In this tutorial, we will learn what regular expressions are and how to use them to process text.
Navigation
Show
What are Regular Expressions (RegEx)
Regular expressions, also known as RegEx, is a text processing technique that use special sequences of characters to specify match patterns in text.
Getting Started with Regular Expressions
Regular expressions are used to match text patterns in various ways.
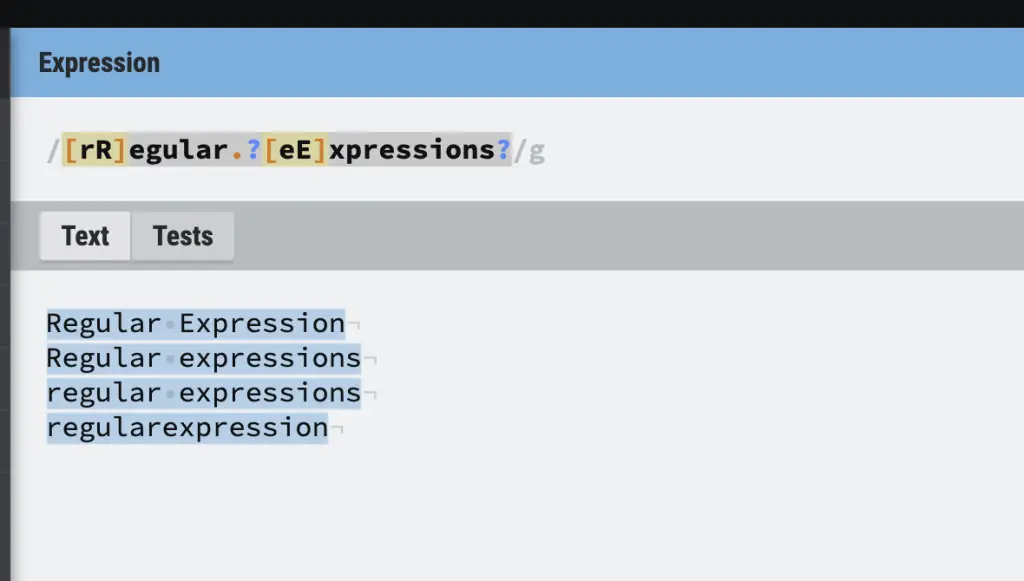
For example, we can process the following strings that have different casing, plural forms or whitespaces by using regular expressions.
- Regular Expression
- Regular expressions
- regular expressions
- regularexpression
For instance, the following RegEx would above strings
[rR]egular.?[eE]xpressions?Regular Expression Tools
There are a number of tools to help you with regular expressions such as Regexr or Regex101.
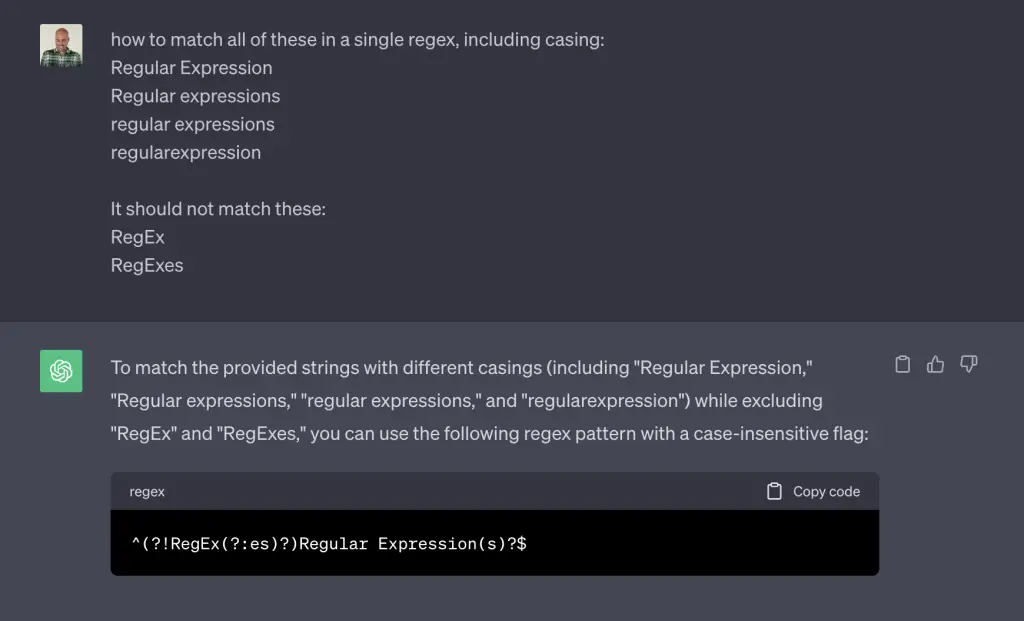
Another fantastic tool is ChatGPT that allows you lear generate regular expressions using natural language.
