
This article is part of the Complete Guide on Google Search Console (GSC)
Google Search Console just started to support regular expressions (RegEx) in filters. Let’s learn how to leverage RegEx to analyse GSC data.
This article is to learn regular expressions that you can use in Google Search Console and follows the Re2 syntax.
To learn more regular expressions, read RegEx for SEO.
Getting Started with RegEx in Google Search Console
Google Search Console uses Re2 syntax and does not support all the regular expressions syntaxes that you might know.
Filtering by RegEx is available for Page and Query reports.
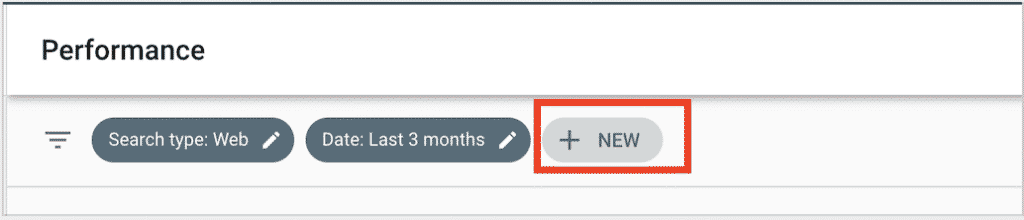
To filter the Performance Report using regexes click on New and select either Query or Page.
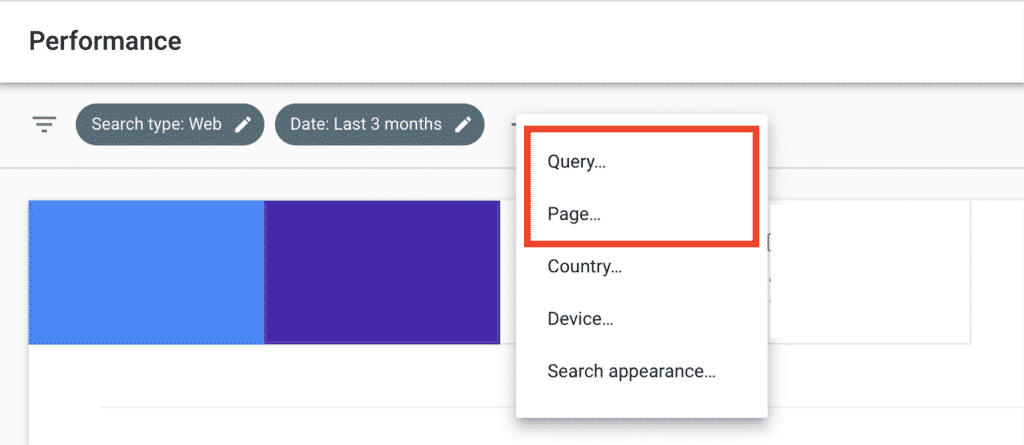
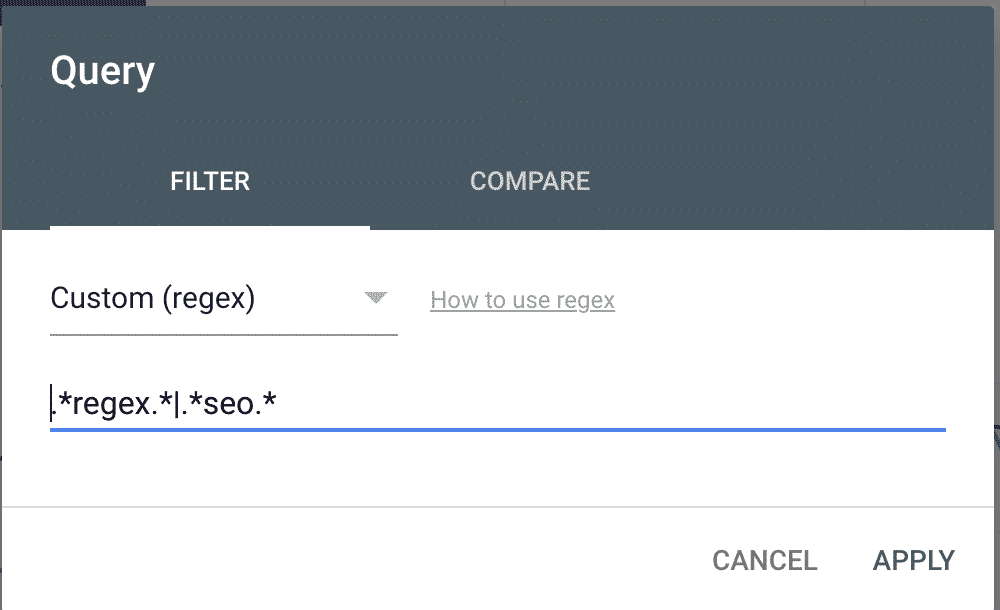
Add your regular expression and filter your report.
