This post is part of the complete Guide on Python for SEO
In this post, we will see how to calculate the “BERT score” to see if a web page has a chance to answer a question asked in Google.
This is a translation of the amazing work done by Pierre Rouarch: “Calcul d’un score BERT pour le référencement SEO“
For those who didn’t know, Google launched the BERT algorithm in US English results on October 25, 2019, and in French results on December 9, 2019.
Thus, for longtail queries and/or questions, BERT will try to find the best pages to answer questions by making a “semantic” analysis of the content.
This gives the opportunity to see results where Google answer directly to a question. Here is an example: “When did Abraham Lincoln die and how?”.
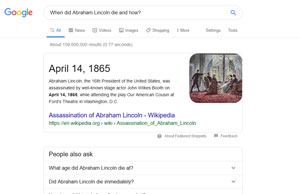
What is BERT?
Even if BERT is new in the SEO community, it was well-known to data scientists since 2018 (not that it is really old either). Precisely, Google made this algorithm open source on November 2, 2018, used mostly for Natural Language Processing.
You can download the full BERT source code on Github.
BERT means Bidirectional Encoder Representations from Transformers. The important word to remember here is Bidirectional.
This means that BERT can understand the meaning of a word by analyzing the context before and after the word.
Warning, to be efficient, BERT has been trained on a large corpus of text, including Wikipedia.
How is BERT (basic) Pre-Trained?
BERT uses 2 unsupervised tasks to train its model:
- The Masked Language Model (MLM) whose purpose is to discover the probability that a word is missing from a sentence.
- The Next Sentence Processing (NSP) whose purpose is, as its name suggests, to process and predict what will be the next sentence after the current sentence.
What can BERT be Used for?
Once pre-trained, we can use BERT to make him process more precise tasks (what we call “fine-tuning”) like:
- Sentiment analysis on text;
- Questions and answers tasks (what we cover here);
- Identity recognition: to know if we talk about a person, a location or a date for example.
How can Google use BERT?
Dawn Anderson wrote in the Search Engine Journal a detailed in-depth post on BERT and Google, BERT can solve a number of existing problems in the understanding of languages, such as lexical ambiguities (words that can be nouns, verbs or adjectives), polysemy and homonyms (words with multiple meanings), anaphora and cataphora resolution.
It can also, and this is the core of this blog post, answer questions straight into search results.
Important note: since BERT pre-trained models on questions and answers are currently in English, this tool will only work in English on Google.com.
If someone can find a french model, make sure that you leave a comment in the original blog post on anakeyn.com.
What Will We Need?
To test this program, I give you two options: either you test it on your computer, or in Google Colab.
Run the Code Locally on Your Computer
As always, we advise you to install Python with Anaconda (version 3.7 as of today) that contains not only the basic tools for Data Scientists but also the Spyder IDE and Jupyter Notebook that lets you create and share documents running Python codes (Here we will use Google Colab).
Nota Bene: We will use here the Deep Learning library PyTorch (by FaceBook) with Transformers (by Hugging Face) and not Keras and Tensorflow (by Google) to work with BERT algorithm (by Google). This might seem weird, but it works on Python 3.7.
Then, go to Github to download the source code.
Make sure that you clone the repository under a repository named «Bert_Squad_SEO » (without « – »), it will be useful in Google Colab.
Source Code: Bert_Squad_SEO_Score.py
Start Spyder and open the Bert_Squad_SEO_Score.py code.
Get all pre-trained models with SQuAD on Hugging Face.
Right now, we have 2:
- ‘
bert-large-uncased-whole-word-masking-finetuned-squad’ - ‘
bert-large-cased-whole-word-masking-finetuned-squad’
The n_best_size parameters show the number of best answers that we want for each document (web Pages in this case). 20 is more than enough. The average score of the top 20 answers will be used as our BERT Score (between 0 and 1) for each web page.
Add your question (in English) in the myKeyword variable.
