
In this guide, I will show you how to use Regex for SEO, even if you have no programming knowledge.
RegEx, or regular expressions, are easy to learn and amazingly useful, so make sure that you go through this entire tutorial because it is going to be one of the best time vs results investment in your SEO career.
This post is to help you learn regular expressions. Not all of the RegExes will work in Google Search Console as it uses a particular syntax. Read this post if you are looking for RegEx for Google Search Console.
Navigation
Show
What Are Regular Expressions (Regex)?
Regex, or regular expressions, are used to detect patterns in sequences of characters in strings.
With RegEx, you can easily match many results that have the same pattern.
Basic Regular Expressions
. | Any character |
.* | 0 or more characters |
.+ | 1 or more characters |
? | Optional character |
^ | Beginning of a line |
$ | End of a line |
\ | Escape a special character |
For example, one of the most common patterns that I use with Google Analytics is this one:
.*site1.*|.*site2.*
or the equivalent:
.*site(1|2).*
This way I can match any of those results:
#Match
site1.com
site1.fr
site2.ca
www.site2.com
site2.ca/url-path
#No Match
www.google.com
RegEx is not specific to any programming language. So, whether you are using Google Analytics, or programming in Python, JavaScript or Java, you’ll need at some point to use Regular Expressions.
Regular expressions have different flavours from one programming language to the other.
However, if you learn how to use general regular expressions, you’ll have no problem using them in any of the programming languages.
Regular expressions, or regex, can be a powerful tool for SEO practitioners looking to optimize their website. In addition to excluding unwanted data in Google Analytics filters, regex can also be used to identify and extract valuable insights from website data. By learning the basics of regex and how to apply it to your SEO efforts, you can unlock valuable insights and streamline your optimization process.
What is Regex For SEO?
Regular expressions, or regex, can be a powerful tool for SEO practitioners looking to optimize their website. Regex can be used to exclude unwanted data in Google Analytics filters and identify and extract valuable insights from website data. Regex for SEO is about leveraging the string matching capabilities of regular expressions in data mining or text processing operations.
You can use regex to analyze specific patterns in URLs, meta tags, and page content. It can help your keyword research and content optimization. On top of it, using regex, you can make bulk changes to your website’s code or content.
Get Started With RegEx
This guide will walk you through the basics of RegEx. If you want to go further, make sure that you look at my favourite tool, Regex101, and this RegEx Cheat Sheet.
Not All RegEx are Equal
Regular Expressions are used in computer programming and data analysis.
Depending on the programming language that you use, or the tool that you use, some RegEx will not work.
Why Learn RegEx for SEO?
The most common usages of Regex for SEO is use regular expressions to filter data in Google Search Console and Google Analytics.
Then, they’ll start using it for crawling and scraping purposes and as their career and knowledge progress, they’ll start using it to make API calls, until they use them everywhere.
To filter out all organic traffic coming from Google, including Google Search and Google For Jobs, but excluding Google CPC.
In this case, you would go to Acquisition > All Traffic > Source/Medium > Advanced and would use the .*google.*organic.* regular expression to filter out your results.

And then you’d get a report like this.
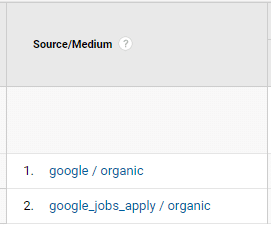
I know that this is fairly basic, but I just wanted to show why you’ll absolutely need regexes one day or the other in your SEO career.
The Regular Expressions in Google Analytics are quite limited compared to what you can actually do with Regex.
Why Use Regex?
Regular expressions are useful to define filters and to execute search and replace operations on textual information. Regex contain a series of characters that define patterns to be matched against text, thus making them practical in text processing operations
What is Regex Good For?
Regular expressions is a powerful series of string matching patterns useful in text processing operations. Regex can be used to search, match and manage patterns in text. A typical use case is to search and replace a sub-string in text or to filter rows of a data set based on a pattern.
Using Regex in SEO
RegExThe most common uses of Regex For SEO is to filter reports in Google Analytics and Google Search Console. Regular expressions can be used to explore and view only the relevant data. RegEx can also be used in various applications of computer programming and business analytics.