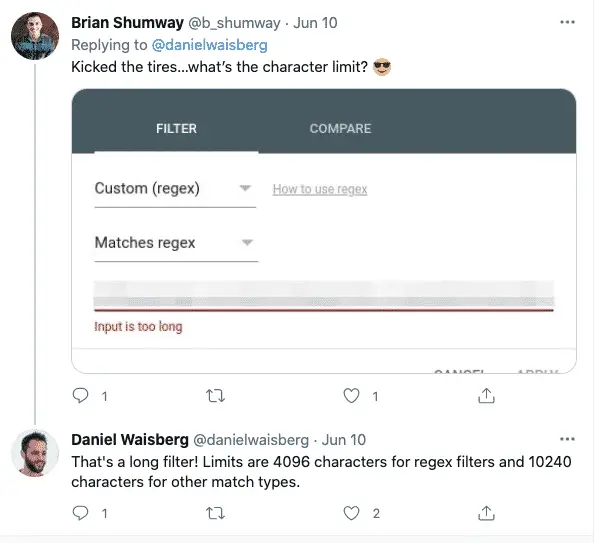
Character Limits
Google Search Console imposes a character limit of 4096 characters. It is usually enough.
With Regular Expressions, you can make your pattern more condensed to save characters.
For example, this:
example.com/aa|example.com/bb
equals:
example.com/(aa|bb)
Match all Pages / Queries that Contains a word
To filter pages or queries that contains a word, just wrap the word around .*.
This would match anything before and after your string. Here I match anything containing the word seo.
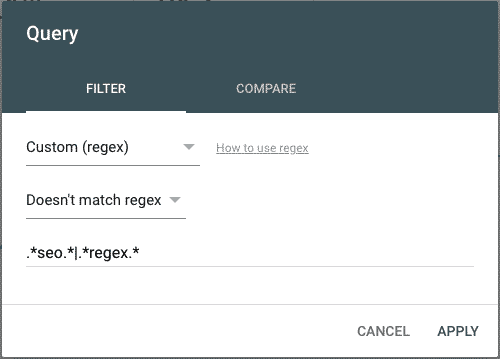
.*seo.*
.*matches anything.
Match Specific Pages
To match specific pages, write your property along with a capture group () for the URIs. You can help yourself with this with JR Oakes’ RegEx Builder in Google Sheets.
^https://www.jcchouinard.com/(python-for-seo|google-search-console-api|reddit-api)/$
()capture group to group elements together|meansOR^starts with$ends with
Negative Filtering with RegEx
The first reactions from the SEO community to the new regular expression filtering in Google Search Console was that negative lookahead was not supported in Re2.
Google quickly reacted and came up with negative filtering by regex.
You can now use the Doesn’t match regex with Custom (regex) filter.
Match Query / URL Length with RegEx
Match short patterns of less than 10 characters.
^[\w\W\s\S]{1,10}$
Results shown
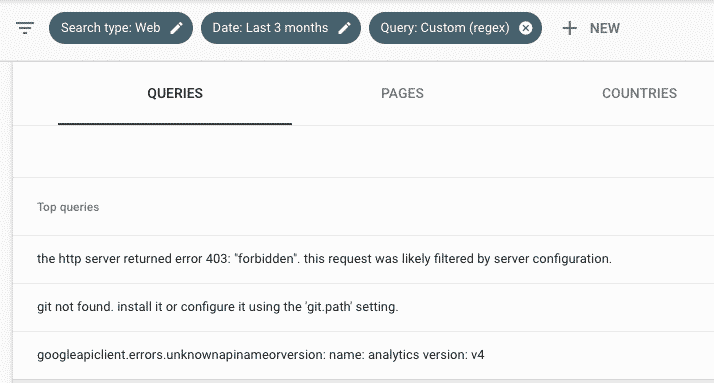
seo
python
regex
regex for SEO
Results filtered out
long-tail queries with more than 10 characters
[]matches range of characters^starts with$ends with\wmatches ASCII letter, digit or underscore. It is the same as[A-Za-z0-9_]\g;\smatches whitespace;\Wmatches anything that is not an ASCII letter, digit or underscores;\Smatches anything that is not whitespace.{1,10}repetitions of patterns from 1 to 10 times.
