To lead the iris dataset in a Pandas DataFrame with Scikit-Learn and Python, use the load_iris() function from the sklearn.datasets module.
Here is how to load the Iris built-in dataset in Scikit-learn into a pandas Dataframe this way.
import pandas as pd
from sklearn import datasets
iris = datasets.load_iris()
df = pd.DataFrame(
iris.data,
columns=iris.feature_names
)
df['target'] = iris.target
# Map targets to target names
target_names = {
0:'setosa',
1:'versicolor',
2:'virginica'
}
df['target_names'] = df['target'].map(target_names)
df.head()
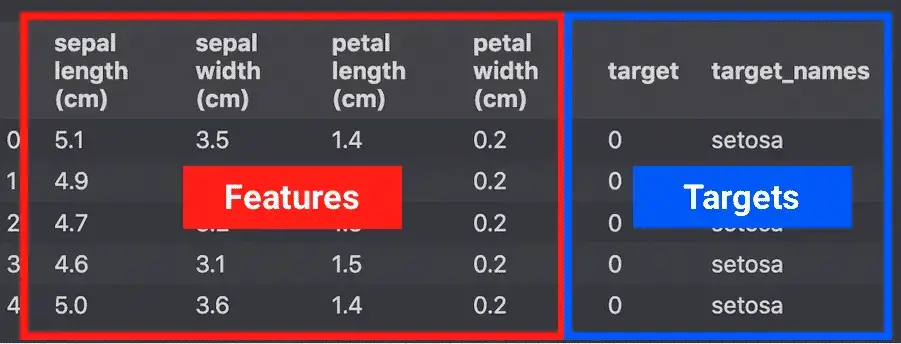
There are multiple projects using the Iris dataset with Python:
What is the Iris Dataset
The Iris dataset is a dataset often used in machine learning and statistics. It contains measurements of 150 iris flowers from three different species: setosa, versicolor, and virginica. Each species is described by four features: sepal length, sepal width, petal length, and petal width in centimetres.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.