This post is part of the complete Guide on Python for SEO
I’ve been struggling for the past 6 months to find a solution to extract rendering problems on a large scale.
Fantastic enough, Tobias Willmann has published the solution to this very problem using Python Pandas and Screaming Frog SEO Spider.
I’ll try here to replicate his solution with a little more detail and further explanation, but it is mostly his work that is featured here.
What is Rendering?
According to Martin Splitt at Google, rendering is the process of turning (hyper)text into pixels.

JavaScript SEO Basics
JavaScript is handled differently by Google. It is delayed until Googlebot has the resources to render the JS content.
When we do JavaScript SEO, we want to make sure that critical content on a page, that needs to be executed via JavaScript, is being correctly rendered, indexed and ranked in search results by search engines.
How Does Google Handle JavaScript Rendering?
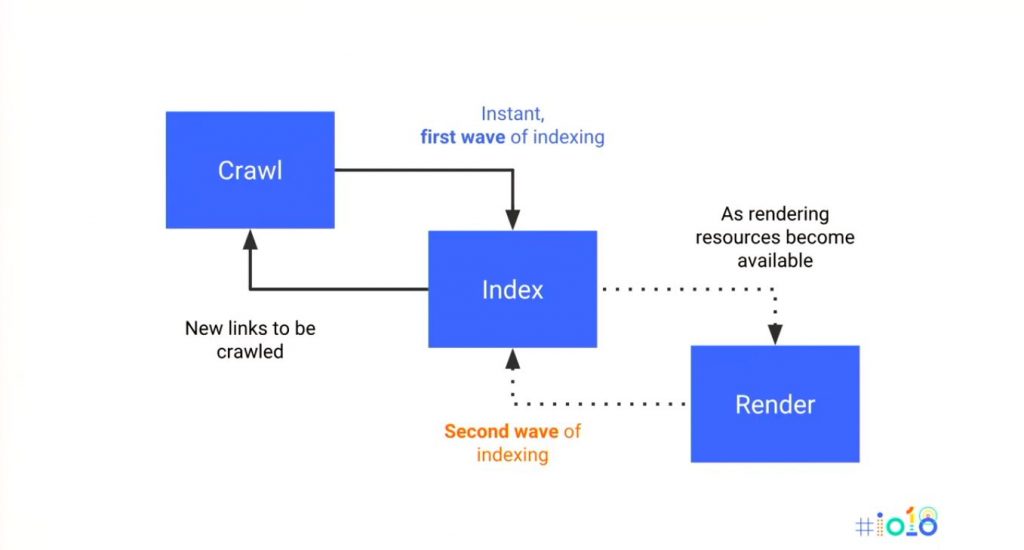
Google has recently revealed their current two waves process for JS rendering and indexing at Google I/O.
Google Has Two Waves of Indexing
Google basically says this: The rendering of JS is deferred until Googlebot has resources available to process that content.
This means that the first process the HTML, and IF they have more resources, they’ll come back to load your JavaScript content.
Why Test Rendering?
Deferred.
Yes, all your cute little content hidden behind JavaScript will be deferred, until Google finds it suitable to come back and spend money on your site to load your JS resources.
This is simple.
If you have important content, or important links. Make sure that Googlebot can find it straight in your HTML code.
But what happens when you have thousands of pages and you don’t know which resources are loaded via JavaScript, and which are not?
This is what this guide is for.
But first.
Let’s dive into Python Basics.
Python Basics
To understand this guide you will need to have Python installed, and you will need to have at least a basic knowledge of Python.
If you have no idea how Python works, just look at my two guides on the subject: how to install Python with Anaconda and my Python Basics Complete Guide.
This guide will be fully explained using Spyder that is natively installed when you install Python using Anaconda.
How to Test JavaScript Rendering on a Large Scale? (Step-By-Step)
Now it is time to put our website’s JavaScript (JS) to the test.