Find long-tail queries with Regular Expressions
The RegEx below would match any query longer than X characters (70 in this case).
^[\w\W\s\S]{70,}$
Another solution is to count the number of whitespaces to identify the number of words.
(\w+\s){7,}\w+
^startswith$endswith[\w\W\s\S]any character{70,}70 times or more(\w+\s)Any number of words between 1 and unlimited times followed by a space{7,}7 times or more\w+ending with a word
Find Very Long URLs
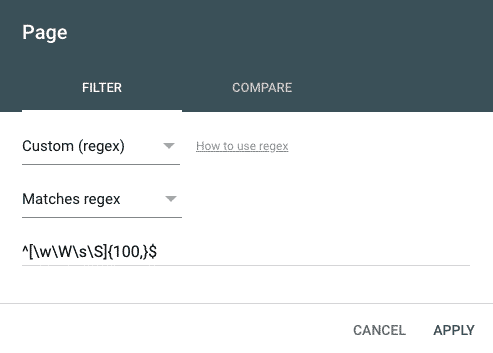
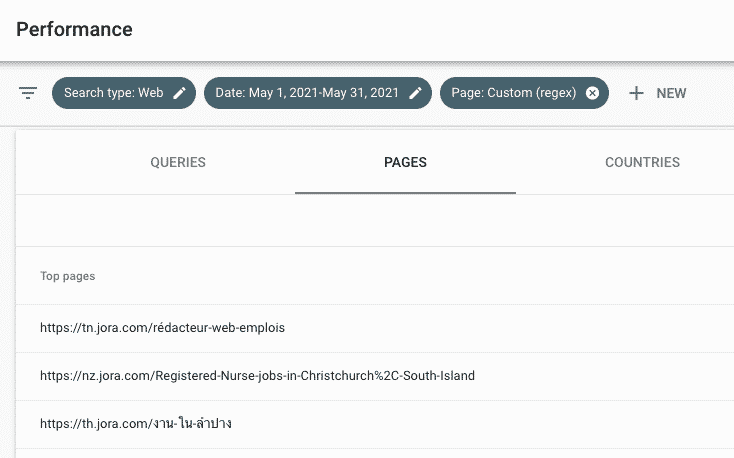
Use this regular expression to filter page urls that are longer than 100 characters.
^[\w\W\s\S]{100,}$
URL Containing Special Characters
Matches any URL that contains special characters.
[^\/\.\-:0-9A-Za-z_]
[^]exclude range of characters\/\.\-\:Exclude non-word characters that are common in URLs (i.e. the://in the protocol and the dashed-between words)0-9A-Za-z_word characters to exclude from the regex.
Show a Specific URL Path
Sometimes, you just want to match a specific path.
/<category>/<sub-category>/<feature>
.*/jobs/.*/melbourne$

That could match
/jobs/sales/melbourne/jobs/marketing/melbourne- …
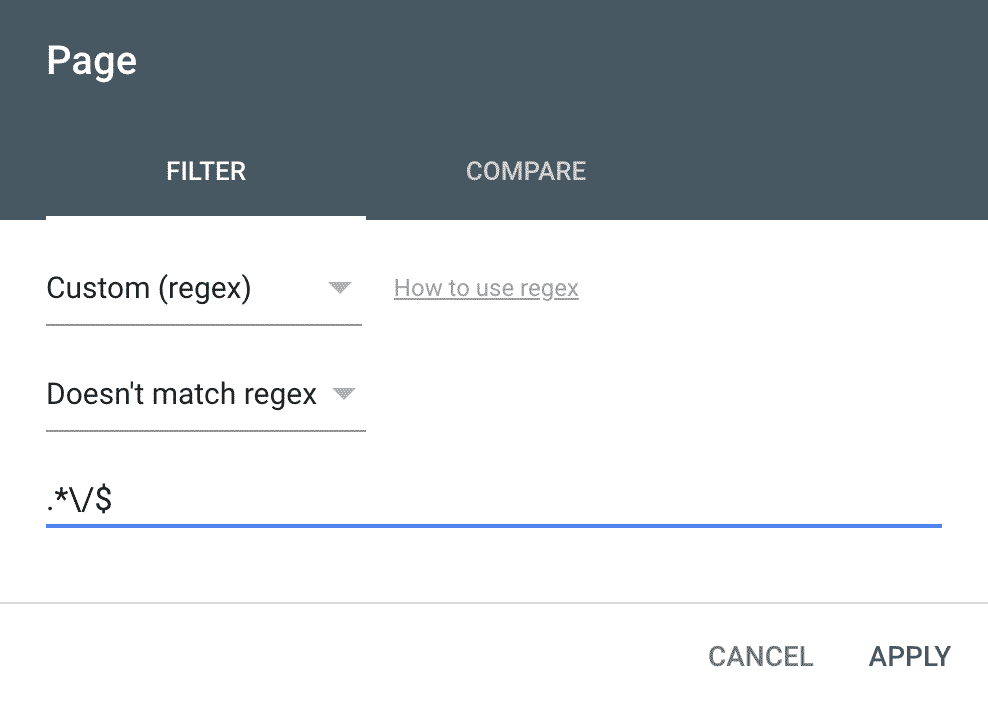
Ends With a Trailing Slash
Show pages that does contain (or not) the trailing slash at the end.