Building Blocks of a Regular Expression
Regular expressions are created using a combination of metacharacters and literal characters.
- A literal character is a regular character used to match itself. E.g. Using the letter “a” and the number “2” to respectively match the letter “a” and the number “2”.
- A meta character is a special character that has a meaning within the regular expression. E.g. Using the Dot (.) symbol to match any character or the caret (^) to match the beginning of a string.
Meta Characters in RegEx
Meta characters are what gives the full power to a regular expression.
Here is a table describing most common Regex meta characters.
| Meta Character | Description |
|---|---|
| \ | Escapes a regular expression meta character or marks a literal character as special. |
| | | Matches one expression OR the another |
| ( ) | Creates a match group |
| ? | Matches the last character 0 or 1 time |
| ^ | Matches the beginning of a string |
| $ | Matches the end of a string |
| * | Matches the last character zero or more times |
| + | Matches the last character one or more times |
| . | Matches any single characters |
| [ ] | Matches characters inside brackets |
| [^ ] | Matches anything except characters inside brackets |
| {n} | Matches n repetitions |
| \d | Matches a digit character |
| \s | Matches any whitespace character |
| \w | Matches any word character |
| \W | Matches any non-word character |
RegEx Disjunction
In regular expressions, a disjunction is used to specify multiple alternatives. For example, a disjunction of characters represents a string of characters inside brackets to specify a disjunction of characters to match.
With disjunctions, you can specify individual matching character (e.g [rR]), or character ranges (e.g. [A-Z]), or can even be combined (e.g. [a-zA-Z0-9]).
Individual Matching Characters in RegEx Disjunction
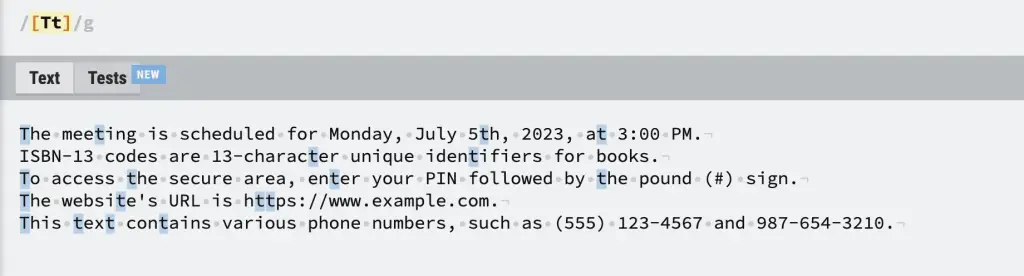
You can specify any individual characters in a Regular expression disjunction. For example, [Tt] would match any upper or lower case T/t.
Range Matching Characters in RegEx Disjunction
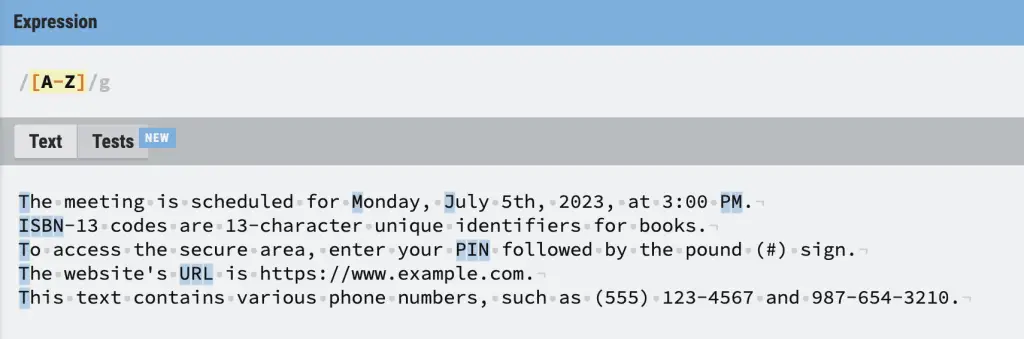
You can specify ranges of characters in a Regular expression disjunction. For example, [a-z] would match any character within the a-z range (e.g. a,b,c,..., z). The range means any character within that range.
