
What is awesome about the Reddit API is that you can extract data from Reddit without any credentials! In this beginner tutorial, I will show you how to scrape Reddit with Python, without using an API key or a wrapper.
This is the easiest way to query the Reddit API.
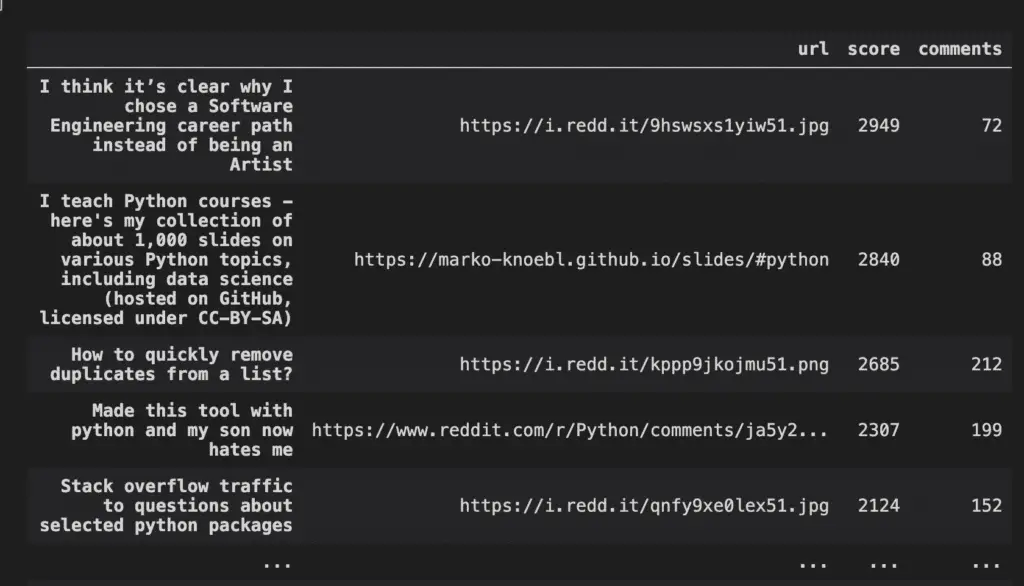
Let’s extract the top 100 posts from my favourite subreddit: r/python to make a DataFrame like this one.
If you know nothing about Python, make sure that you start by reading the complete guide on Python for SEO.
Understand the API Request
To query data from the Reddit API using Python, you just have to make an HTTP GET request to the subreddit URL and add the limit and t parameters.
https://www.reddit.com/r/{subreddit}/{listing}.json?limit={count}&t={timeframe}
The values that you can choose from are:
- timeframe = hour, day, week, month, year, all
- listing = controversial, best, hot, new, random, rising, top
For example, to get the top 100 posts in the past year for the r/python subreddit, you would query that URL:
https://www.reddit.com/r/python/top.json?limit=100&t=year
Note that as part of the Reddit blackout, r/python is now private and can’t be accessed with the API. Simply put any non-private subreddit like r/jokes still works.
You don’t even need Python. You could just go to the URL in your browser and copy the JSON file. That’s how simple this is.
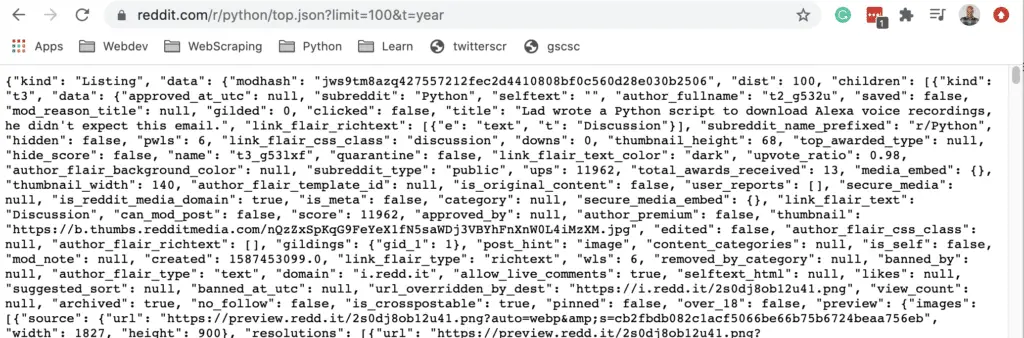
What this is is a JSON file that we need to parse in Python.
Make the Request
The requests package lets you make HTTP requests to a web server and receive the response.
I will create a function that will make the request and return a JSON file.
import requests
subreddit = 'python'
limit = 100
timeframe = 'month' #hour, day, week, month, year, all
listing = 'top' # controversial, best, hot, new, random, rising, top
def get_reddit(subreddit,listing,limit,timeframe):
try:
base_url = f'https://www.reddit.com/r/{subreddit}/{listing}.json?limit={limit}&t={timeframe}'
request = requests.get(base_url, headers = {'User-agent': 'yourbot'})
except:
print('An Error Occured')
return request.json()
r = get_reddit(subreddit,listing,limit,timeframe)
The result of the function is a JSON file that you will need to parse to find the title, the link, the score and the number of comments.