.*\/$
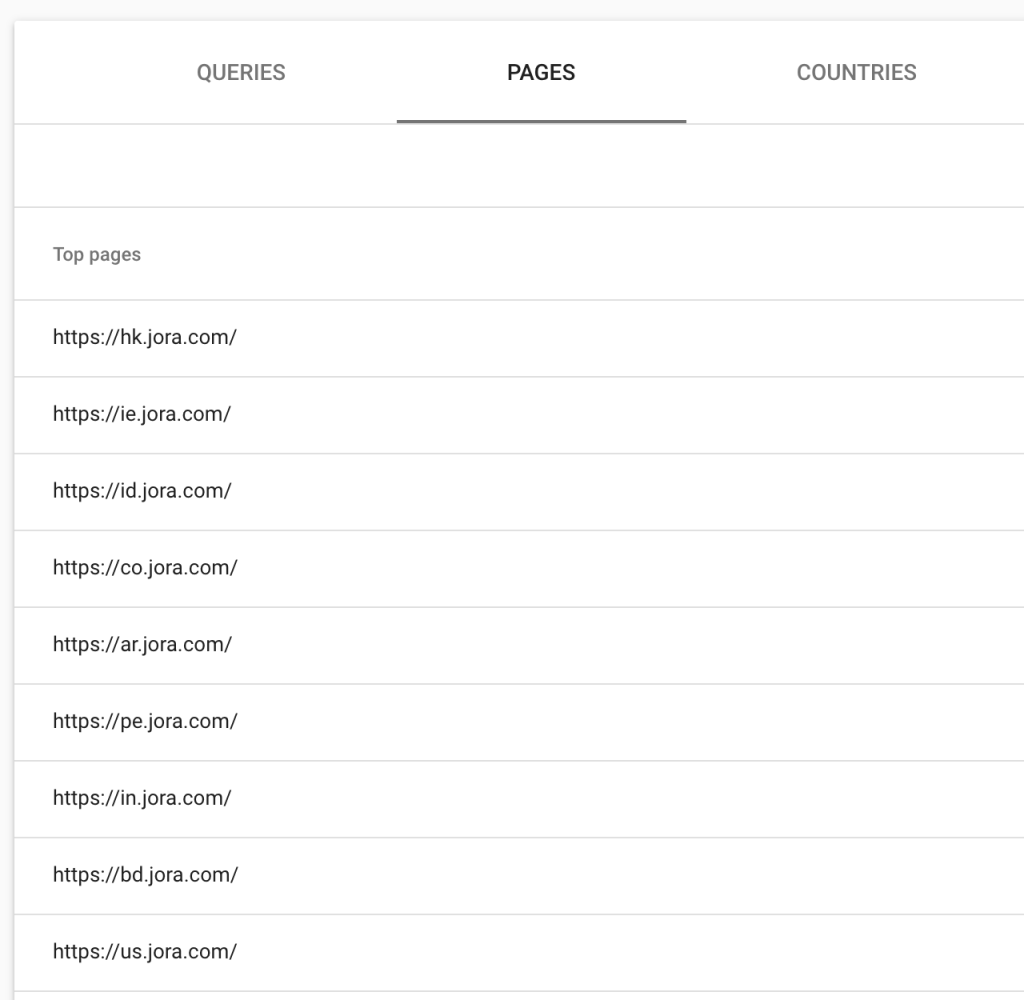
Show HTTP/HTTPS/Subdomains Variations
Although it is recommended to validate your site in Google Search Console both at a domain level and individual URL prefix, you might want a quick way to check your domain property for indexed subdomains or HTTP/HTTPs variations.
https?\:\/\/.*example\.com\/?$
This is a quick way to identify subdomains that you might not know are indexed.
https?matches http or https\/?$ends with trailing slash or not.