Combined Range Matching Characters in RegEx Disjunction
You can combine ranges and individual characters in the regular expression disjunction. For example, the [a-zA-Z0-9] pattern specifies any alpha numeric character.
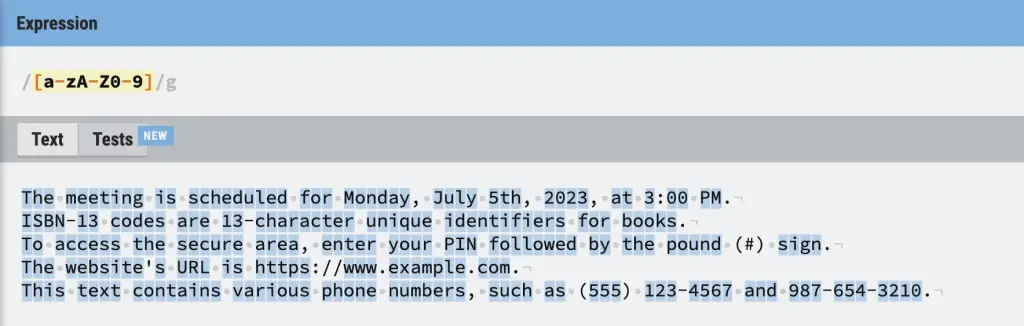
Negation Matching Characters in RegEx Disjunction
You can negate ranges or individual characters in a regular expression disjunction using the caret (^). For example, the [^a-zA-Z] pattern tries to match anything that is NOT a letter.
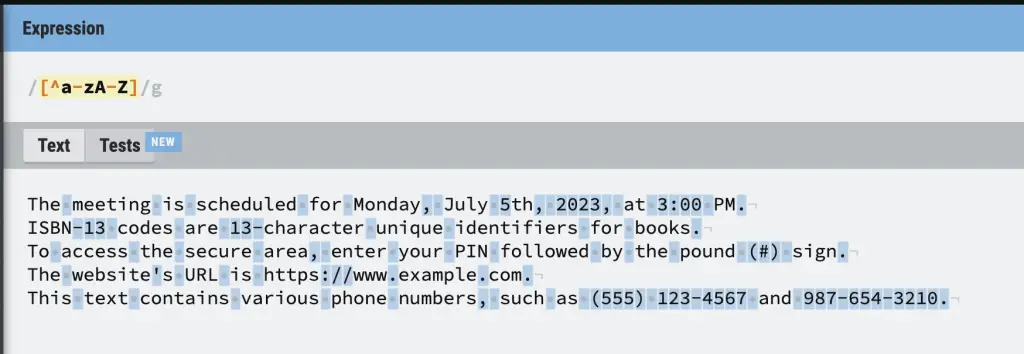
OR RegEx Disjunction (|)
The pipe symbol (|) is a regular expression disjunction that can be used to combine patterns. The pipe symbol allow to combine multiple patterns with the OR logic.
For example, the hello|world pattern matches both hello OR world. Another example is a|b|c does the same thing as [abc].