What we want to do is to:
- Make two crawls with Screaming Frog, one with “Text Only” rendering and the other with “JavaScript” rendering.
- Export the Data in CSV
- Load the Crawl Data Using Python
- Combine the Crawls Into One Data Frame
- Check Differences Between Crawls
- Make a Report With Excel
Step #1: Make Two Crawls With Screaming Frog
Let’s make a crawl of our website.
in fact, to compare which pages load properly let’s make two crawls:
- Text Only rendered
- JavaScript rendered
Text Only Rendered Crawl
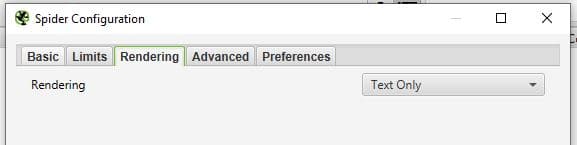
First, let’s crawl our website like Googlebot would do in its first wave before it renders the JS.
Go in Screaming frog > Configuration > Rendering > Text Only
JavaScript Rendered Crawl
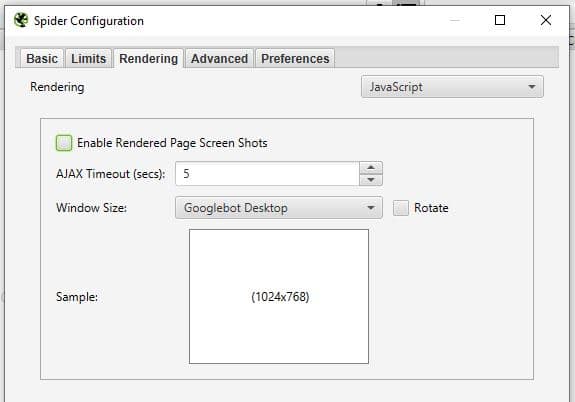
Now, let’s crawl our website including rendered results. This will mimic which link that Google will find in its second wave, where it renders the JS content after it has available resources.
Go in Screaming frog > Configuration > Rendering > JavaScript
Careful!
Make sure that you unselect “Enable Rederred Page Screen Shots” if you have a really large site. This will speed this process up. You can always recrawl the problematic URLs later on in list mode if you want to see the rendered pages Screen Shots.
Step #2: Export The Data To CSV
Now that your crawl is complete, you will want to export the Data to CSV.
Go in Screaming Frog > Export
Step #3: Load the Crawl Data Using Python
Since JS rendering mostly affect SEOs in its capacity to render links and content, we’ll try to see if a bot can load the content by checking the word count and the Link information in the Crawl.
- Address
- Status Code
- Word Count
- Outlinks
- Unique Outlinks
- Inlinks
- Unique Inlinks
- Canonical Link Element 1
dfTextonly = pd.DataFrame(pd.read_csv('Text-only-crawl.csv', low_memory=False, header=1))
dfTextonly = dfTextonly[['Address','Status Code', 'Word Count' ,'Outlinks', 'Unique Outlinks', 'Inlinks', 'Unique Inlinks',"Canonical Link Element 1"]].copy()
dfJS = pd.DataFrame(pd.read_csv('JS-Rendered-crawl.csv', low_memory=False, header=1))Source: Tobias Willmann
dfJS = dfJS[['Address','Status Code', 'Word Count', 'Outlinks', 'Unique Outlinks', 'Inlinks', 'Unique Inlinks',"Canonical Link Element 1"]].copy()
Step #4: Combine the Crawls Into One Data Frame
This is an easy step, just copy the code below.
Source: Tobias Willmann
df = pd.merge(dfTextonly, dfJS, left_on='Address', right_on='Address', how='outer')
What you’ll get is a new dataframe with the same column names twice.
Pandas has automatically added the “_x” and “_y” to the data of the first and the second crawls.
