In Python, train_test_split is a function in the model_selection module of the popular machine learning library scikit-learn. This function is used to perform the train test split procedures, which splits a dataset into two subsets: a training set and a test set.
train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)Here is a tutorial on how to use the train_test_split function.
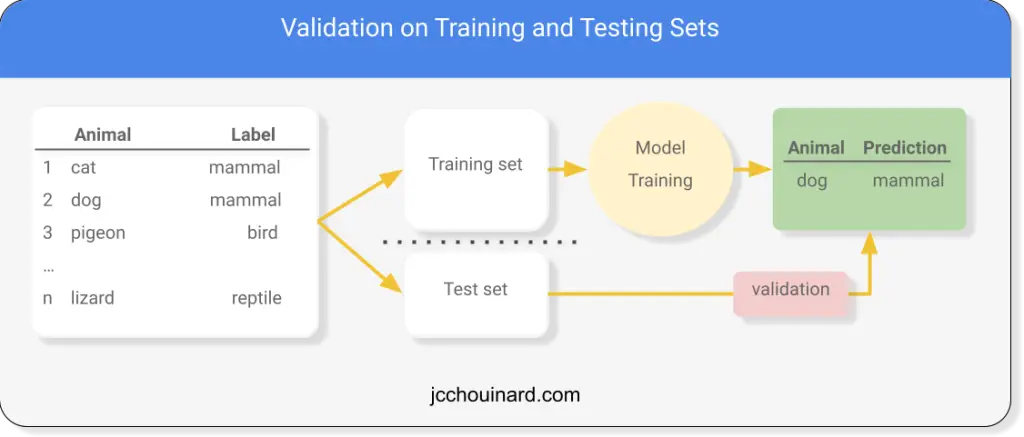
What is train_test_split in Machine Learning
In Scikit-learn, train_test_split is a function used to create training and testing data to be used to measure a machine learning model’s performance.
Why Use Train Test Split in Machine Learning?
In machine learning, we often build or train models on a single dataset. To evaluate if a machine learning model is doing as expected, we need to train the model on one portion of the dataset, and compare how accurately the predictions map to the real-world data.
To evaluate the accuracy of machine learning models, data scientists need to split datasets in two portions called:
- training data (train the model)
- testing set (test the model)
They do so using functions like the train_test_split function from the Scikit-learn library.
How to Split Data into a Training and Testing Set in Python
To split data into a training and testing set in Python, use the train_test_split function of the Scikit-learn library. Pass the arrays of data to be split as arguments of the function.
Train_test_split in Scikit-learn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
How Does Train Test Split Work?
To evaluate how a model would perform on unseen data, train_test_split separates data into a training set and a testing set. A machine learning model (e.g. classifier such as KNN) is then trained on the training set. After, a prediction is made on the trained dataset. Finally, the prediction is compared against the real data from the test set in order to compute the accuracy of the predictions.
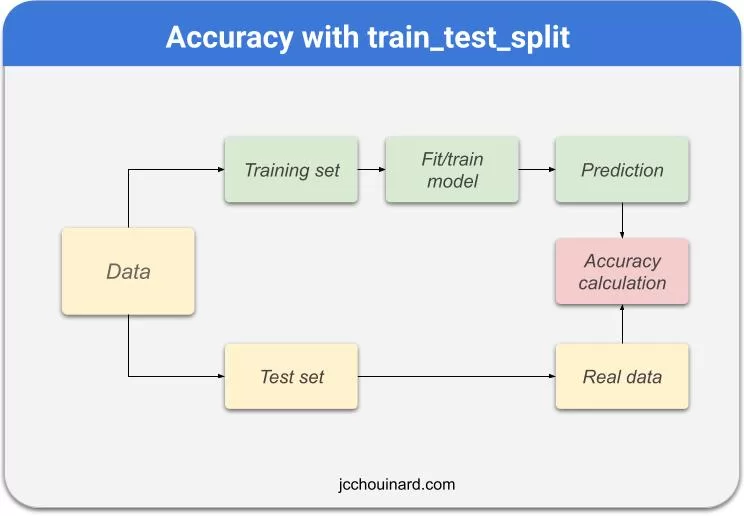
Here is a breakdown of how to use train_test_split
How to Use Train Test Split
- Split a dataset into a training and testing set
- Provide the testing size with the test_size parameter
- Train a model on the training set
- Make predictions on the training set
- Compute the accuracy with a metrics such as the accuracy or accuracy_score
What is Accuracy in Machine Learning
The accuracy is an evaluation metric often used in machine learning to evaluate a model performance.
