Classification in machine learning is a supervised learning approach in which computer programs try to classify categorical data by observing and learning from observations (labelled data).
What is Classification in Machine Learning?
Classification is a predictive modelling approach used in supervised learning that predicts class labels based on a set of labelled observations.
Types of Machine Learning Classifiers
Classification algorithms can be separated into two types: lazy learners and eager learners.
Lazy learners
Lazy learning is a learning method that stores training data and waits to be given test data to start classifying (learning). wait for are used in recommendation
Lazy learners:
- Take less time learning (fitting)
- Take more time classifying data (predicting)
Examples of lazy learners:
- Case-base reasoning
- k-Nearest Neighbors
Eager learners
Eager learning systems start classifying when it receives training data without waiting for test data.
Eager learners:
- Take more time learning (fitting)
- Take less time classifying data (predicting)
Examples of eager learners:
- Artificial Neural Networks
- Decision tree
- Naive Bayes
- Support Vector Machines
Tasks of Classifications
The most common tasks of classifications are:
- Binary Classification
- Multi-Class Classification
- Multi-Label Classification
- Imbalanced Classification
Classification Methodology
- Read and explore data
- Proprocess data
- Split data into features and targets variables (independent and dependent)
- Split data into training and testing datasets
- Choose multiple algorithms and their ideal hyperparameters to train the model on (KNN, Decision tree, SVM, etc)
- Train the model on each algorithm
- Evaluate each model
- Select the most accurate classifier.
Classification Algorithms
In this post, we will have a look at some of the most popular classifications algorithms:
- k-Nearest Neighbors
- Logistic regression
- Decision tree
- Random forest
- Support Vector Classification (SVC)
There are a lot more types of classification algorithms not covered in this post. Here are a few:
- Naive Bayes
- Case-based reasoning
- Stochastic Gradient Descent
- Artificial Neural Networks
K-Nearest Neighbors
k-Nearest Neighbors is a machine learning algorithm used in supervised learning to predict the label of data points by looking what is the majority in its closest neighbours.
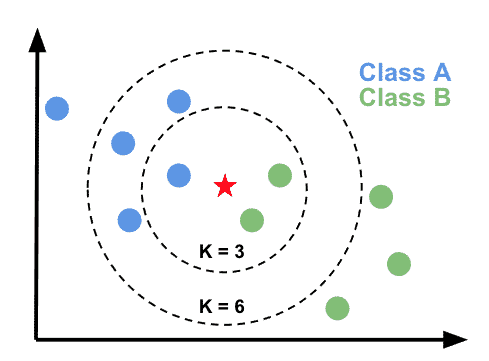
Some KNN classification algorithms are:
KNeighborsClassifierinsklearn.neighbors
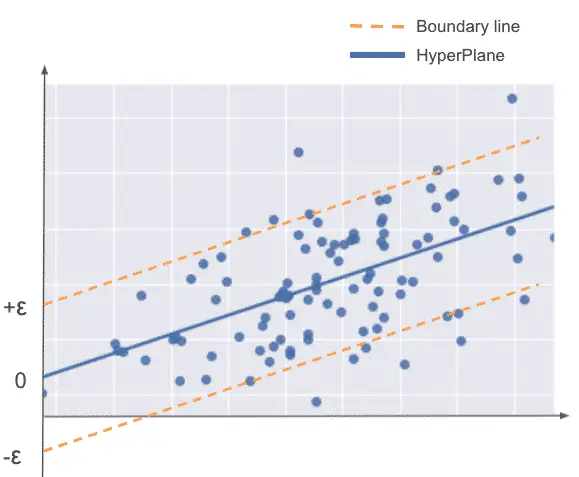
Logistic Regression
Although the name logistic regression can seem misleading, it can be used for classification problems. In logistic regression, the predicted value will be given from the highest probability of getting that value.
It is estimated using the Maximum Likelihood Estimation (MLE) approach.
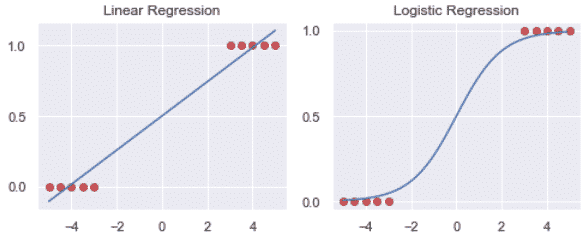
We can see above how the logistic regression may be a better fit to the data than the linear regression.
Some logistic regression classification algorithms are:
LogisticRegressioninsklearn.linear_model
Decision Trees Classification
The decision tree classification is based on the decision tree algorithm.