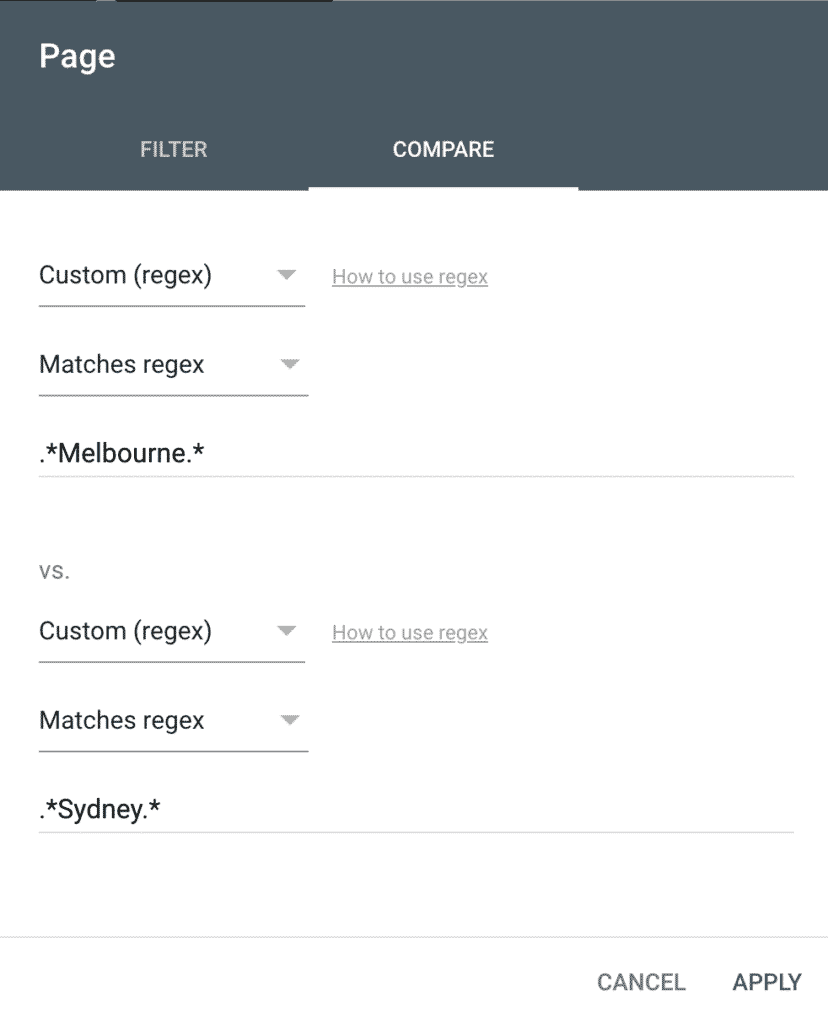
Compare Regular Expressions
You might want to compare pages or queries based on RegExes.
You can use the compare filter with regular expressions too.
Understand User Intent
Show queries that defines different user intent.
Informational
who|what|when|how|why
and more coming from Steve Toth:
who|what|where|when|why|how|was|did|do|is|are|aren’t|won’t|does|if|can|could|should|would|won’t|were|weren’t|shouldn’t|couldn’t|cannot|can’t|didn’t|did not|does|doesn’t|wouldn’t
See (Match Branded Terms).
.*brand.*
Commercial
.*(best|top|vs|review*).*
Transactional
.*(buy|cheap|price|purchase|order).*
Case Insensitive Queries
Want to make queries case insensitive? Add (?i) at the start of the expression. Thanks Charly Wargnier for the tip (buy the man a coffee).
(?i)^(who|what|where|when|why|how)[" "]
Match Branded Terms
Often people searches have spelling mistakes in them. You can properly evaluate brand searches with regular expressions.
Let’s make an example with Linkedin possible misspellings.