The accuracy is a ratio of correct predictions divided by the number of total observations.
correct predictions / total observationsHow Train Test Split Helps Calculate Accuracy
When training a machine learning, you cannot evaluate the accuracy on the training data or else you will overestimate the accuracy of your model. To properly evaluate the accuracy with train_test_split, we split the model into a training (e.g. 60%) and testing set (e.g. 40%), train the model on the former subset and evaluate the performance on the latter.
Train Test Split in Python
In Python, train_test_split is a function from the model_selection module of the Scikit-learn library. It is used to split arrays or matrices into random train and test subsets.
train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)We will explain later in this article the Scikit-learn train_test_split parameters.
Install Scikit-Learn
To use train_test_split, you will need to install scikit-learn if you don’t have it already.
You can install it by opening the Terminal and using:
$ pip install scikit-learn
Import train_test_split
Next, you will need to import the train_test_split function from the model_selection module. You can do this by adding the following line of code at the top of your script:
from sklearn.model_selection import train_test_split
Load Your Dataset
Load your dataset using Scikit-learn’s datasets module and split the features and targets variables.
import pandas as pd
from sklearn import datasets
# Load Dataset
dataset = datasets.load_breast_cancer()
df = pd.DataFrame(dataset.data,columns=dataset.feature_names)
df['target'] = pd.Series(dataset.target)
# Define independent (features) and dependent (targets) variables
X = dataset['data']
y = dataset['target']
Train test split on a Pandas Dataframe
Scikit-learn’s train_test_split takes array-like structures as parameters, which means that a Pandas DataFrame has to be converted to pandas Series to be passed to the function. Hence why we passed the dataset['data'] and dataset['target'] series to the X and y variables, which both have this array-like structure.
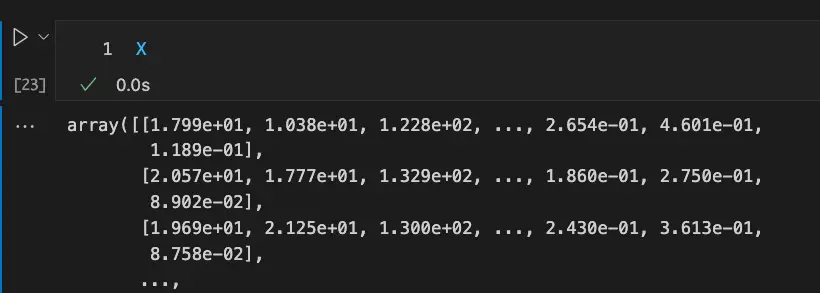
Split into Training and Testing Sets
Use train_test_split to split the dataset into training and testing sets. Pass the X and y features and targets to the function as well as your test size of 30%. Stratify is used to keep the same proportions as the initial dataset. Random state is used to enable reproducible results.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
What is the Optimal Train_test_split Ratio
The optimal train-test split ratio depends on various factors, including the size of the dataset, the complexity of the problem, and the availability of data.
If you have a large dataset, you can allocate a larger proportion for testing without reducing the training data too much. A common option is to use a 70/30 or 80/20 split on the training/testing ratio. Even better, use cross validation.
If you have limited data, it is better to allocate a larger portion to the training set to allow the model to learn better. A 90/10 split might be better to make sure that you have enough training data.