- large-scale data analysis (such as server logs)
- computer programming,
- search and replace operations
Using Regex in Google Analytics
A very common place to use Regex in SEO is in Google Analytics.
For Universal Analytics, Regular expressions can be used to filter reports, create custom dimensions and create custom groupings. Annielytics made a great video on the subject.
When it comes to GA4, Regex are not as useful to filter reports anymore as filters make it more convenient to filter reports without regex
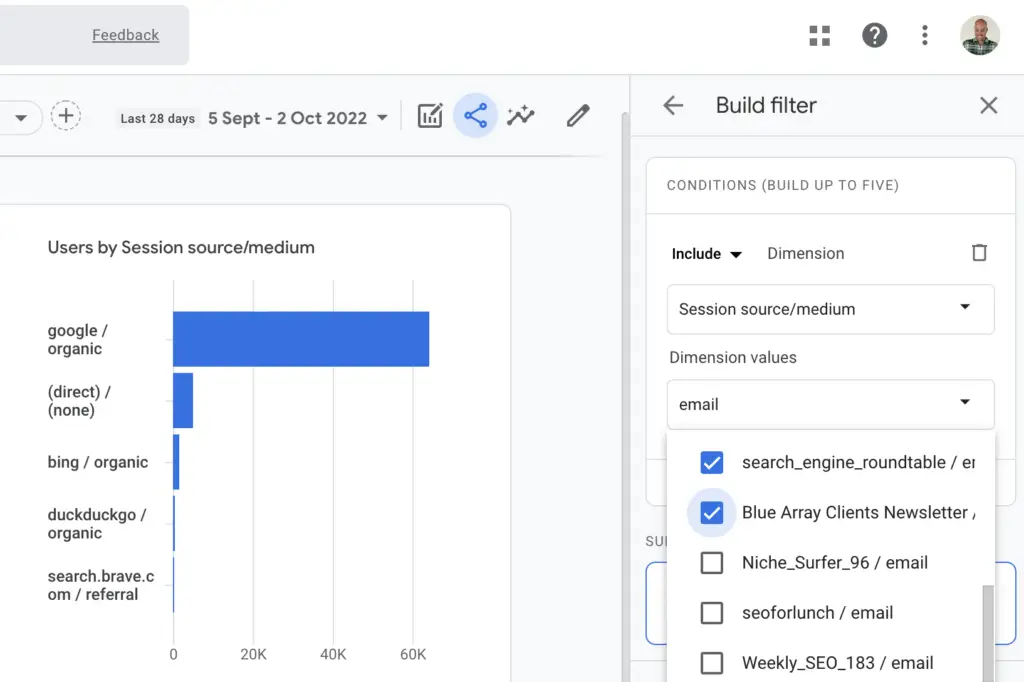
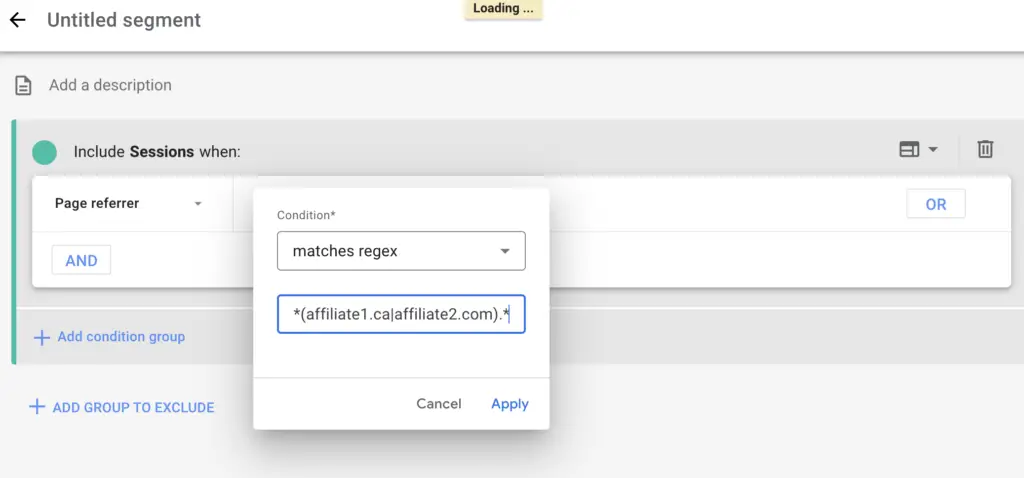
Still, regular expressions can be used in Google Analytics in other ways, such as to create custom segments.