- lnkedin, linkeidn, linkden, linedin, linkein, likedin, linkin, linkedin, linkd, amazon linkedn
You could be string with a long regex:
.*lnked*in.*|linke*idn.*|linkd*en.*|lined*in.*|linke*in.*|liked*in.*|link*in.*|linked*in.*|.*linkedn.*|.*linkd.*
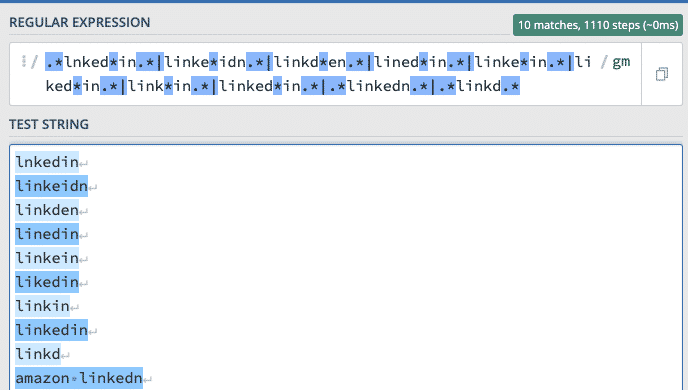
You could be very large at the risk of adding errors into it:
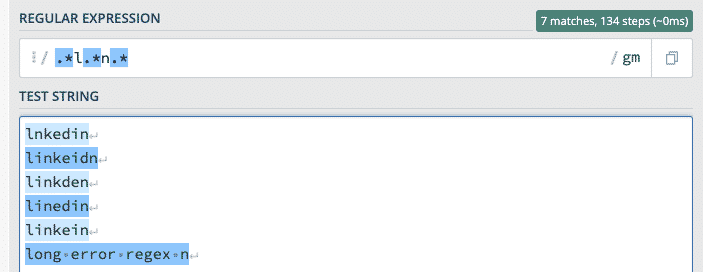
Or be more specific.
.*l(i|n){1,2}(k|e).*n.*
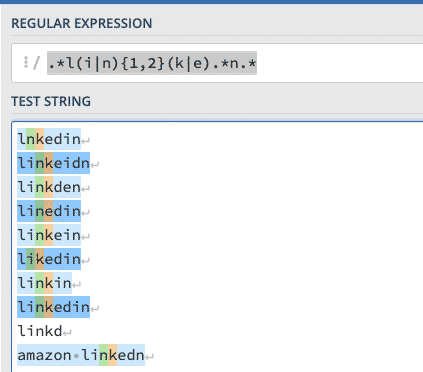
Multiple patterns can do.
.*l.*(i|n).*(n|k).*(e|d|i).*n.*
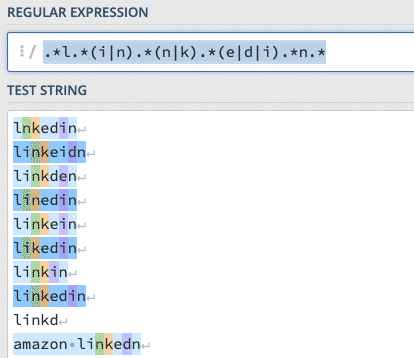
Compare Brand VS Non-Brand Traffic
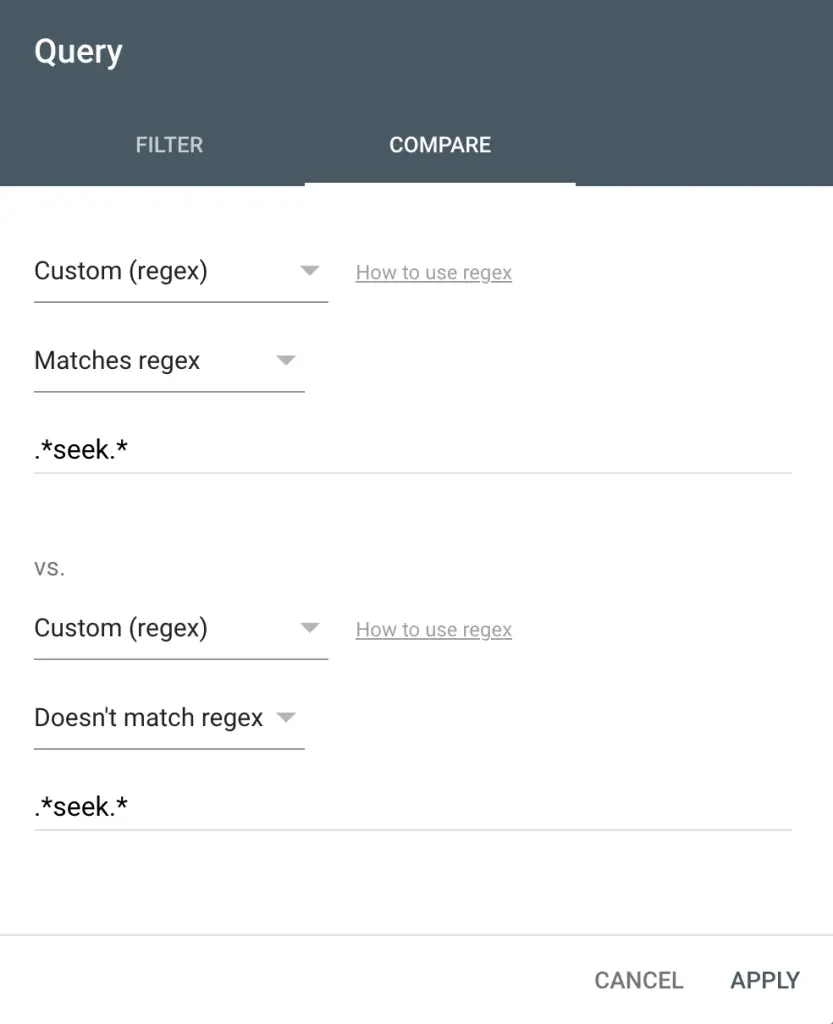
Check for Potential Content Injections
Content injection is a hack that injects webpages into your site including specific keywords. Here is an idea how you can check for common ones on your site.
Use this regex in the pages regular expression to check if it matches.
.*viagra.*|.*cialis.*|.*levitra.*|.*drugs.*|.*porn.*|.*www.*www.*
Could also check special characters or not-available-yet solution of looking for foreign characters in urls.