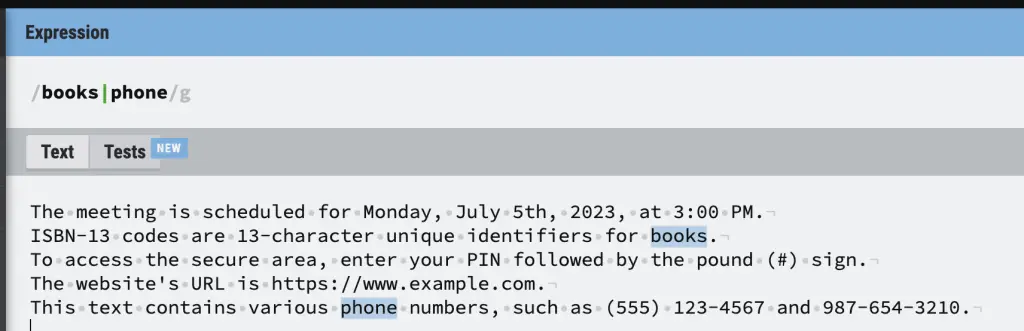
RegEx Disjunction Cheatsheet
Here is a table of regular expression disjunction patterns
| Pattern | RegEx Matches | Example |
|---|---|---|
| [rR]egex | Uppercase R or lowercase r | Regex, regex |
| [1234567890] | Any digit | 1 dog |
| [A-Z] | An upper case letter | Regular Expression |
| [a-z] | A lower case letter | hello |
| [0-9] | A single digit | Hello my 1 friend |
| [a-zA-Z0-9] | Any letter or number | a, B, 9 |
| [^A-Z] | Not upper case letter | Ozzy |
| [^Rr] | Neither R or r | Regular |
| dog|cat | Matches dog or cat |
Special Characters in Regular Expressions
There are special characters in regular expressions that will impact the string matching capabilities: wildcards, anchors, and boundaries.
Wildcards in Regular Expressions
Special characters in regular expressions known as wildcardscan match one or multiple character without explicitly saying what the character is:
- Dot (
.): Any character - Star (
*): 0 or more of previous character - Plus (
+): 1 or more of previous character - Question-mark (
?): Optional character
Dot in RegEx (.)
The dot (.) in regular expressions matches any character.
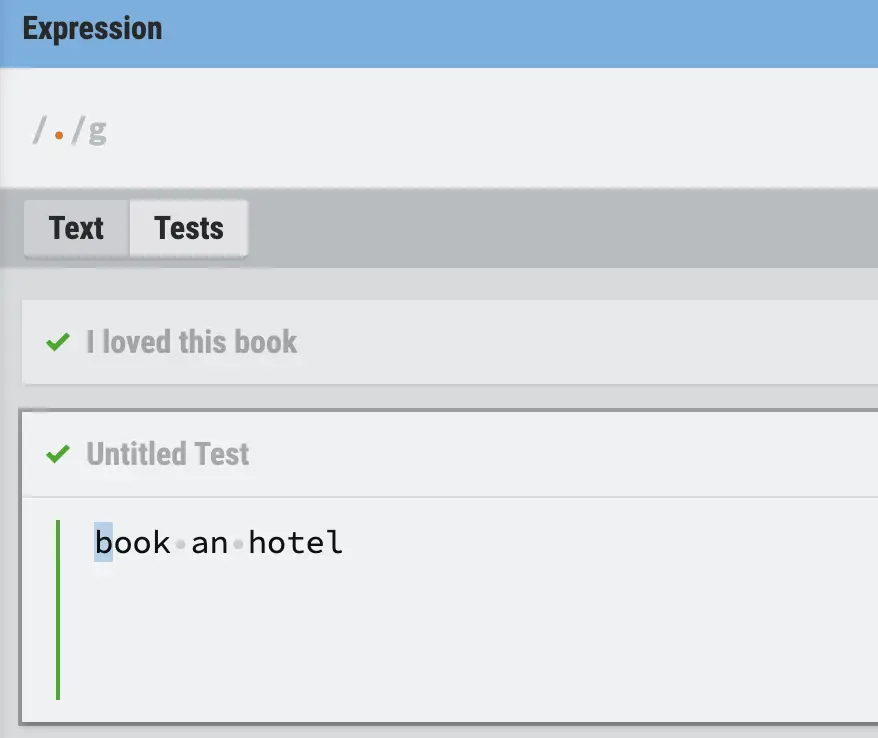
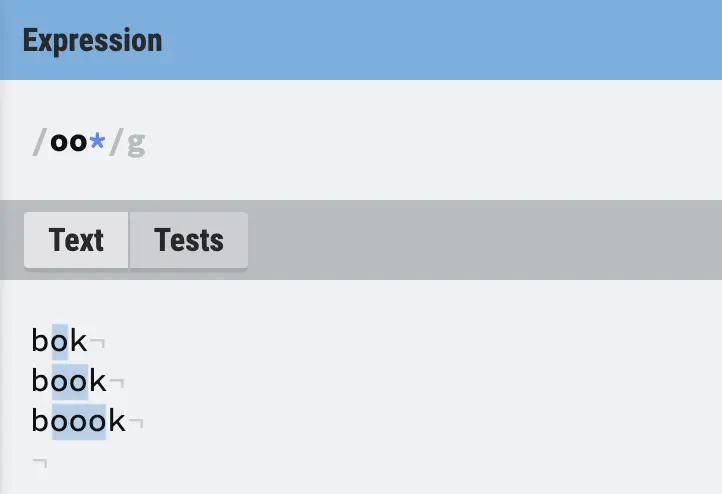
Star in RegEx (*)
The star (*) in regular expressions matches 0 or more of previous character.