The score is computed with upvotes and downvotes.
Parse the JSON
Everything that you need here is under the r['data']['children'] JSON object.
To make this tutorial as simple as possible, we will make only two functions: get_post_titles() and get_results().
The former will only show the titles of the top posts on the Subreddit, the latter will return the DataFrame shown in the introduction.
Get Top Posts Using the Reddit API
To print the top posts using the Reddit API, you will need to loop through all the posts inside the r['data']['children'] element. For each post, you will need to get the title element, as simple as that.
def get_post_titles(r):
'''
Get a List of post titles
'''
posts = []
for post in r['data']['children']:
x = post['data']['title']
posts.append(x)
return posts
posts = get_post_titles(r)
print(posts)
Look at the end of this article for the full list of elements you can extract using the API.
Check Most important Posts on Reddit
Now, we will extract all the top 100 posts on the r/python subreddit, and check the title, the link, the score and the number of comments for each post.
The get_results() function creates a Python Dictionary with all of those values. Then, the dictionary is converted into a Pandas DataFrame.
def get_results(r):
'''
Create a DataFrame Showing Title, URL, Score and Number of Comments.
'''
myDict = {}
for post in r['data']['children']:
myDict[post['data']['title']] = {'url':post['data']['url'],'score':post['data']['score'],'comments':post['data']['num_comments']}
df = pd.DataFrame.from_dict(myDict, orient='index')
return df
df = get_results(r)
List of Data You Can Extract Using the Reddit API
In this post we have only extracted a few elements with the Reddit API.
To know all the elements that you can extract, look at this function.
r = get_reddit(subreddit,listing,1,timeframe)
for post in r['data']['children']:
for k in post['data'].keys():
print(k)
Here is the full list.
approved_at_utc
subreddit
selftext
author_fullname
saved
mod_reason_title
gilded
clicked
title
link_flair_richtext
subreddit_name_prefixed
hidden
pwls
link_flair_css_class
downs
thumbnail_height
top_awarded_type
hide_score
name
quarantine
link_flair_text_color
upvote_ratio
author_flair_background_color
subreddit_type
ups
total_awards_received
media_embed
thumbnail_width
author_flair_template_id
is_original_content
user_reports
secure_media
is_reddit_media_domain
is_meta
category
secure_media_embed
link_flair_text
can_mod_post
score
approved_by
author_premium
thumbnail
edited
author_flair_css_class
author_flair_richtext
gildings
post_hint
content_categories
is_self
mod_note
created
link_flair_type
wls
removed_by_category
banned_by
author_flair_type
domain
allow_live_comments
selftext_html
likes
suggested_sort
banned_at_utc
url_overridden_by_dest
view_count
archived
no_follow
is_crosspostable
pinned
over_18
preview
all_awardings
awarders
media_only
link_flair_template_id
can_gild
spoiler
locked
author_flair_text
treatment_tags
visited
removed_by
num_reports
distinguished
subreddit_id
mod_reason_by
removal_reason
link_flair_background_color
id
is_robot_indexable
report_reasons
author
discussion_type
num_comments
send_replies
whitelist_status
contest_mode
mod_reports
author_patreon_flair
author_flair_text_color
permalink
parent_whitelist_status
stickied
url
subreddit_subscribers
created_utc
num_crossposts
media
is_video
Full Code
Unfortunately, I have not made the repository public on Github yet. I will soon. Here is the full code.
import json
import pandas as pd
import requests
subreddit = 'python'
limit = 100
timeframe = 'month' #hour, day, week, month, year, all
listing = 'top' # controversial, best, hot, new, random, rising, top
def get_reddit(subreddit,listing,limit,timeframe):
try:
base_url = f'https://www.reddit.com/r/{subreddit}/{listing}.json?limit={limit}&t={timeframe}'
request = requests.get(base_url, headers = {'User-agent': 'yourbot'})
except:
print('An Error Occured')
return request.json()
def get_post_titles(r):
'''
Get a List of post titles
'''
posts = []
for post in r['data']['children']:
x = post['data']['title']
posts.append(x)
return posts
def get_results(r):
'''
Create a DataFrame Showing Title, URL, Score and Number of Comments.
'''
myDict = {}
for post in r['data']['children']:
myDict[post['data']['title']] = {'url':post['data']['url'],'score':post['data']['score'],'comments':post['data']['num_comments']}
df = pd.DataFrame.from_dict(myDict, orient='index')
return df
if __name__ == '__main__':
r = get_reddit(subreddit,listing,limit,timeframe)
df = get_results(r)
What’s Next?
Get Top Posts From Subreddit With Reddit API and Python
Reddit API JSON’s Documentation
How to use Reddit API With Python (Pushshift)
Get Reddit API Credentials with PRAW (Authentication)
Post on Reddit API With Python (PRAW)
Show Random Reddit Post in Terminal With Python
Congratulations, you now know how to scrape data using the Reddit API and parse the JSON of the response, without any wrapper or credentials, to make your own dashboard.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.