Check WordPress Admin URLs
Pretty straight forward, check WordPress admin pages that seemed indexed.
.*wp-.*
Edge Case Scenarios
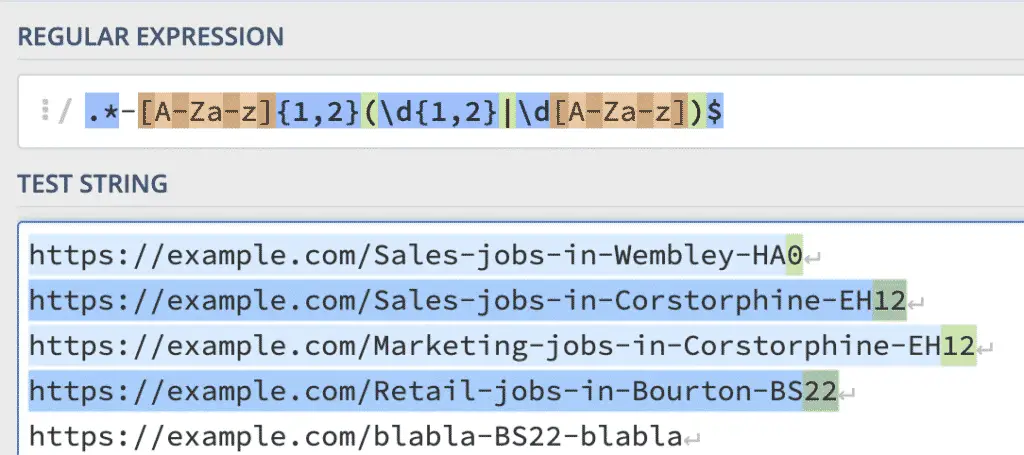
Show Postcodes in URLs
I came across a case where I needed to list URLs that ended with a postcode.
https://example.com/Sales-jobs-in-Wembley-HA0
https://example.com/Sales-jobs-in-Corstorphine-EH12
https://example.com/Marketing-jobs-in-Corstorphine-EH12
https://example.com/Retail-jobs-in-Bourton-BS22
In UK, postcodes consist of one or two letters, followed by one digit, two digits, or one digit and one letter.
.*-[A-Za-z]{1,2}(\d{1,2}|\d[A-Za-z])$
[A-Za-z]{1,2}: Matches one or 2 letters\d{1,2}: Matches one or 2 numbers\d[A-Za-z]: Matches a number and a letter( pat1 | pat2 ): Grouping of OR patterns
Should Work but Doesn’t
Foreign Characters in URLs
According to the Re2 documentation, unicode character classes like this should work:
\p{Greek}

This would be useful to identify URL patterns that have some of the foreign characters that are the most commonly used in content injection hacks.