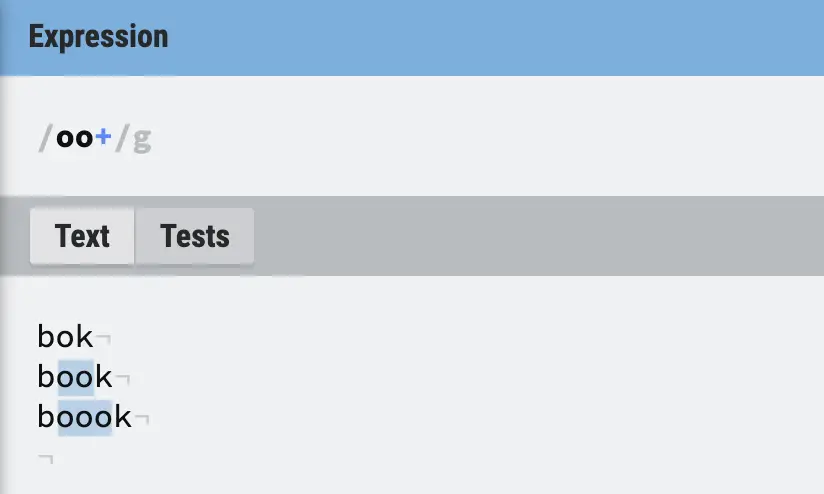
Plus in RegEx (+)
The plus (+) in regular expressions matches 1 or more of previous character
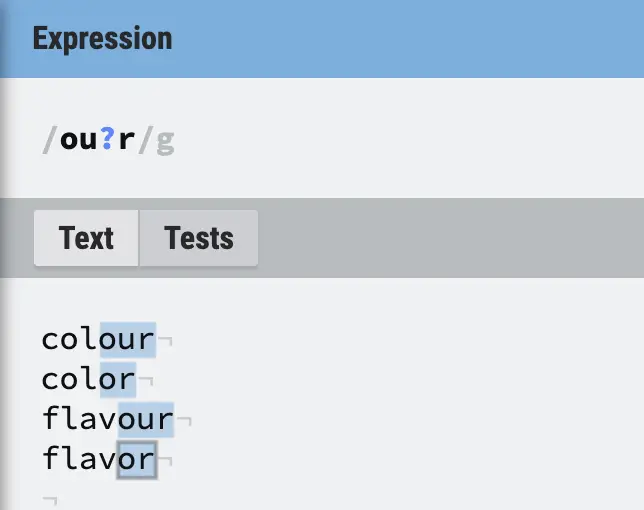
Question Mark in RegEx (?)
The question mark (?) in regular expressions defines a character as optional.
Anchors in Regular Expressions
Anchors, in regular expressions, belong to the family of regex tokens that don’t match characters, but that checks if the position in the string matches a location (e.g. the end of a string).
