Unsupervised learning is one of the techniques used in machine learning to train models by finding patterns in unlabelled data.
To learn, computers need to be trained. There are two ways that a machine can learn:
In this post, we will look specifically at unsupervised learning.
Learn Unsupervised Learning
This post is an overview of what supervised learning is and is in no way representative of the entire field of study.
If you want to learn more about supervised learning, here are a few Datacamp tutorials that helped me.
What is Unsupervised Learning?
Unsupervised learning, or unsupervised machine learning, is a category of machine learning algorithms that uses unlabeled data to make predictions.
Unsupervised learning algorithms try to discover patterns in the data without human intervention.
These algorithms are often used in clustering problems such as grouping customers based on their online activity.
What is the Difference Between Supervised and Unsupervised Learning?
Supervised learning, the machine is trained on previously labelled data.
Unsupervised learning, the machine is trained on unlabelled data (without human intervention).
While in supervised learning, you can compute the accuracy of a model by comparing predictions to manually labelled data and computing the error, the same technique is not applicable to unsupervised learning.
Instead, unsupervised learning relies on metrics such as the Sum of Squares Error to evaluate its models.
Types of Unsupervised Learning Problems
Common unsupervised learning algorithms are:
- Dimensionality reduction (PCA, NMF, t-SNE, …)
- Clustering (Kmeans, hierarchical clustering, DBSCAN)
- Anomaly Detection
- Neural Networks
Dimensionality Reduction
Dimensionality reduction techniques try to bring data from a high-dimensional space into a low-dimensional space retaining the meaningful properties of the original data.
- Linear feature extraction techniques
- Non-negative matrix factorization (NMF)
- Linear discriminant analysis (LDA)
- Non-linear feature extraction techniques
- T-distributed stochastic neighbor embedding (t-SNE)
- Generalized discriminant analysis (GDA)
- Autoencoder
- Kernel PCA
Clustering
Clustering machine learning algorithms try to divide objects into similar clusters based on similar characteristics.
- KMeans
- Hierarchical Clustering
- DBSCAN
- Gaussian methods
Examples of clustering problems:
- Recommender systems
- Semantic clustering
- Customer segmentation
- Targetted marketing
Anomaly Detection
Anomaly detection algorithms try to identify outliers in low-dimensional space.
- Local Outlier Factor
- Isolation Forest
Examples of anomaly detection problems:
- Fraud detection
- IT security (malicious events)
- Spam detection
Deep Learning and Neural Networks
Neural networks, also known as artificial neural networks (ANNs), try to mimic how neurons communicate to one another by using layers in which information is passed to the next layer only when they meet a certain threshold.
- Autoencoders
- deep belief networks
- generative adversarial networks (GANs)
Steps of Unsupervised Learning Process
Here is a series of steps from a typical unsupervised learning process to make sure that you use the right data, the right model, with the right hyperparameters in order to make the right decision on your data.
Here is a list of a typical unsupervised learning process:
- Data acquisition
- Exploratory Data Analysis (EDA)
- Data preprocessing
- Dimension reduction
- Model Training
- Model Validation
- Model Tuning
- Model Selection
Unsupervised Learning Python Example with Scikit-Learn
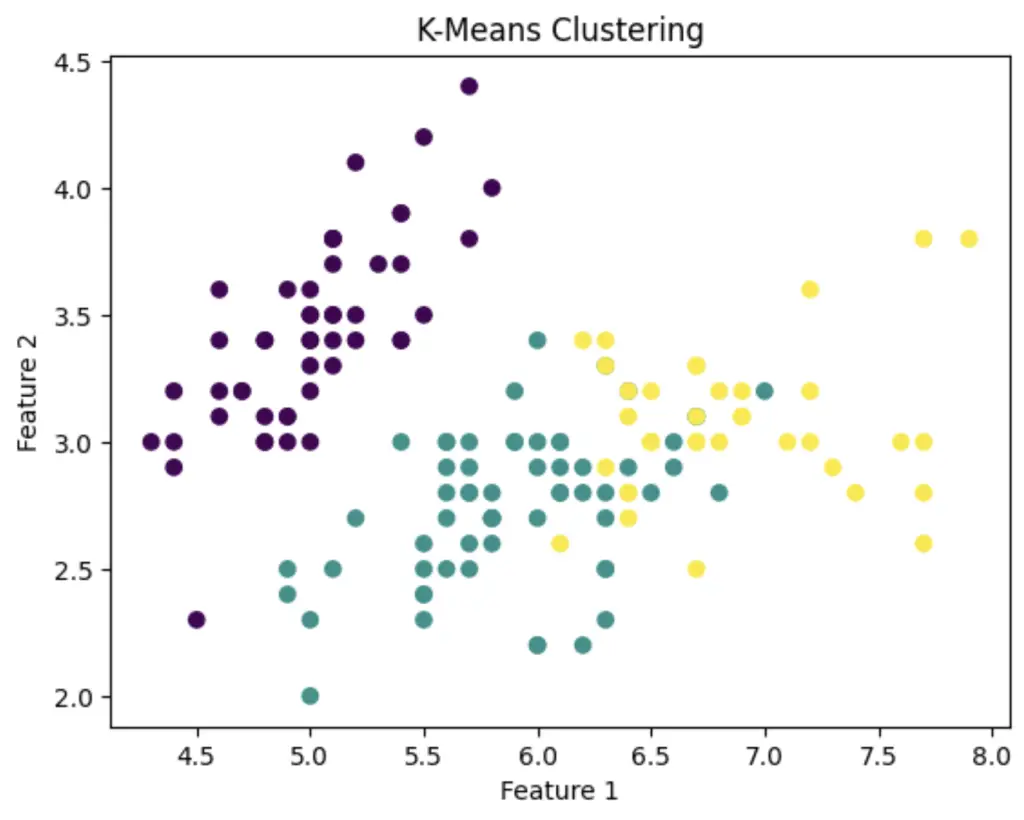
In this Python example, we will showcase how to cluster the iris dataset from the Scikit-learn library using the KMeans clustering algorithm.
# Import necessary libraries
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import KMeans
# Load the Iris dataset
iris = datasets.load_iris()
X = iris.data # Features
# Initialize the K-Means clustering model with 3 clusters (you can change the number)
kmeans = KMeans(n_clusters=3)
# Fit the model to the data
kmeans.fit(X)
# Get the cluster labels
labels = kmeans.labels_
# Add cluster labels to the dataset
iris['cluster'] = labels
# Visualize the clusters (assuming we take the first two features for simplicity)
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('K-Means Clustering')
plt.show()
Conclusion
In this introduction to the unsupervised learning branch of machine learning, we have learned what unsupervised learning is and how it is different to supervised learning.
We also have covered the types of unsupervised learning algorithms.
Finally, we have seen the steps of the unsupervised learning process.
If you have any questions please reach out on Twitter.
Until then, I hope you enjoyed learning about unsupervised learning.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.