Train a Machine Learning Classifier on the Training Set
Perform a classification by fitting (training) a KNearestNeighborsClassifier on the training set. Use the fit() method on the object and pass the X_train and y_train data as arguments.
from sklearn.neighbors import KNeighborsClassifier
# train the model
knn = KNeighborsClassifier(n_neighbors=8)
knn.fit(X_train, y_train)
Make Predictions on the Trained Data
Use the predict() method on the knn object and pass X_test array-like data as the argument to the method. The predict() method will predict the class labels for the provided X_test data sample.
# Make prediction
y_pred = knn.predict(X_test)
Measure Train_test_split Model Performance (Accuracy)
Use the score() method to return the mean accuracy of the provided test data and predicted labels. Pass the X_test and y_test data to the method so that the trained model with make predictions on X_test and compare them to the y_test real data.
# compute accuracy of the model
knn.score(X_test, y_test)
0.9298245614035088Compute the Confusion Matrix
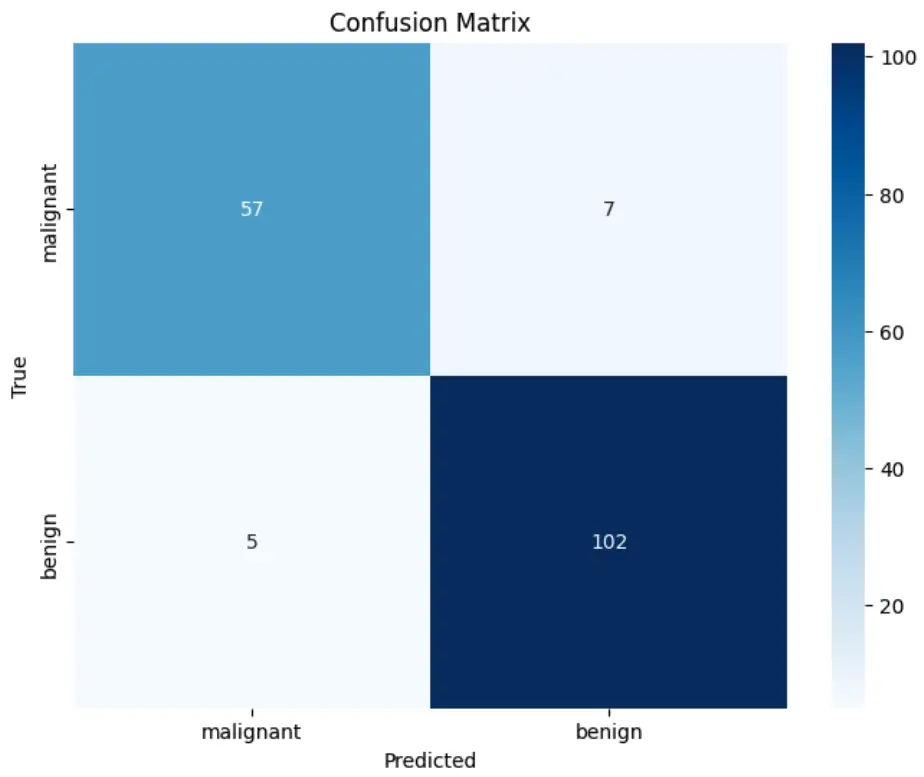
Last, compute the confusion matrix to visualize the counts of true positives, true negatives, false positives, and false negatives, and gain insights into the model’s accuracy. Use Seaborn and Matplotlib to plot the confusion matrix as a heatmap.
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# Create confusion matrix
cm = confusion_matrix(y_test, y_pred)
# Visualize confusion matrix
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, cmap="Blues", fmt="d", xticklabels=dataset.target_names, yticklabels=dataset.target_names)
plt.title("Confusion Matrix")
plt.xlabel("Predicted")
plt.ylabel("True")
plt.show()
Train_test_split Python Example
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
# Load Dataset
dataset = datasets.load_breast_cancer()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df['target'] = pd.Series(dataset.target)
# Define independent (features) and dependent (targets) variables
X = dataset['data']
y = dataset['target']
# Split training and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
# Train the model
knn = KNeighborsClassifier(n_neighbors=8)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
# Compute accuracy of the model
accuracy = knn.score(X_test, y_test)
print("Accuracy:", accuracy)
# Create confusion matrix
cm = confusion_matrix(y_test, y_pred)
# Visualize confusion matrix
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, cmap="Blues", fmt="d", xticklabels=dataset.target_names, yticklabels=dataset.target_names)
plt.title("Confusion Matrix")
plt.xlabel("Predicted")
plt.ylabel("True")
plt.show()
Train_Test_Split Parameters
The train_test_split function can be used with 5 parameters: test_size, train_size, random_state, shuffle and stratify.
