TF-IDF, or term frequency-inverse document frequency, is a statistical measure used in Natural Language Processing and Information Retrieval that evaluates how relevant is a word in a document relative to a corpus of documents.
TF-IDF uses text vectorization to transform words from a document into numerical values.
How is TF-IDF is Calculated?
TF-IDF is essentially the multiplication of the Term Frequency (TF) and the inverse document frequency (IDF).

TF-IDF = TF * IDFSimply put, the importance of a term in TF-IDF is higher when the term occurs a lot in a document, and not often in others (how important is the term for that specific document, compared to all others).
To understand TF-IDF (term frequency-inverse document frequency) and how it evaluates word relevancy, we need to understand its individual parts.
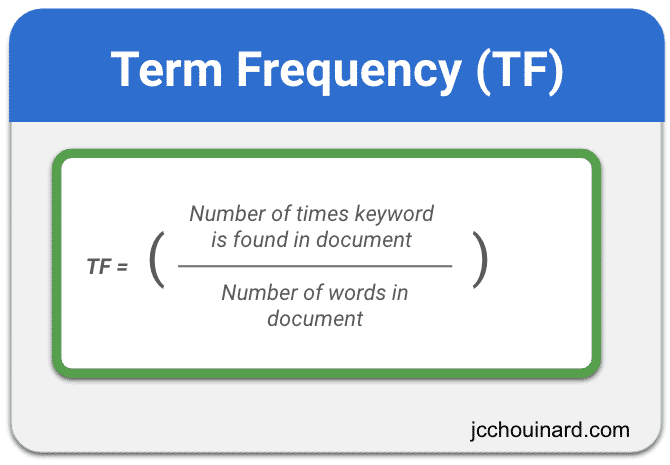
Calculating the Term Frequency in TF-IDF
Term frequency is the frequency of a keyword compared to the number of words in a document. It is calculated using the number of times a word is found in a document divided by the number of words in the document.
Document Frequency
Document frequency is the number of documents in which the keyword appears.
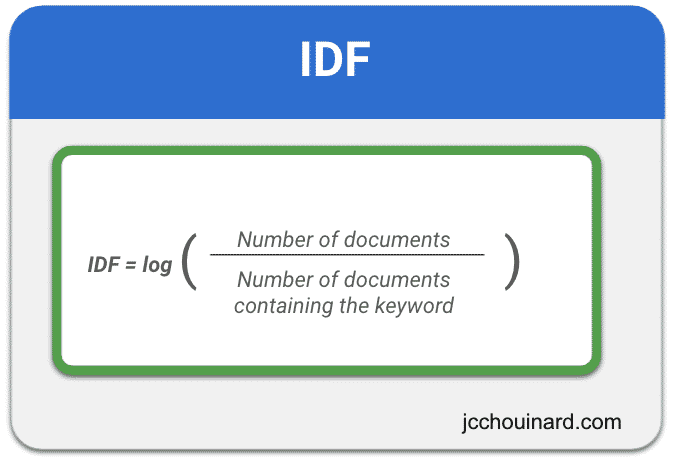
Calculating the Inverse Document Frequency in TF-IDF
Inverse document frequency (IDF) is a dampening factor invented by Sparck Jones used to reduce the importance of queries that are common to a lot of documents.
IDF is calculated by computing the log() of the result of the division between the Number of documents and the number of documents that contain the target word.
Let’s look at the importance of certain queries for an article on Unsupervised machine Learning.
Queries like “about” or “but” will be occurring a lot in the article. Does it mean that the article is about these prepositions? Surely not. This is what IDF is used for. When
When a keyword appears in a large number of documents (e.g. “a”, “the”, “they”), it is considered less important to a specific document.
When the keyword rarely occurs across all documents (e.g. query like Dimensionality reduction), it will be considered higher relevancy to the documents in which it appears.
Examples When to Use TF-IDF?