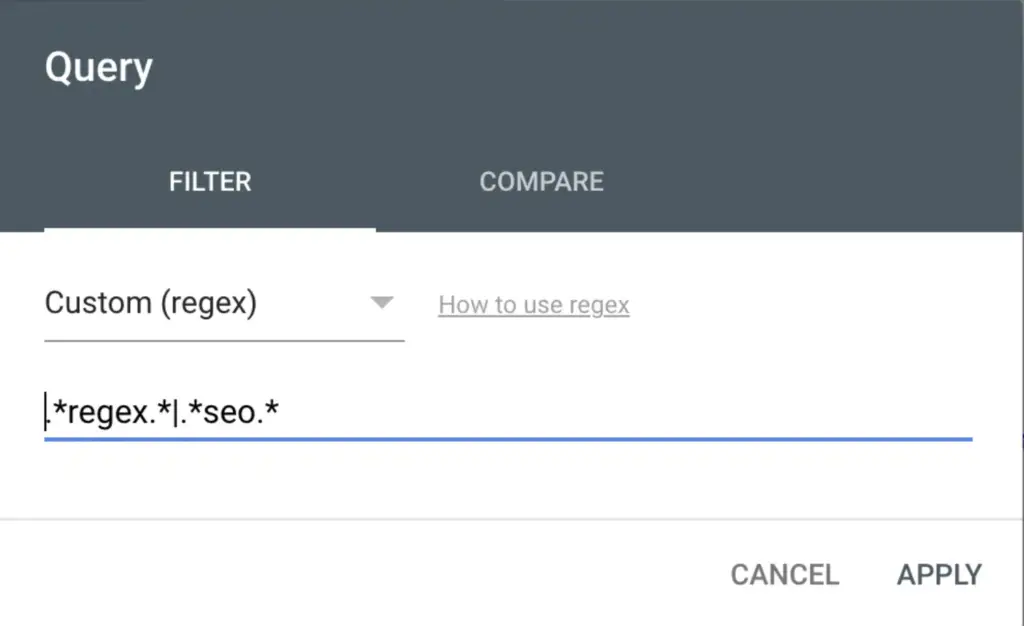
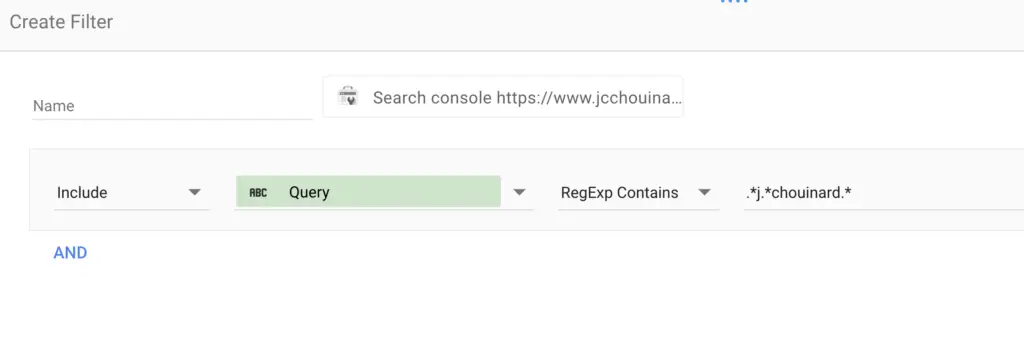
Using Regex in Google Search Console
One of the most interesting use of regex for SEO is to filter Google Search Console Performance report.
In Google Search Console, you can use regular expressions to filter query or pages that match or doesn’t match the Regex patterns that you define.
Google Search Console uses Re2 syntax for regex. Thus, it does not support all the regular expressions syntaxes. I have a complete guide on GSC regular expressions.
This is pretty powerful to (among other things) dig into your queries to identify questions user may ask, find long tail queries or to find potentially duplicate URLs.
Using Regex in Screaming Frog
Screaming Frog is consistently building incredible features that SEOs can use to power-up their crawling abilities. One of these features is the capacity to use regular expressions to filter crawls and enhance custom extractions.