# -*- coding: utf-8 -*-
"""
Created on Sun Dec 15 16:03:38 2019
@author: Pierre
"""
#############################################################
# Bert_Squad_SEO_Score.py
# Anakeyn Bert Squad Score for SEO Alpha 0.1
# This tool provide a "Bert Score" for first max 30 pages responding to a question in Googe.
#This tool is using Bert-SQuad created by Kamal Raj. We modified it to calculate a "Bert-Score"
# regarding severall documents and not a score inside a unique document.
# see original BERT-SQuAD : #https://github.com/kamalkraj/BERT-SQuAD
#############################################################
#Copyright 2019 Pierre Rouarch
# License GPL V3
#############################################################
myKeyword="When Abraham Lincoln died and how?"
from bert import QA
#from bert import QA
n_best_size = 20
#list of pretrained model
#https://huggingface.co/transformers/pretrained_models.html
#!!!!! instantiate a BERT model fine tuned on SQuAD
#Choose your model
#'bert-large-uncased-whole-word-masking-finetuned-squad'
#'bert-large-cased-whole-word-masking-finetuned-squad'
model = QA('bert-large-uncased-whole-word-masking-finetuned-squad', n_best_size)
Necessary Libraries
Some of the needed libraries include Pandas, random, googlesearch, requests and BeautifulSoup.
#import needed libraries
import pandas as pd
import numpy as np
#pip install google #to install Google Search by Mario Vilas see
#https://python-googlesearch.readthedocs.io/en/latest/
import googlesearch #Scrap serps
#to randomize pause
import random
import time #to calcute page time download
from datetime import date
import sys #for sys variables
import requests #to read urls contents
from bs4 import BeautifulSoup #to decode html
from bs4.element import Comment
#remove comments and non visible tags from html
def tag_visible(element):
if element.parent.name in ['style', 'script', 'head', 'title', 'meta', '[document]']:
return False
if isinstance(element, Comment):
return False
return True
Scrape 30 First Pages from Google
We will now scrape URLs from the 30 first web pages that provide the best answer to our question in Google.
Additional comment to the original content by the author. Scraping Google is against Google official Guidelines. If you do this, make sure that you know what you are doing and be respectful.
JC Chouinard
To do this, we will use the googlesearch library by Mario Vilas that we already used.
###############################################
# Search in Google and scrap Urls
###############################################
dfScrap = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date'])
myNum=10
myStart=0
myStop=10 #get by ten
myMaxStart=30 #only 30 pages
myLowPause=5
myHighPause=15
myDate=date.today()
nbTrials = 0
myTLD = "com" #Google tld -> we search in google.com
myHl = "en" #in english
#this may be long
while myStart < myMaxStart:
print("PASSAGE NUMBER :"+str(myStart))
print("Query:"+myKeyword)
#change user-agent and pause to avoid blocking by Google
myPause = random.randint(myLowPause,myHighPause) #long pause
print("Pause:"+str(myPause))
#change user_agent and provide local language in the User Agent
#myUserAgent = getRandomUserAgent(myconfig.userAgentsList, myUserAgentLanguage)
myUserAgent = googlesearch.get_random_user_agent()
print("UserAgent:"+str(myUserAgent))
#myPause=myPause*(nbTrials+1) #up the pause if trial get nothing
#print("Pause:"+str(myPause))
try :
urls = googlesearch.search(query=myKeyword, tld=myTLD, lang=myHl, safe='off',
num=myNum, start=myStart, stop=myStop, domains=None, pause=myPause,
tpe='', user_agent=myUserAgent)
df = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date'])
for url in urls :
print("URL:"+url)
df.loc[df.shape[0],'page'] = url
df['keyword'] = myKeyword #fill with current keyword
# df['tldLang'] = myTLDLang #fill with current country / tld lang not use here all in in english
df['position'] = df.index.values + 1 + myStart #position = index +1 + myStart
df['BERT_score'] = 0 #not yet calculate
df['source'] = "Scrap" #fill with source origin here scraping Google
#other potentials options : Semrush, Yooda Insight...