| train_test_split Parameters | Description | Options/Values | Default |
|---|---|---|---|
| test_size | Size of the testing subset | Float (0.0 to 1.0) or int | 0.25 |
| train_size | Size of the training subset | Float (0.0 to 1.0) or int | None |
| random_state | Random seed for reproducibility | int or RandomState instance | None |
| shuffle | Whether to shuffle the data before splitting | bool | True |
| stratify | Array-like or None. If not None, split data in a stratified fashion | array-like or None | None |
*arrays in train_test_split
Sequence of indexables with same length / shape[0].
Allowed inputs are lists, numpy arrays, scipy-spars matrices or pandas dataframes.
test_size in train_test_split
In train_test_split(), the test_size parameter defines the percentage of the full dataset that should be used as a test set.
float or int, default=NoneIf float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the test split. If int, represents the absolute number of test samples. If None, the value is set to the complement of the train size. If train_size is also None, it will be set to 0.25.
train_size in train_test_split
In train_test_split(), the train_size parameter defines the percentage of the full dataset that should be used as a training set.
float or int, default=NoneIf float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples. If None,
random_state in train_test_split
In train_test_split(), the random_state parameter controls the shuffling applied to the data before applying the split. It passes an int used for reproducible output across multiple function calls.
int, RandomState instance or None, default=Noneshuffle in train_test_split
In train_test_split(), the shuffle parameter is used to define whether or not to shuffle the data before splitting.
bool, default=TrueIf shuffle=False, then stratify must be None.
stratify in train_test_split
In train_test_split(), the stratify parameter splits the dataset in a way that the proportion of values in the sample will be the same as the proportion provided with this parameter.
array-like, default=NoneAdvantages and Disadvantages of Train_test_split
The advantages of train_test_split is that it is simple, allows to evaluate how well a model generalizes to unseen data and allows to quickly iterate and assess the model performance by comparing results on different test sets.
The disadvantages of train_test_split is that there is a risk of overfitting the model to the test set, it limits the available data to train the model as it is allocated for testing and introduces variability in the performance depending how the data is split into training and testing sets (e.g. different shuffling = different results).
Alternative to Train Test Split
An alternative to the train_test_split function is using cross-validation (such as K-Fold or Stratified Cross-Validation). Cross-validation involves splitting the dataset into multiple subsets and iterate over each subset as both a training and testing set. It provides a more robust evaluation of the model’s performance by utilizing the entire dataset for training and testing.
How to Split into Training and Testing Sets without Scikit-learn
It is possible to split data into training and testing sets without using Scikit-learn’s train_test_split function, but using Numpy instead.
import numpy as np
# Assuming your data is stored in X (features) and y (labels) arrays
# Set a random seed for reproducibility
np.random.seed(42)
# Shuffle the indices of the data
indices = np.arange(len(X))
np.random.shuffle(indices)
# Define the ratio or number of samples for the testing set
test_ratio = 0.2 # For example, using 20% of the data for testing
# Calculate the number of samples for the testing set
test_size = int(len(X) * test_ratio)
# Split the indices into training and testing sets
train_indices = indices[:-test_size]
test_indices = indices[-test_size:]
# Split the data into training and testing sets based on the indices
X_train, y_train = X[train_indices], y[train_indices]
X_test, y_test = X[test_indices], y[test_indices]
Conclusion
We have now covered how to use train_test_split in the evaluation of machine learning model performance and have covered the main parameters of the function and finally made a Python example using train_test_split to fit a model on a training dataset and compute the accuracy of a model.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.