- Caret (^): Matches the start of a string
- Dollar sign ($): Matches the end of the string
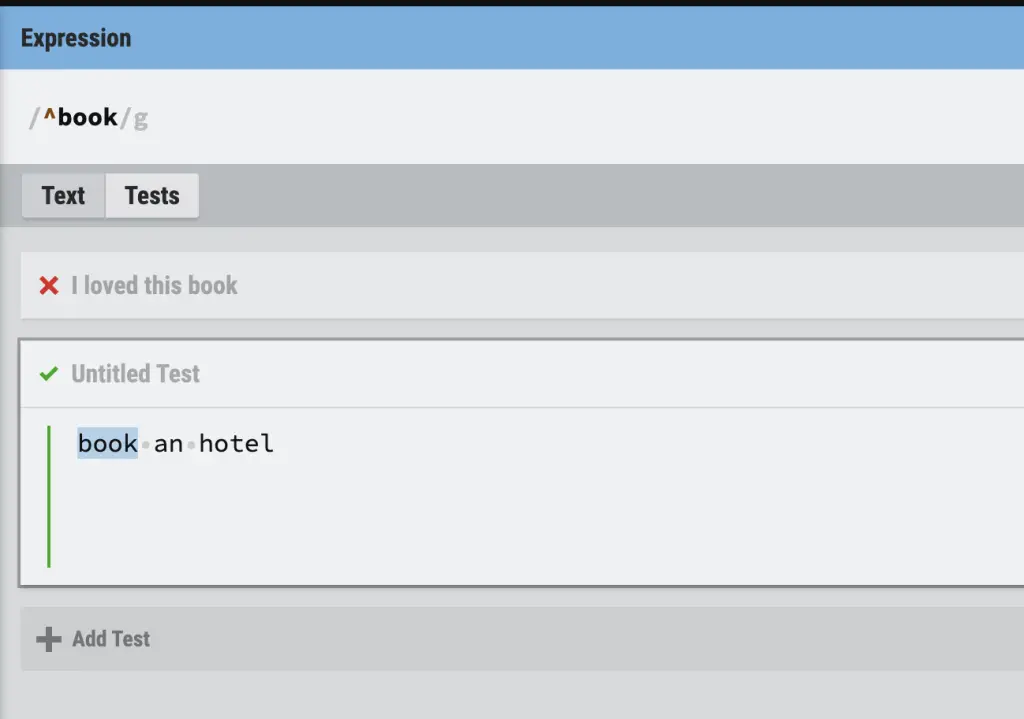
Caret in RegEx (^)
The caret (^) in regular expressions matches the start of a string.
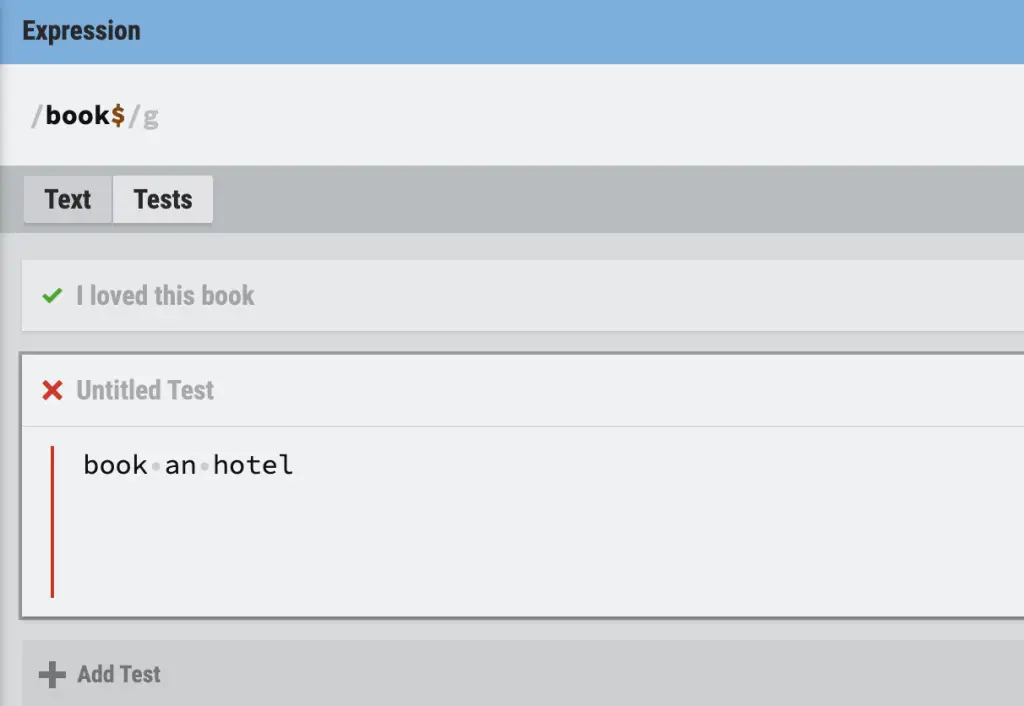
Dollar Sign in RegEx (?)