The TF-IDF measure is often used in Natural Language Processing applications:
- Search engines ranking the relevance of a document for a query
- Text clustering and classification
- Topic Modelling
Example of How TF-IDF Works
TF-IDF works by multiplying the Term Frequency with the Inverse Document Frequency. We have seen how each component is calculated and let’s view an example to illustrate how TF-IDF is calculated for a corpus of documents:
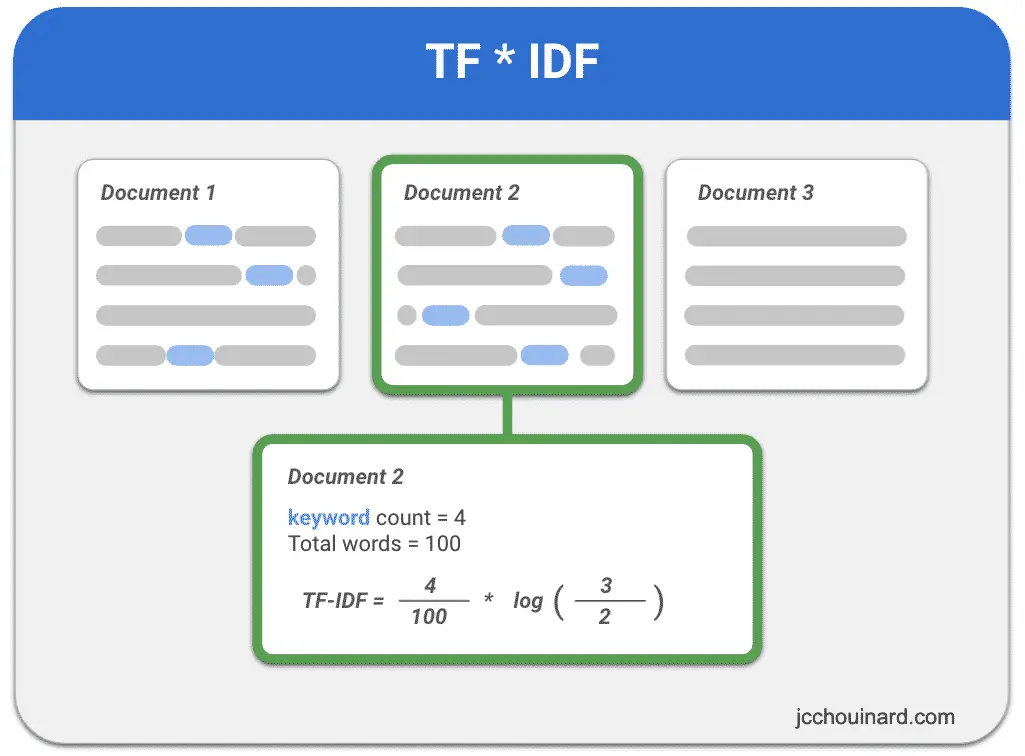
In the example below:
- we have 3 documents
- only 2 contain a certain keyword.
- the keyword appears 4 times in a 100 words document.
TF-IDF will be equal to the keyword count (4) divided by the number of words in the document (100) multiplied by the IDF dampening factor. That factor will be the log of the number of documents (3) divided by the number of documents containing the keyword (2).
TF-IDF Example with Python and Scikit-Learn
The Python machine learning library Sklearn has the TfidfVectorizer() function to help apply TF-IDF to a corpus of text.
Here we will use TfidfVectorizer to apply TF-IDF to Wikipedia articles.
For simplicity, we will not apply text preprocessing operations such as removing stop words and punctuation and stemming.
The first step is to query the Wikipedia API.
import requests
articles = []
wiki_pages = [
'Machine learning',
'Artificial intelligence',
'Neural networks'
]
for subject in wiki_pages:
url = 'https://en.wikipedia.org/w/api.php'
params = {
'action': 'query',
'format': 'json',
'titles': subject,
'prop': 'extracts',
'exintro': True,
'explaintext': True,
}
response = requests.get(url, params=params)
data = response.json()
page = next(iter(data['query']['pages'].values()))
articles.append(page['extract'])
The next step is to build the dataframe from the list of articles stored in the articles variable.