Decision trees are predictive models that use simple binary rules to predict the value of a target variable.
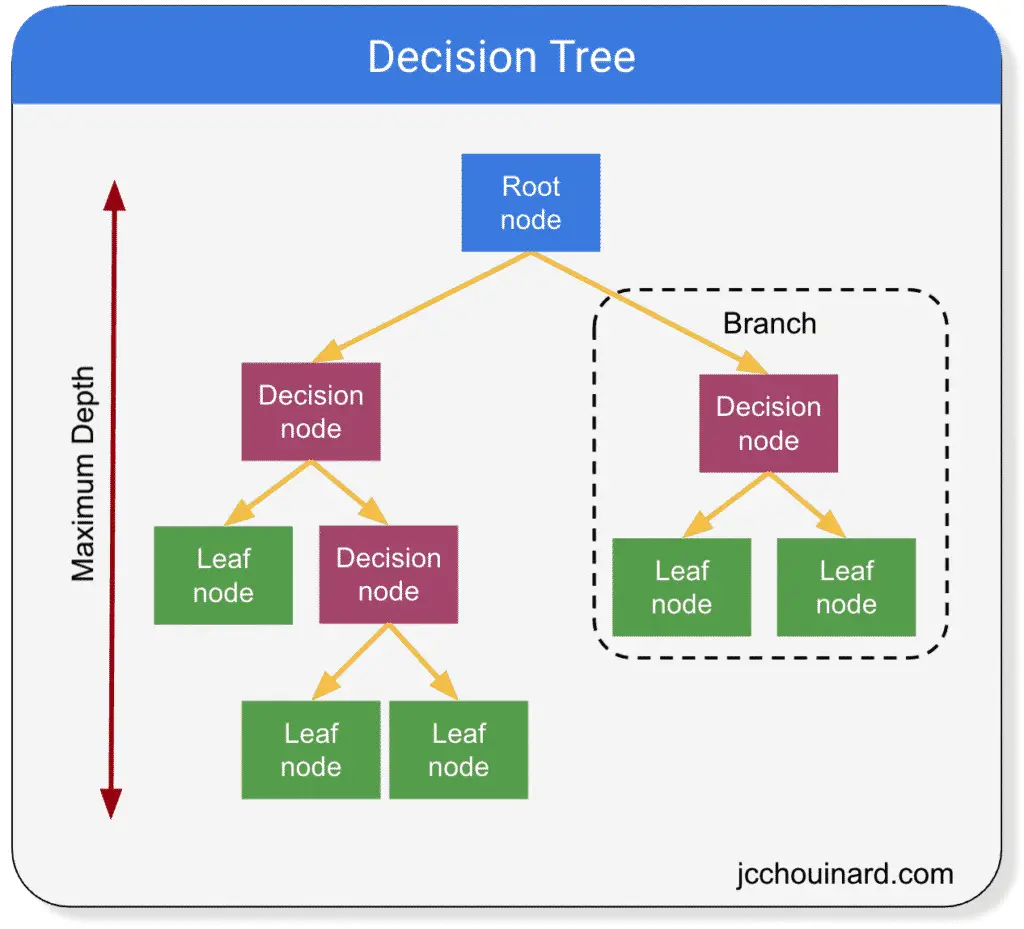
Decision trees can be used for both classification and regression.
They are models containing branches, nodes and leaves. They split a dataset into smaller parts containing similar elements. Decision trees fit a sine curve to the data to define the rules of the classification or the regression.
Some decision trees classification algorithms are:
DecisionTreeClassifierinsklearn.tree
Random Forest Classification
The random forest classification is a simple and highly accurate ensemble machine learning algorithm that calculates the average prediction of multiple decision trees.
Random forest is both a supervised learning algorithm and an ensemble algorithm.
Random forest takes in the n_estimators hyperparameter to define the number of decision trees to generate for the model.