The dollar sign ($) in regular expressions matches the end of a string.
Boundaries in Regular Expressions
Boundaries in regular expressions match position where the left of the position is the defined character and the right is not the defined character.
Example boundary:
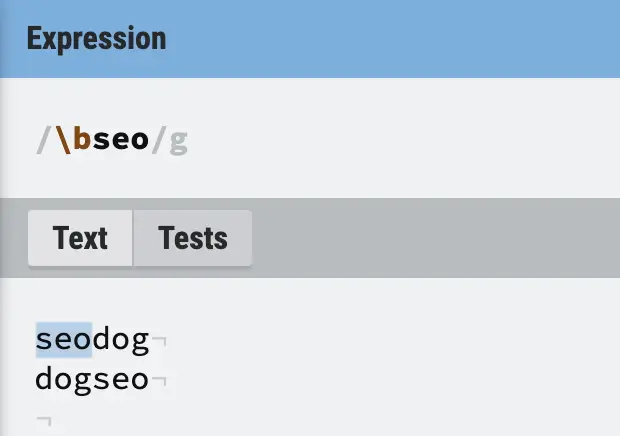
- \b: The left of the position is a word character, the right is not. E.g.
\bseowould match seo in “seodog” but not in “dogseo”.seo\bwould match the opposite.
Escaping Meta Characters with the Backslash
In regular expressions, we can use the backslash (\) character to escape characters. Escaping a character in RegEx means that we convert the meta character to its literal form, or convert the literal character to become a meta character
For example, by using \? in a regular expression, we tell the algorithm to consider the question mark character as itself rather than as an optional character.

In opposition, by using the \s pattern, we tell the algorithm to match any whitespace character instead of the literal letter s.

RegEx Special Characters Cheatsheet
| Character | What it Means | Example |
|---|---|---|
. | Any character | se. matches seo, sea, sem, ... |
| * | 0 or more of previous character | Goo*gle matches Gogle, Google, Gooogle, Goooogle |
+ | 1 or more of previous character | Goo+gle matches Google, Gooogle, Goooogle |
? | Optional character | Flavou?r matches Flavour, Flavor |
^ | Beginning of a line | ^hello matches hello world, but not My name is hello |
$ | End of a line | regex$ matches I love regex, but not regex is cool. |
\ | Escape a special character | example\.com matches example.com but not example2com |
What Are RegEx Grouping Constructs
In regular expressions, grouping constructs are used to group parts of a regex pattern. The constructs are can be used to apply quantifiers or modifiers to a specific part of the pattern, capture substrings for later use, or create subpatterns within a larger pattern. There are two main types of grouping constructs in regex:
- Capture Groups: Group and capture part of the pattern. Defined by parentheses
(and) - Non-Capture Groups: Group without capturing a part of the pattern. Defined by
(?:) - Lookahead and Lookbehind Assertions: Lookahead and Lookbehind check if text follows or precedes a pattern, without including it in the match.
What are Regular Expressions Capture Groups
Regular expressions capture groups are a feature used to extract and work with specific parts of a matched pattern within a text string. Capture groups are defined in RegEx using parentheses ( and ).
Whenever you create a capture group with the parentheses in a RegEx, you store that part of the pattern to a register that you can refer to later.
Capture groups are used to group, extract, access or replace pattern within the text string.
RegEx Capture Group Example
For example, the following regular expression uses a capture group to parse the URL and see if the domain belong to Google or Facebook, while storing the pattern within the capture groups.
www\.(google|facebook)\.comRegEx Capture Group Register
You can access items within the capture group register by selecting the element using the backslash and the position in the capture index: \1 matches the first capture group.
What are Regular Expressions Non-Capturing Groups
Non-capturing groups are used in RegEx to group parts of the pattern when you don’t need to capture the matched text. They are defined by parentheses and the ?: characters after the opening parenthesis (?: ).
For example, Google and Facebook would be ignored in the following expression when referring to the \1 capture group. The \1 capture group would refer to tech or social.