df['search_date'] = myDate
dfScrap = pd.concat([dfScrap, df], ignore_index=True) #concat scraps
# time.sleep(myPause) #add another pause
if (df.shape[0] > 0):
nbTrials = 0
myStart += 10
else :
nbTrials +=1
if (nbTrials > 3) :
nbTrials = 0
myStart += 10
#myStop += 10
except :
exc_type, exc_value, exc_traceback = sys.exc_info()
print("ERROR")
print(exc_type.__name__)
print(exc_value)
print(exc_traceback)
# time.sleep(600) #add a big pause if you get an error.
#/while myStart < myMaxStart:
dfScrap.info()
dfScrapUnique=dfScrap.drop_duplicates() #remove duplicates
dfScrapUnique.info()
#Save
dfScrapUnique.to_csv("dfScrapUnique.csv", sep=",", encoding='utf-8', index=False) #sep ,
dfScrapUnique.to_json("dfScrapUnique.json")
Extract Content From Scraped Pages
We will now extract content from pages. First, we have to remove non-HTML documents.
###### filter extensions
extensionsToCheck = ('.7z','.aac','.au','.avi','.bmp','.bzip','.css','.doc',
'.docx','.flv','.gif','.gz','.gzip','.ico','.jpg','.jpeg',
'.js','.mov','.mp3','.mp4','.mpeg','.mpg','.odb','.odf',
'.odg','.odp','.ods','.odt','.pdf','.png','.ppt','.pptx',
'.psd','.rar','.swf','.tar','.tgz','.txt','.wav','.wmv',
'.xls','.xlsx','.xml','.z','.zip')
indexGoodFile= dfScrapUnique ['page'].apply(lambda x : not x.endswith(extensionsToCheck) )
dfUrls2=dfScrapUnique.iloc[indexGoodFile.values]
dfUrls2.reset_index(inplace=True, drop=True)
dfUrls2.info()
#######################################################
# Scrap Urls only one time
########################################################
myPagesToScrap = dfUrls2['page'].unique()
dfPagesToScrap= pd.DataFrame(myPagesToScrap, columns=["page"])
#dfPagesToScrap.size #9
#add new variables
dfPagesToScrap['statusCode'] = np.nan
dfPagesToScrap['html'] = '' #
dfPagesToScrap['encoding'] = '' #
dfPagesToScrap['elapsedTime'] = np.nan
for i in range(0,len(dfPagesToScrap)) :
url = dfPagesToScrap.loc[i, 'page']
print("Page i = "+url+" "+str(i))
startTime = time.time()
try:
#html = urllib.request.urlopen(url).read()$
r = requests.get(url,timeout=(5, 14)) #request
dfPagesToScrap.loc[i,'statusCode'] = r.status_code
print('Status_code '+str(dfPagesToScrap.loc[i,'statusCode']))
if r.status_code == 200. : #can't decode utf-7
print("Encoding="+str(r.encoding))
dfPagesToScrap.loc[i,'encoding'] = r.encoding
if r.encoding == 'UTF-7' : #don't get utf-7 content pb with db
dfPagesToScrap.loc[i, 'html'] =""
print("UTF-7 ok page ")
else :
dfPagesToScrap.loc[i, 'html'] = r.text
#au format texte r.text - pas bytes : r.content
print("ok page ")
#print(dfPagesToScrap.loc[i, 'html'] )
except:
print("Error page requests ")
endTime= time.time()
dfPagesToScrap.loc[i, 'elapsedTime'] = endTime - startTime
#/
dfPagesToScrap.info()
#merge dfUrls2, dfPagesToScrap -> dfUrls3
dfUrls3 = pd.merge(dfUrls2, dfPagesToScrap, on='page', how='left')
#keep only status code = 200
dfUrls3 = dfUrls3.loc[dfUrls3['statusCode'] == 200]
#dfUrls3 = dfUrls3.loc[dfUrls3['encoding'] != 'UTF-7'] #can't save utf-7 content in db ????