One example is to extract GA or GTM tags from a page to see where it has or hasn’t been added properly.

Another Regex example given by Screaming Frog is to use regular expressions to extract structured data.
"product": "(.*?)"
"ratingValue": "(.*?)"
"reviewCount": "(.*?)"
All-in-all, you can scrape anything that you want from the HTML using regular expressions with Screaming Frog.
Using Regex in SQL
SQL is useful for Enterprise SEOs to do things such as to query server logs. Regular expressions can also be used in SQL to query databases.
For instance, regular expressions can be used to filter mySQL using REGEXP or REGEXP_LIKE.
SELECT *
FROM access_logs
WHERE regexp_like(user_agent , '.*googlebot.*') ;
Using Regex in Python
Python SEO fans that use Pandas for SEO analysis can use regular expressions to filter, match, replace or extract data from Dataframes.
Example of Regular expressions SEOs can use in Python Pandas.
# filter dataframe
df[df['url'].str.contains('.*regex.*')]
# extract parameters from URLs
df['url'].str.extract(r'\?(.*)')
Regex in Datastudio (a.k.a. Looker)
Regular expressions can be used by SEOs to filter Datastudio reports.
For instance, if you are analyze Google Search Console in Datastudio, then you can use regular expressions to filter your reports
From Google documentation, here are the formulas you can use in calculated fields.
| regexp_contains | Filter elements that contain a pattern |
| regexp_extract | Extract pattern from element |
| regexp_match | Check if pattern is matched |
| regexp_replace | Replace regex pattern |
How to use Regular Expressions
Regular expressions can be used to match string patterns in text. Example of patterns that can be used in Regex are:
- Match Characters
- Filter by OR / AND Logic
- Repeat Pattern as Many time as Needed with Quantifiers
- Exclude Patterns with Negated Character Sets
- Search Strings Around a Pattern with Lookaheads
- Find Largest or Smallest Matching Pattern (Greedy and Lazy Matching)
- Group Elements of a RegEx
Match Characters
To match one or multiple characters you could use flags like we just saw. You can also use wildcards or other specific set of indications.
.matches anything.SE.will matchSEOandSEM;[aeiou]matches one of those vowels. b[aiu]g will matchbag,bigandbug.[aeiou]\gwould match mutiple vowels;[a-z]matches a rage of characters. This would match any lowercase character from the alphabet. To match any lower and uppercase characters you could use[a-z]\ior[a-zA-Z];[0-9]matches a range of numbers from 0 to 9. You can combine the regEx to match numbers and letters like this:[2-5b-h];^only match if it starts with the string.^SEO.*matchesSEO is greatbut notI love SEO.$only match if it ends with the string..*regex$matchesI love working with regex, but does not matchregex are awesome.Colou?rsays the previous character “u” is optional. It matchesColorandColour.
Filter by OR / AND Logic
You’ll want to include one or more result or merge multiple conditions in your regular expressions using logical OR.
Using the | symbol, you’ll be able to match multiple conditions.
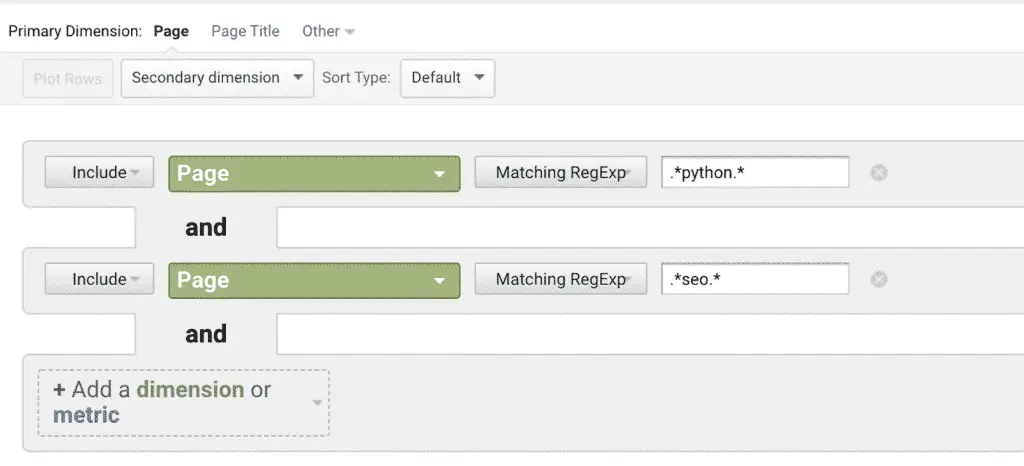
When you need ALL conditions to be true, you can combine them using an alternative to a AND operator using the pattern .*(?=.*pattern)(?=.*pattern).*
For example:
-
python | seo– Matches: python OR seo. Matches: Python jobs, SEO jobs, Python for SEO. .*(?=.*python)(?=.*seo).*– Matches: python AND seo. Matches: Python for SEO, SEO with Python but do not match SEO jobs.