.*\p{Hiragana}.*|.*\p{Cyrillic}.*|.*\p{Hangul}.*|.*\p{Han}.*|.*\p{Thai}.*
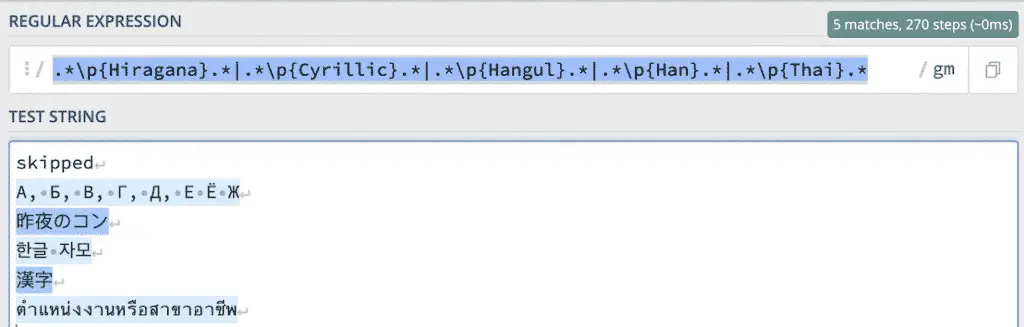
It works with Query RegExes, but it doesn’t work with URLs.
From the Community
There are a lot of other great ideas out there, share them with me and I’ll post them here.
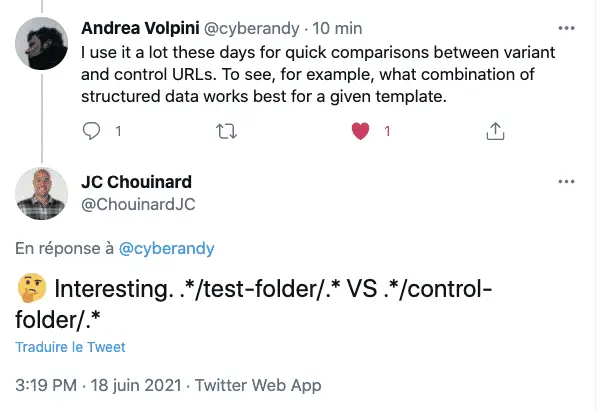
A/B Testing
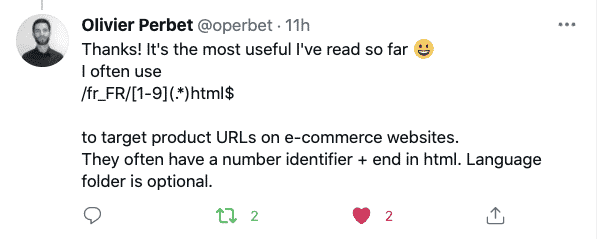
E-Commerce
Here’s one for e-Commerce stores.
Additional RegExes
Some additional regular expressions for GSC from this post (thanks Mike Ciffone)
# Matches URL slug
^[foo]+(?:-[bar]+)*$
# All urls within /page
(http|https):\/\/www.example.com\/page\/.*
# All urls between a certain slug and ending
(http|https):\/\/www.example.com\/slug\/[^\/]+\/page
# Matches all queries containing a specific term (all work)
\b(\w*foo\w*)\b
\b(\w*foo\sbar\w*)\b
^hello\sworld$
# Matches all queries containing "blue shoe" or "blue shoes"
(\W|^)blue\s{0,3}shoe(s){0,1}(\W|$) //works
# Matches all queries that contain "Ciffone" or "Ciffone Digital"
^.*(ciffone|ciffone digital).*$
# Match Word or Phrase in a List
(?i)(\W|^)(foo|bar|foo\sbar)(\W|$)
Other Articles in the Series on Google Search Console
- How to validate your site in GSC
- How to use the Performance Report in Google Search Console
- How to use the index coverage report
- How to use the URL Inspection Tool
- How to use the Crawl Stats Report
- How to use (and not use) URL Removal tool in GSC (Coming soon…)
- How to use URL Parameters Tools Without Killing Your Site (Coming soon…)
- Google Search Console Use Cases (Coming soon…)
- Regular Expressions (RegEx) in Google Search Console
Other Resources
Google’s examples of regular expressions for Google Search Console
#performanceregex on twitter
Conclusion
This is it, you now know how to use regular expressions with Google Search Console

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.