There are two main ways to build a TF-IDF word frequency Dataframe with Scikit-learn:
- Using
TfidfVectorizer - Using
CountVectorizerfollowed byTfidfTransformer
Either of these solutions will create a sparse matrix that can be used to create the Pandas Dataframe.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
# Initialize the model
vec = TfidfVectorizer()
# Train the model
tf_idf = vec.fit_transform(articles)
# Print the tf-idf sparse matrix
print(tf_idf)
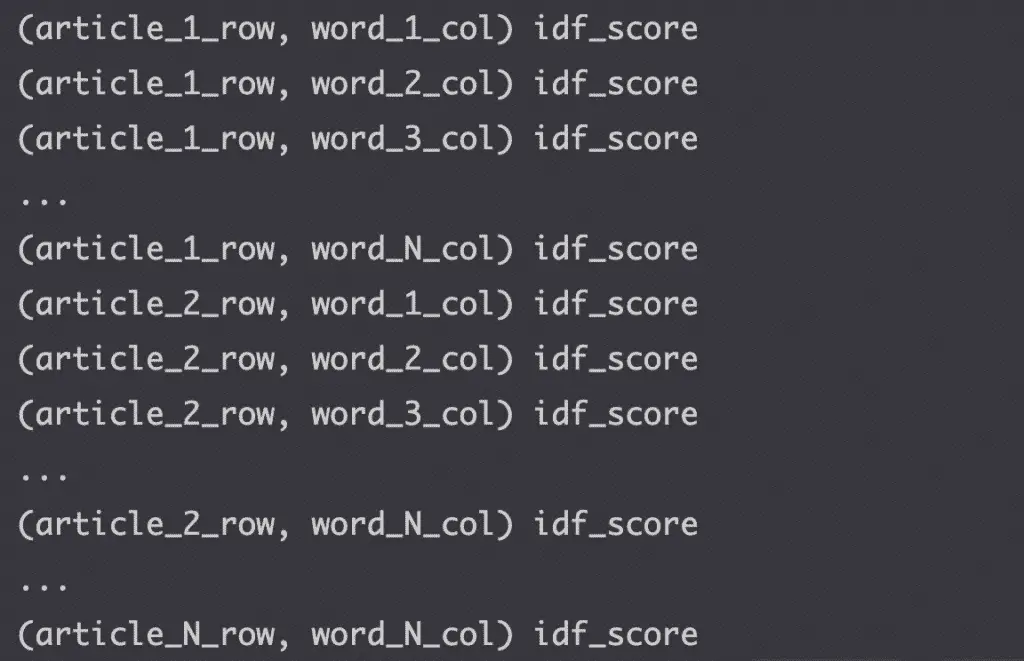
The sparse matrix will have a structure like the one below. The tuples represent the row and column location, followed by the idf score.
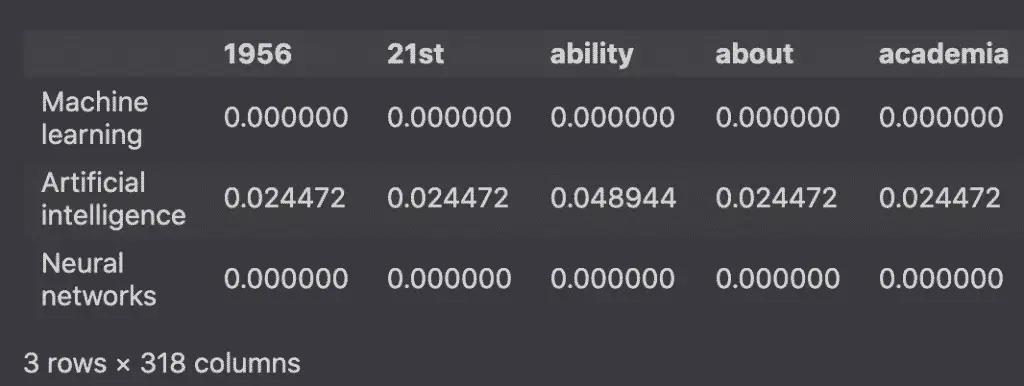
From the sparse matrix, we build the word frequency dataframe.
df = pd.DataFrame(
tf_idf.toarray(),
columns=vec.get_feature_names(),
index=wiki_pages
)
df.head()
How to Use TF-IDF on real world data?
If you want to dive deeper into TF-IDF:
- Wikipedia Recommender System with TF-IDF and NMF in Scikit-learn (Search Engine Journal)
- TF-IDF on Google Search Console Data
- Clustering and De-duplication of web pages using KMeans and TF-IDF
Conclusion
This concludes the article on how to estimate the relevancy of a word using the term frequency-inverse document frequency (TF-IDF).

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.