The AND syntax is not supported in Google Analytics.
You would need to do it this way.
Repeat Pattern as Many time as Needed with Quantifiers
Quantifiers, or quantity specifiers, are useful to tell the number of times that you want to repeat a character. This represents the number of times the previous thing can match.
| One or more times | + |
| Twice | {2} |
| Three to five times | {3,5} |
| Zero or more times | * |
| Once or none | ? |
Exclude Patterns with Negated Character Sets
When you want create a set of characters that you don’t want to match, you need to use negated character sets.
To create them, you can use carets character inside a character set ([^]).
[^]matches string that does not include.[^aieou]match a single character not present in the list[aeiou];
Search Strings Around a Pattern with Lookaheads
Lookaheads are patterns that tell to lookahead in your string to check for the patterns you specify. There are positive lookahead ((?=)) and negative lookahead ((?!)) .
se(?=o)
seo #match "se"
sem #no match
se(?!o)
seo #no match
sem #match "se"
Find Largest or Smallest Matching Pattern (Greedy and Lazy Matching)
In regular expressions, a greedy match finds the longest possible part of a string that satisfies the regex. A lazy match is the opposite. It finds the smallest possible part of the string that matches the regex.
.*is a greedy match since it matches anything.<.*>will match<h1>This is HTML</h1>?is a lazy match.<.*?>will match<h1>
Group Elements of a RegEx
You can group elements of a RegEx with parentheses () in an element called a capture group.
sam.*(hunt|jackson)would matchsam huntandsamuel l. jackson, but notsammy davis jr.
Other Useful Regex
(?<=[\/])\d{2,} Matches any numbered ID preceded by a backslash.
^\s+|\s+$ Select all white spaces at the begining and at the end of a string. This can be useful when doing data manipulation.
(?<=\.)(.*?)(?=\.) Lets you extract a domain name. This will match any string between two dots.
(?<=string)(.*) Matches anything after a string, excluding that string. Useful to clean-up URLs.
Flags (not for GA or GSC)
Flags will help you determine what kind of character to match. You might want to ignore case when matching or match only numbered words.
To do this, you’ll need to end your regex with a flag like this:
google\i
Matches google and Google.
The most useful flags are:
\iignore case;\gmatches more than once (JavaScript);\dmatches one digits from 0 to 9;\wmatches ASCII letter, digit or underscore. It is the same as[A-Za-z0-9_]\g;\smatches whitespace;\Dmatches anything that is not a digit from 0 to 9;\Wmatches anything that is not a ASCII letter, digit or underscore;-
\Smatches anything that is not a whitespace.
Testing Your Regular Expressions
Here are three websites, to test, save and share your regular expressions.
Regular Expressions Examples
| seo|regex | Contains {seo} or {regex} |
| se(o|m) | Contains {seo} or {sem} |
| se[om] | Contains {seo} or {sem} |
| .*seo.* | everything that contains {seo} |
| colou?r | contains {color} or {colour} |
| go+gle | contains {gogle}, {google} … {goooogle} |
| example.com/(aa|bb) | Matches example.com/aa and example.com/bb |
| ^[\w\W\s\S]{1,10}$ | Matches short patterns of less than 10 characters |
| ^[\w\W\s\S]{70,}$ | Matches long patterns of more than 70 characters |
| [^\/\.\-:0-9A-Za-z_] | Contains special characters |
| *\/$ | Ends with trailing slash |
| https?\:\/\/.*example\.com\/?$ | Show HTTP/HTTPS/Subdomains Variations |
| who|what|when|how|why | Show informational intent |
| .*(buy|cheap|price|purchase|order).* | Show transactional intent |
| ^seo | Begins with SEO |
| seo$ | Ends with SEO |
| ^seo$ | Is exactly SEO |
| a{3} | Contains {aaa} |
Building Blocks of a Regular Expression
Regular expressions are created using a combination of metacharacters and literal characters.