- _x is your data from “Text Only”
- _y is you crawl data from “JavaScript”

Note: In Spyder IDE,
Step #5: Check Differences Between Crawls
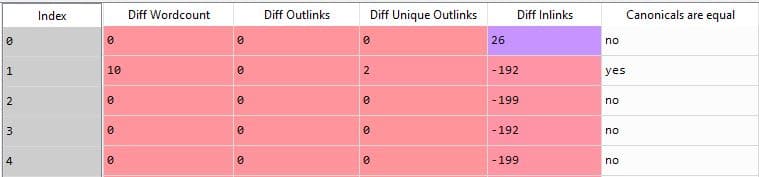
Here, what we will do is to count the differences in the number of words and the number of links from our “Text Only” crawl and our “JavaScript Rendered” crawl.
We want to flag pages with big differences between each other.
Why?
Because, it will mean that a lot of content is hidden behind JavaScript and can’t be accessed from Google’s first wave crawling.
##Check the differences in each crawl
df['Diff Wordcount'] = df['Word Count_y'] - df['Word Count_x']
df['Diff Outlinks'] = df['Outlinks_y'] - df['Outlinks_x']
df['Diff Unique Outlinks'] = df['Unique Outlinks_y'] - df['Unique Outlinks_x']
df['Diff Inlinks'] = df['Unique Inlinks_y'] - df['Unique Inlinks_x']
##Check if canonical links are equivalent
## Need NumPy library
import numpy as npSource: Tobias Willmann
df["Canonicals are equal"] = np.where((df["Canonical Link Element 1_y"] == df["Canonical Link Element 1_x"]), "yes", "no")
Here, you should get a result that looks like this.
Step #6: Make a Report With Excel
To export your data into Excel, just use the to_excel panda function.
Export in Excel
df.to_excel("rendering-test.xlsx")
Full Python Code
##Print the path of your current working directory
import os
print(os.getcwd())
#What you get here is where you should save your CSV crawls
##Import Panda Library
import pandas as pd
import numpy as np
##Load the crawls to Pandas
dfTextonly = pd.DataFrame(pd.read_csv('Text-only-5000-crawl.csv', low_memory=False, header=1))
dfTextonly = dfTextonly[['Address','Status Code', 'Word Count' ,'Outlinks', 'Unique Outlinks', 'Inlinks', 'Unique Inlinks',"Canonical Link Element 1"]].copy()
dfJS = pd.DataFrame(pd.read_csv('JS-Rendered-5000-crawl.csv', low_memory=False, header=1))
dfJS = dfJS[['Address','Status Code', 'Word Count', 'Outlinks', 'Unique Outlinks', 'Inlinks', 'Unique Inlinks',"Canonical Link Element 1"]].copy()
Combine the two crawls into one dataframe
df = pd.merge(dfTextonly, dfJS, left_on='Address', right_on='Address', how='outer')
##Check the differences
df['Diff Wordcount'] = df['Word Count_y'] - df['Word Count_x']
df['Diff Outlinks'] = df['Outlinks_y'] - df['Outlinks_x']
df['Diff Unique Outlinks'] = df['Unique Outlinks_y'] - df['Unique Outlinks_x']
df['Diff Inlinks'] = df['Unique Inlinks_y'] - df['Unique Inlinks_x']
df["Canonicals are equal"] = np.where((df["Canonical Link Element 1_y"] == df["Canonical Link Element 1_x"]), "yes", "no")
##Export in Excel
df.to_excel("rendering-test.xlsx")
Other Technical SEO Guides With Python
- Find Rendering Problems On Large Scale Using Python + Screaming Frog
- Recrawl URLs Extracted with Screaming Frog (using Python)
- Find Keyword Cannibalization Using Google Search Console and Python
- Get BERT Score for SEO
- Web Scraping With Python and Requests-HTML
- Randomize User-Agent With Python and BeautifulSoup
- Create a Simple XML Sitemap With Python
- Web Scraping with Scrapy and Python
This is it, you can now compare at a large scale which pages doesn’t load properly without JavaScript.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.