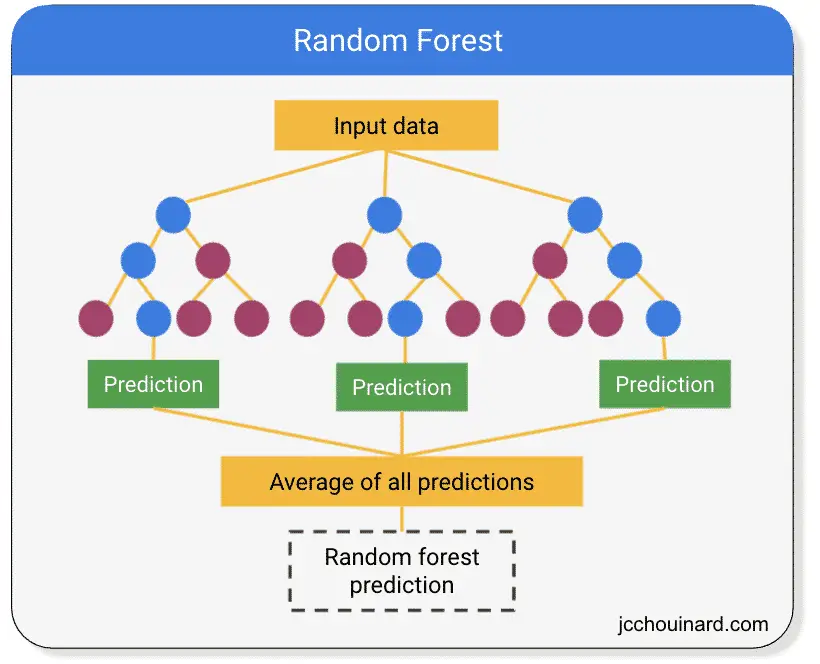
Some Random Forests classification algorithms are:
RandomForestClassifierfromsklearn.ensemble
Support Vector Classification (SVC)
The support vector classification (SVC) is a statistical method that uses the principles of Support Vector Machine (SVM) algorithms to examine the linear relationship between two continuous variables.
Support vector machines can be used for regression and classification problems. When they are used for classification problems, it is called support vector classification.
It is estimated using the kernel methods.
Some SVM classification algorithms are:
SVCfromsklearn.svm
Make a Classification with Scikit-learn
In the next tutorial, with Python, we will make a machine learning classification project with Sciki-learn on the Titanic dataset.
We will cover:
- Exploratory data analysis (EDA)
- Data preprocessing
- Feature engineering
- Hyperparameter tuning
- Model evaluation
- Model selection
We will also compare 5 different Scikit-learn classification models:
- LogisticRegression
- KNeighborsClassifier
- SVC
- RandomForestClassifier
- DecisionTreeClassifier
How To Make a Classification in Machine Learning
To classify data in Scikit-Learn using Python, you must process the data, train multiple classification algorithms and evaluate each model to find the classification algorithm that is the best predictor for your data
- Load data
You can load any labelled dataset that you want to predict on. For instance, you can use
fetch_openml('titanic')on the Titanic dataset to practice. - Explore the dataset
Use python pandas functions such as
df.describe()anddf.isnull().sum()to find how your data need to be processed prior training - Preprocess data
Drop, fill or impute missing, or unwanted values from your dataset to make sure that you don’t introduce errors or bias into your data. Use pandas
get_dummies(),drop(), andfillna()functions alongside some sklearn’s libraries such asSimpleImputerorOneHotEncoderto preprocess your data. - Split data into training and testing dataset
To be able to evaluate the accuracy of your models, split your data into training and testing sets using sklearn’s
train_test_split. This will allow to train your data on the training set and predict and evaluate on the testing set. - Create a pipeline to train multiple classification algorithms and hyper-parameters
Run multiple algorithms, and for each algorithm, try various hyper-parameters. This will allow to find the best performing model and the best parameters for that model. Use
GridSearchCV()andPipelineto help you with these tasks - Evaluate the machine learning model
Evaluate the model on its precision and recall with methods such as the accuracy() or accuracy_score() and evaluate elements such as the confusion_matrix()
Example Classification in Python with Scikit-Learn
In the following Python example, we will perform a DecisionTreeClassifier() classification on the Iris dataset from the Scikit-learn librarr.
The steps below splits the data into training and testing groups and then scale the data using the StandardScaler() class.
Then, we perform hyperparameter tuning using GridSearchCV() and then fit the parameter variations to the model.
# Import necessary libraries
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.utils.multiclass import unique_labels
# Load the Iris dataset
iris = datasets.load_iris()
X = iris.data # Features
y = iris.target # Target variable (class labels)
# Split the dataset into a training set and a testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Data preprocessing: Standardize features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Initialize the Decision Tree classifier
clf = DecisionTreeClassifier()
# Define hyperparameters for tuning
param_grid = {
'criterion': ['gini', 'entropy'],
'max_depth': [None, 5, 10, 15],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# Hyperparameter tuning using GridSearchCV
grid_search = GridSearchCV(clf, param_grid, cv=5, n_jobs=-1)
grid_search.fit(X_train, y_train)
# Get the best classifier from hyperparameter tuning
best_clf = grid_search.best_estimator_
# Fit the best classifier to the training data
best_clf.fit(X_train, y_train)
# Make predictions on the testing data
y_pred = best_clf.predict(X_test)
We then evaluate the model.