(:?google|facebook) are (tech|social) companiesWhat are Lookahead and Lookbehind Assertions
Lookahead and lookbehind assertions, also known as zero-width assertions, are features in regular expressions (regex) used to specify conditions for matching text without including the matched text in the result.
| Construct | Zero-width assertion | Regex pattern | Matches |
|---|---|---|---|
(?=) | Positive lookahead | a(?=b) | ‘a’ only if followed by ‘b’. |
(?!) | Negative lookahead | a(?!b) | ‘a’ only if not followed by ‘b’. |
(?<=) | Positive lookbehind | (?<=a)b | ‘b’ only if preceded by ‘a’ |
(?<!) | Negative lookbehind | (?<!a)b | ‘b’ only if not preceded by ‘a’. |
What are Regular Expression Quantifiers
A regular expression quantifier specifies how many occurrences of the previous element must be in the input for the pattern to be matched.
| Quantifier | Description |
|---|---|
| ? | Matches the last character 0 or 1 time |
| * | Matches the last character 0 or more times |
| + | Matches the last character 1 or more times |
| {n} | Matches exactly n times |
| {n,} | Matches at least n times |
| {n, m} | Matches at least n times, but not more than m times. |
| *? | Matches the preceding element 0 or more time in minimal number of times. |
| +? | Matches the preceding element 1 or more time in minimal number of times. |
| ?? | Matches the preceding element 0 or 1 time in minimal number of times. |
What are Regular Expression Options (Flags)
Regular Expression Options, also known as flags, modify how regular expressions are interpreted. They control behaviours like case sensitivity and multiline matching for instance.
| Option | Description | Pattern | Matches |
|---|---|---|---|
i | Enables case-insensitive matching. | \b(?i)apple(?-i)\w+\b | Matches "Apple", "aPPle", and "ApplE" in the text "Apple, aPPle, ApplE, orange". |
m | Enables multiline mode. In this mode, ^ and $ match the start and end of each line within the text. | ^(?m)Line \d+$ | Matches "Line 1", "Line 2", and "Line 3" in the following text:Line 1Line 2Line 3 |
n | Disables capturing of unnamed groups. | (?n)First (name) (age) | Matches "First (name) (age)" without capturing unnamed groups in the text. |
s | Enables single-line mode. Dot matches all characters, including newline characters. | (?s)Dot matches all. Dot is . | Matches the entire string "Dot matches all. Dot is ." without considering newline characters. |
x | Allows ignoring unescaped white space in the regular expression pattern. | (?x) This \s is \s ignored \s | Matches the word "This is ignored" in the text. |
How to Pronounce RegEx
RegEx is pronounced as “Regex”, not “Rejex”. The correct pronunciation of RegEx has “g” pronounced as the “g” in “group” or “regular”, not like the “g” in “gymnasium”.
Programming Languages with Regular Expressions
Regular expressions (regex) vary across programming languages like Python, JavaScript, Ruby, and Java in syntax and feature sets.
For instance, in Python use the re module is for regular expressions, while JavaScript offers built-in regex support. Ruby has regex literals like /pattern/, and Java requires escape characters for backslashes.
Thus, each programming language has its set of unique variations for using regular expressions.
How to Professions Use Regular Expressions
Regular expressions (regex) play a crucial role in information retrieval, machine learning, SEO, and data science by enabling pattern recognition, data extraction, and data. preprocessing.
Regular Expressions in SEO
Regex for SEO is generally used to analyze website or keyword databases in ways that can help to draw insights used to improve their presence on Google.
SEO professionals often use regular expressions to analyze Google Search Console data.
Regular Expressions in Machine Learning and Data Science
Regular expressions (regex) are crucial in machine learning and data science, especially in natural language processing (NLP). Regular expressions are used in feature engineering, text preprocessing, and Named Entity Recognition (NER).
They help split text into words (tokenization), extract entities, and clean and preprocess data by removing unwanted characters and tags.
Regular Expressions in Information Retrieval
Regular expressions (regex) are very useful in Information retrieval, mainly in text search, enabling search engines to match user queries with vast text databases.
They facilitate data extraction in web scraping, helping gather structured information like prices, dates, and contact details from websites.
Regex also supports document classification by categorizing content, such as organizing emails into folders based on sender names or subjects.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.