In this tutorial, we will combine the queries extracted from Google Search Console data into TF-IDF word vectors.
This tutorial is Part-2 of a series on using unsupervised learning for the clustering of web pages.
- Extract Google Search Console Queries by Page (using a python Wrapper)
- TF-IDF on Google Search Console Data
- Clustering and De-duplication of web pages using KMeans and TF-IDF
We will use the TF-IDF machine learning algorithm from Scikit-learn in this tutorial to create word vectors for each page’s queries.
Getting Started
For this tutorial, you will also need to install Python and install the following libraries from your command prompt or Terminal.
$ pip install scikit-learn
Overview of the Dataset
In the following tutorial, I am using Google Search Console data that shows queries by pages that we extracted in the last post of this series.
The dataset consists of two columns for the page and query dimensions, along with 4 columns that contain the clicks, impressions, ctr and position metrics.
import pandas as pd
df.head()
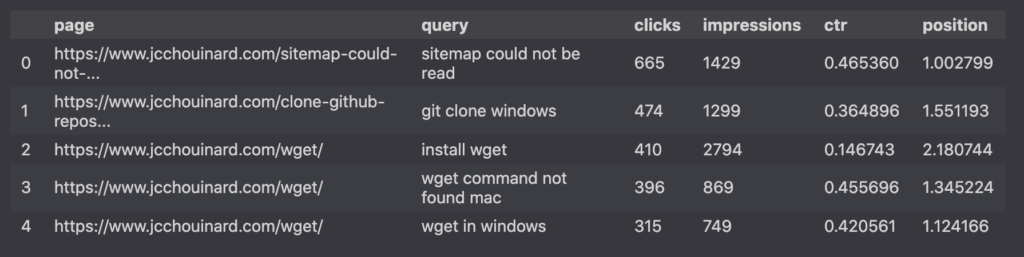
The data above was extracted using the Google Search Console API.
Data preprocessing
Pages shown in the Search Console Performance report are often untidy.
We can find:
- Pages can contain parameters or fragments. These are essentially the same page and need to be grouped together.
- Category, tags or paginated series are not useful to categorize here.
Thus, we’ll perform data preprocessing.
# Remove URLs with fragments and parameters
df['page'] = df['page'].str.split('#').str[0]
df['page'] = df['page'].str.split('?').str[0]
# Remove wordpress paginated and category pages (optional)
df = df[~df['page'].str.contains('/page/')]
df = df[~df['page'].str.contains('/category/')]
# Group by page
grouped_df = df.groupby('page').agg({'query':list})
# Join all queries in a single string
grouped_df['queries'] = grouped_df['query'].apply(lambda x: ' '.join(x))
# Create a list of grouped queries
# for each page.
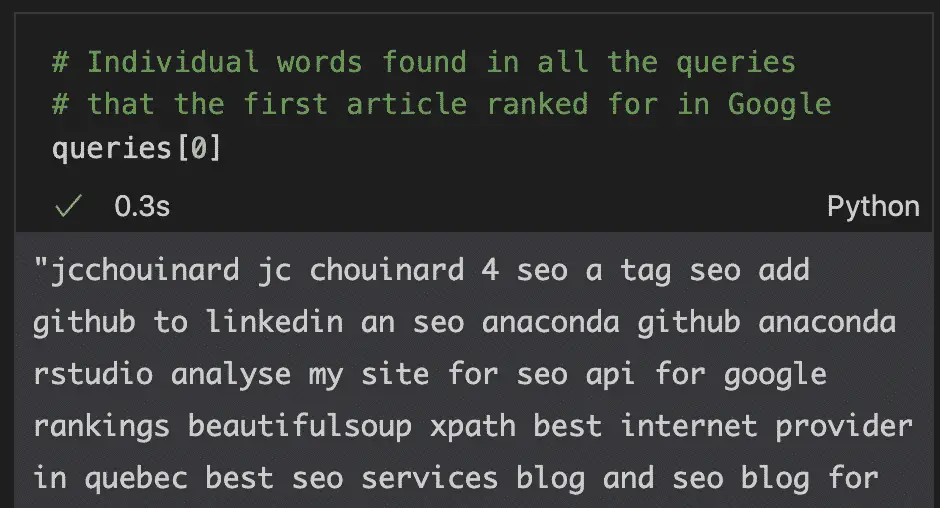
queries = list(grouped_df['queries'])
The result of the first element of the list is a large string with each word separated by a space. The 0 index represents the first page’s queries.
Combine the Words to TF-IDF vectors
A lot of machine learning algorithms do not work with categorical data.
This is true in the case of the KMeans clustering algorithm that we are going to use in the next part of the series.
Hence, we will need to convert the queries into numeric data.
We can do this operation using a natural language processing library from Scikit-learn: TfidfVectorizer.
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer(stop_words='english')
X = vec.fit_transform(queries)
tfidf_df = pd.DataFrame(
X.toarray(),
columns=vec.get_feature_names(),
index=grouped_df.index
)
tfidf_df
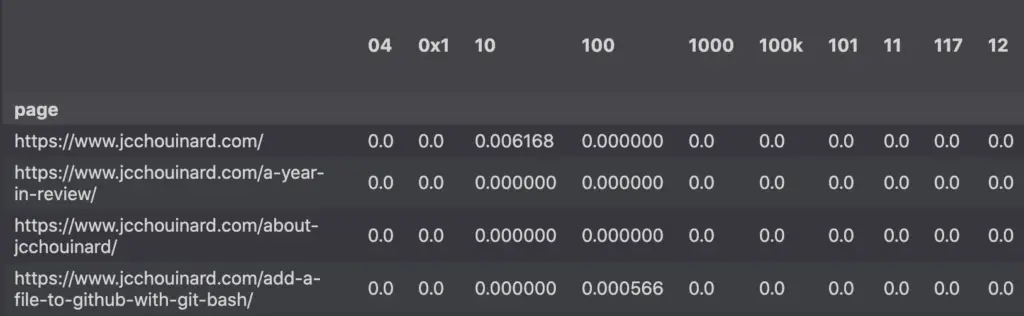
The result is a TF-IDF dataframe containing Google Search Console pages as the rows and the ngrams (words) as the columns. If you don’t understand the table below, just read my complete tutorial on Tf-IDF.
How to use the Google Search Console TF-IDF matrix?
Term-Frequency Inverse Document Frequency (TF-IDF) word vectors can be used to create recommender systems, information retrieval or text mining. In the next parts of this tutorial, we will use TF-IDF to group web pages together using KMeans.
Awesome resources on TF-IDF with Python
- SEO – Kmeans clustering by Konrad Burchardt
- Python for SEO using Google Search Console by Shrikar Archak
- How To Create A Powerful TF-IDF Keyword Research Tool by Billy Bonaros
- SEO Keyword Clustering with Python by Stephan Neefischer
Conclusion
Congratulations, you have created word vectors of all the queries in Google Search Console using Term-Frequency Inverse Document Frequency. It is now time to try one of the next tutorials to really understand why TF-IDF vectors are so important.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.