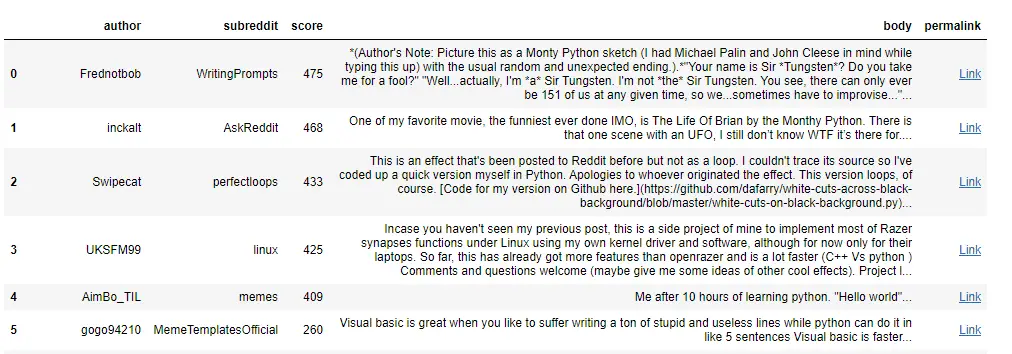
Which comments that include the “Python” keyword were the most up-voted?
# Call the API
data = get_pushshift_data(data_type=data_type,
q=query,
after="7d",
size=10,
sort_type=sort_type,
sort=sort).get("data")
# Select the columns you care about
df = pd.DataFrame.from_records(data)[["author", "subreddit", "score", "body", "permalink"]]
# Keep the first 400 characters
df['body'] = df['body'].str[0:400] + "..."
# Append the string to all the permalink entries so that we have a link to the comment
df['permalink'] = "https://reddit.com" + df['permalink'].astype(str)
# Create a function to make the link to be clickable and style the last column
def make_clickable(val):
""" Makes a pandas column clickable by wrapping it in some html.
"""
return '<a href="{}">Link</a>'.format(val,val)
df.style.format({'permalink': make_clickable})
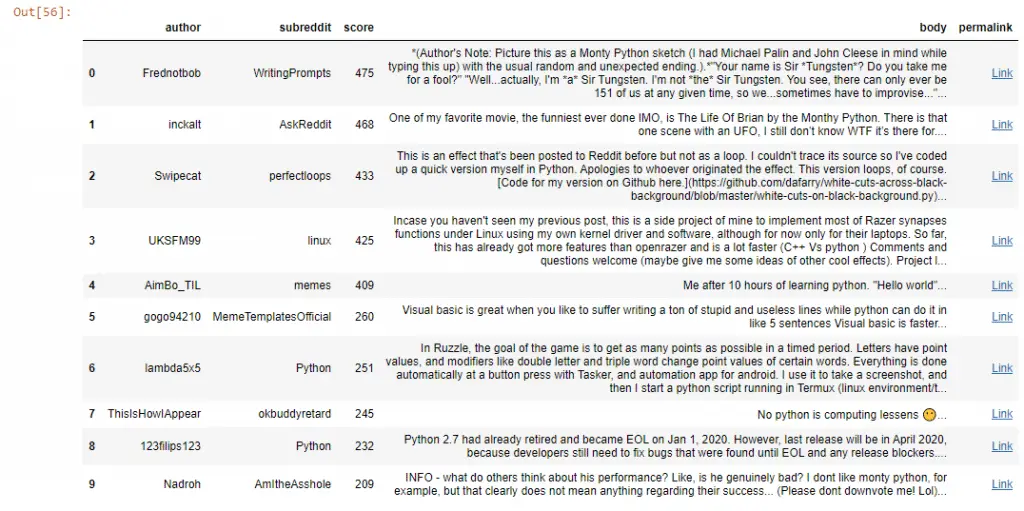
Voilà!
What’s Next?
Get Top Posts From Subreddit With Reddit API and Python
Reddit API JSON’s Documentation
How to use Reddit API With Python (Pushshift)
Get Reddit API Credentials with PRAW (Authentication)
Post on Reddit API With Python (PRAW)
Show Random Reddit Post in Terminal With Python
You now know how to use Reddit API with Python.
You can find the complete code in this Notebook.
This work must be attributed to Duarte O.Carmo who has developed this code for the post Creating Interactive Dashboards from Jupyter Notebooks.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.