# Model evaluation
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred, target_names=iris.target_names)
conf_matrix = confusion_matrix(y_test, y_pred)
Then, we print the best parameters, the accuracy and the classification report. Here, since the Iris dataset is a clean dataset, the precision and recall is perfect.
print(f'Best Model Parameters: {grid_search.best_params_}')
print(f'Accuracy: {accuracy:.2f}')
print('Classification Report:')
print(classification_rep)
Output
Best Model Parameters: {'criterion': 'gini', 'max_depth': None, 'min_samples_leaf': 1, 'min_samples_split': 10}
Accuracy: 1.00
Classification Report:
precision recall f1-score support
setosa 1.00 1.00 1.00 19
versicolor 1.00 1.00 1.00 13
virginica 1.00 1.00 1.00 13
accuracy 1.00 45
macro avg 1.00 1.00 1.00 45
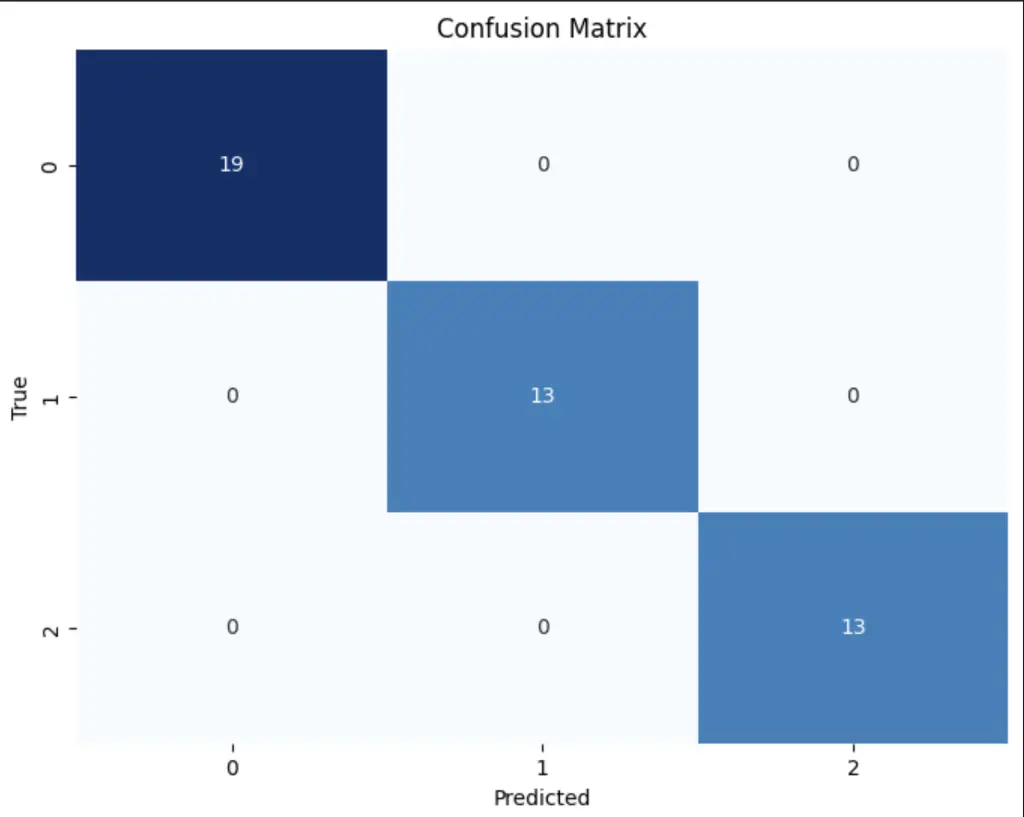
weighted avg 1.00 1.00 1.00 45Finally, we plot the confusion matrix using a heatmap.
# Plot the confusion matrix
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
Classification and Machine Learning Definitions
| Classification in machine learning | Process of categorizing a given set of data into classes |
| Types of classifiers algorithms | Lazy learners and eager learners |
| Classification algorithms | k-Nearest Neighbors, Logistic regression, Decision trees, Random forest, Support Vector Classification (SVC) and more |
| Classifications are used in | Classification are a Supervised learning approach |
| Libraries used for classification | Scikit-learn is a popular library in classification |
Conclusion
We have seen an overview of machine learning classification and covered the basic classification algorithms. Next, we will look at regression in machine learning.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.