Supervised learning defines an algorithm used in machine learning to train models based on labelled data.
To learn, computers need to be trained. There are two ways that a machine can learn:
In this post, we will look specifically at supervised learning.
Learn Supervised Learning
This post is an overview of what supervised learning is and is in no way representative of the entire field of study.
If you want to learn more about supervised learning, here are a few Datacamp tutorials that helped me.
What is Supervised Learning?
Supervised learning, or supervised machine learning, is one of the most common types of machine learning algorithms. It uses labelled data to make predictions.
Supervised learning algorithms change their parameters to find the best fit for the known training data in a process called cross-validation.
They make predictions by training (fitting) the model on a labelled training dataset, using a set of features as predictors.
These predictions can be compared to the actual data in the evaluation process.
What is the Difference Between Supervised, Unsupervised and Semi-Supervised Learning?
To main difference between supervised, unsupervised and semi-supervised learning lies in the data that is used to train the machine learning models.
- In supervised learning, the machine is trained using data that was previously labelled.
- In Unsupervised learning, the machine is trained using unlabelled data i.e. it works with unlabelled data.
- In Semi-supervised learning happens when only a subset of the training data has been labeled.
Labelled data means that the training data was labelled using human intervention like in the image below:

Examples of Supervised Learning Problems
Below are examples of training sets that can be used in supervised learning problems:
- Photos with labels about what is on them
- List of emails classified as spam or not
- Search queries being assigned to a category or entity
- Web pages that resulted in a sale, or not
Types of Supervised Learning Problems
Classification
Classification machine learning algorithms try to classify categorical data by observing and learning from labelled data.
Examples of classification problems:
- Average salary based on gender
- Image classification
- Web pages classification
Regression
Regression machine learning algorithms try to make predictions based on continuous target variables.
Examples of regression problems:
- Clicks forecasting on a website
- Sales forecasting
- Weather predictions
- Population growth forecasting
Types of Supervised Learning Algorithms
Linear Methods
Linear methods in supervised learning model the linear relationship between the input features and the target variable.
- Linear Regression
- Logistic Regression
- Polynomial Regression
- Ridge Regression
- Lasso Regression
Neighborhood-Based Methods
Neighborhood-based methods learn how to label new data points based on their proximity to existing data points.
Tree-Based Methods
Tree-based methods learn by segmenting or stratifying data into decision trees, based on available labels.
- Decision trees
- Decision Tree Classification
- Decision Tree Regression
- Random Forests
- Random Forest Classification
- Random Forest Regression
- Bootstrap aggregation (Bagging)
- Boosting
- Gradient Boosting Machines (XGBoost / LightGBM)
Support Vector Machines
Support vector machines (SVM) creates hyperplanes to separate the data, based on the available labels.
- Support Vector Regression
Neural Networks
Neural networks, also known as artificial neural networks (ANNs) or simulated neural networks (SNNs), try to mimic how neurons communicate to one-another by using layers (input layer, hidden layers, output layer), in which information is passed to the next layer only when they meet a certain threshold.
- Stochastic Gradient Descent
- Case-based reasoning
- Artificial Neural Networks
Probabilistic Methods
Probabilistic machine learning provides tools for modelling uncertainty, performing probabilistic inference, and making predictions in uncertain environments
- Naive Bayes
- CausalImpact
How Supervised Algorithms Work?
Supervised machine learning algorithms use labelled training datasets to predict an output.
The algorithms are trained on a subset of the data and the predictions are compared against the actual test data for the evaluation of the models.
- Use existing labelled dataset or add labels to existing data
- Split into training and test set
- Train the machine learning model on the training set
- Generate predictions from the training data
- Compare the prediction with the actual results from the test set
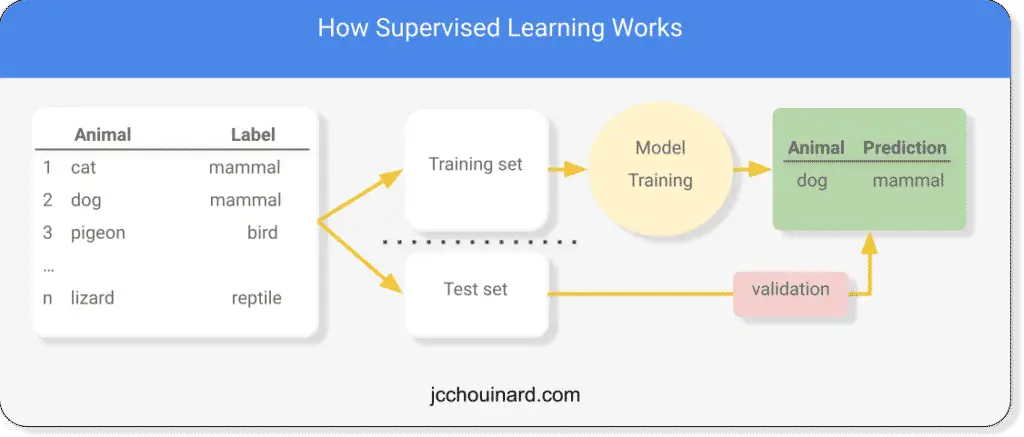
Steps of Supervised learning
Simply training a machine learning model on data is not enough. Data scientists need to go through a series of steps to make sure that they use the right data, the right model, with the right hyperparameters to take the right decision on their data.
Here is a list of a typical supervised learning process:
- Data acquisition
- Exploratory Data Analysis (EDA)
- Data preprocessing
- Model Training
- Model Validation
- Model Tuning
- Model Selection
Conclusion
In this introduction to the supervised learning branch of machine learning, we have learned what supervised learning is and how it is different to unsupervised or semi-supervised learning.
We also have covered the types of supervised learning algorithms.
Finally, we have seen the steps of the supervised learning process.
If you have any questions please reach out on Twitter.
Until then, I hope you enjoyed learning about supervised learning.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.