- A literal character is a regular character used to match itself. E.g. Using the letter “a” and the number “2” to respectively match the letter “a” and the number “2”.
- A meta character is a special character that has a meaning within the regular expression. E.g. Using the Dot (.) symbol to match any character or the caret (^) to match the beginning of a string.
Meta Characters
Meta characters are what gives the full power to a regular expression.
Here is a table describing most common Regex meta characters.
| Meta Character | Description |
|---|---|
| \ | Escapes a regular expression meta character or marks a literal character as special. |
| | | Matches one expression OR the another |
| ( ) | Creates a match group |
| ? | Matches the last character 0 or 1 time |
| ^ | Matches the beginning of a string |
| $ | Matches the end of a string |
| * | Matches the last character zero or more times |
| + | Matches the last character one or more times |
| . | Matches any single characters |
| [ ] | Matches characters inside brackets |
| [^ ] | Matches anything except characters inside brackets |
| {n} | Matches n repetitions |
| \d | Matches a digit character |
| \s | Matches any whitespace character |
| \w | Matches any word character |
| \W | Matches any non-word character |
Escaping Meta Characters
A meta character can be escaped using the backslash (\) characters.
So, if in a string you would like the question mark (?) to be considered literal, then you could escape it using the backslash in this way.
\?
Regex Operators
Regular expression operators can be grouped in various categories such as:
- Anchors
- Boundaries
- Wildcards
- Character Sets and Character Ranges
- Character groupings
Anchors
Anchors, in regular expressions, belong to the family of regex tokens that don’t match characters, but that checks if the position in the string matches a location (e.g. the end of a string).
It differs from boundaries in the sense that boundaries asserts what can be match to the left and right of the position.
Here are the anchors:
- Caret (^): Matches the start of a string
- Dollar sign ($): Matches the end of the string
Boundaries
Regex boundaries match position where the left of the position is the defined character and the right is not the defined character.
Example boundary:
- \b: The left of the position is a word character, the right is not. E.g.
\bseowould match seo in “seodog” but not in “dogseo”.seo\bwould match the opposite.
Wildcards
Regex wildcards match one or multiple character without explicitly saying what the character is. Examples:
- Dot (.) – Matches any single character
- Asterisk (*) – Matches the last character zero or more times
- Plus (+) – Matches the last character one or more times
- Question mark (^) – Matches the last character 0 or 1 time
Character Sets and Character Ranges
In regular expressions, you can express character sets and character ranges using the square brackets [].
With character sets, we can list characters to be considered in the expression. E.g. d[oi]g would match dog and dig.
We can create character ranges using the dash (-) symbol. This will match ranges of characters. Here are some examples:
- [a-z] matches letters from a to z
- [A-Z] matches letters from A to Z
- [0-9] matches numbers from 0 to 9
Character ranges can also be combined.
- [a-zA-Z0-9] can match lower and capital letters as well as numbers.
Character Grouping
Characters can be grouped using parentheses ().
For instance, the following regular expression would batch both “I love regex” and “I love seo”.
I love (regex|seo)
Regex SEO FAQs
What Regex means?
Regular Expressions, also know as regex, is a powerful way that uses string patterns search and manipulate text strings.
Why are regular expressions named “regular” expressions?
The origin of the name regular expression comes from the work of Stephen Kleene who developed regular expressions in a way to describe “the algebra of regular sets”.
What does ‘^’ and ‘$’ mean in regex?
Caret matches the start of a string and the dollar sign matches the end of a string.
What type of regex does Google Analytics and Google Search Console use?
Both Google Analytics and Google Search Console use the Re2 syntax.
What are Regex patterns?
Regex patterns are composed of one or more character and used by a regular expression engine to match against input text.
Go the Extra Length
Check out Paul Shapiro presentation on Regular Expression.
To learn more technical SEO, I deeply suggest that you start learning Python.
Conclusion
You now know everything about Regex SEO. This introduction to regular expressions for SEO gave you the power to improve your data analytics skills.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.