dfUrls3 = dfUrls3.loc[dfUrls3['html'] != ""] #don't get empty html
dfUrls3.reset_index(inplace=True, drop=True)
dfUrls3.info() #
dfUrls3 = dfUrls3.dropna() #remove rows with at least one na
dfUrls3.reset_index(inplace=True, drop=True)
dfUrls3.info() #
#Remove Duplicates before calculate Bert Score
dfPagesUnique = dfUrls3.drop_duplicates(subset='page') #remove duplicate's pages
dfPagesUnique = dfPagesUnique.dropna() #remove na
dfPagesUnique.reset_index(inplace=True, drop=True)
#reset index
Input BERT Score
We will extract the visible part of the HTML. We will then save the information given by the prediction and return Excel files:
answer = model.predict( dfPagesUnique.loc[i, 'body'],myKeyword)
#Create body from HTML and get Bert_score ### may be long
dfPagesAnswers = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date','answers','starts', 'ends', 'local_probs', 'total_probs'])
for i in range(0,len(dfPagesUnique)) :
soup=""
print("Page keyword tldLang i = "+ dfPagesUnique.loc[i, 'page']+" "+ dfPagesUnique.loc[i, 'keyword']+" "+str(i))
encoding = dfPagesUnique.loc[i, 'encoding'] #get previously
print("get body content encoding"+encoding)
try:
soup = BeautifulSoup( dfPagesUnique.loc[i, 'html'], 'html.parser')
except :
soup=""
if len(soup) != 0 :
#TBody Content
texts = soup.findAll(text=True)
visible_texts = filter(tag_visible, texts)
myBody = " ".join(t.strip() for t in visible_texts)
myBody=myBody.strip()
#myBody = strip_accents(myBody, encoding).lower() #think to do a global clean instead
myBody=" ".join(myBody.split(" ")) #remove multiple spaces
print(myBody)
dfPagesUnique.loc[i, 'body'] = myBody
answer = model.predict( dfPagesUnique.loc[i, 'body'],myKeyword)
print("BERT_score"+str(answer['mean_total_prob']))
dfPagesUnique.loc[i, 'BERT_score'] = answer['mean_total_prob']
dfAnswer = pd.DataFrame(answer, columns=['answers','starts', 'ends', 'local_probs', 'total_probs'])
dfPageAnswer = pd.DataFrame(columns=['keyword', 'page', 'position', 'BERT_score', 'source', 'search_date','answers','starts', 'ends', 'local_probs', 'total_probs'])
for k in range (0, len(dfAnswer)) :
dfPageAnswer.loc[k, 'keyword'] = dfPagesUnique.loc[i, 'keyword']
dfPageAnswer.loc[k, 'page'] = dfPagesUnique.loc[i, 'page']
dfPageAnswer.loc[k, 'position'] = dfPagesUnique.loc[i, 'position']
dfPageAnswer.loc[k,'BERT_score'] = dfPagesUnique.loc[i, 'BERT_score']
dfPageAnswer.loc[k,'source'] = dfPagesUnique.loc[i,'source']
dfPageAnswer.loc[k,'search_date'] = dfPagesUnique.loc[i,'search_date']
dfPageAnswer.loc[k,'answers'] = dfAnswer.loc[k,'answers']
dfPageAnswer.loc[k,'starts'] = dfAnswer.loc[k,'starts']
dfPageAnswer.loc[k,'ends'] = dfAnswer.loc[k,'ends']
dfPageAnswer.loc[k, 'local_probs'] = dfAnswer.loc[k, 'local_probs']
dfPageAnswer.loc[k, 'total_probs'] = dfAnswer.loc[k, 'total_probs']
dfPagesAnswers = pd.concat([dfPagesAnswers, dfPageAnswer], ignore_index=True) #concat Pages Answers
dfPagesAnswers.info()
#Save Answers
dfPagesAnswers.to_csv("dfPagesAnswers.csv", sep=",", encoding='utf-8', index=False)
dfPagesUnique.info()
#Save Bert Scores by page
dfPagesSummary = dfPagesUnique[['keyword', 'page', 'position', 'BERT_score', 'search_date']]
dfPagesSummary.to_csv("dfPagesSummary.csv", sep=",", encoding='utf-8', index=False)
#Save page content in csv and json
dfPagesUnique.to_csv("dfPagesUnique.csv", sep=",", encoding='utf-8', index=False) #sep ,
dfPagesUnique.to_json("dfPagesUnique.json")
Results
2 files are interesting to us: dfPagesSummary.csv and dfPagesAnswers.csv.
dfPagesSummary.csv provide the BERT Scores for each page.
Here are the best-scored pages for the question « When did Abraham Lincoln die and how? ».
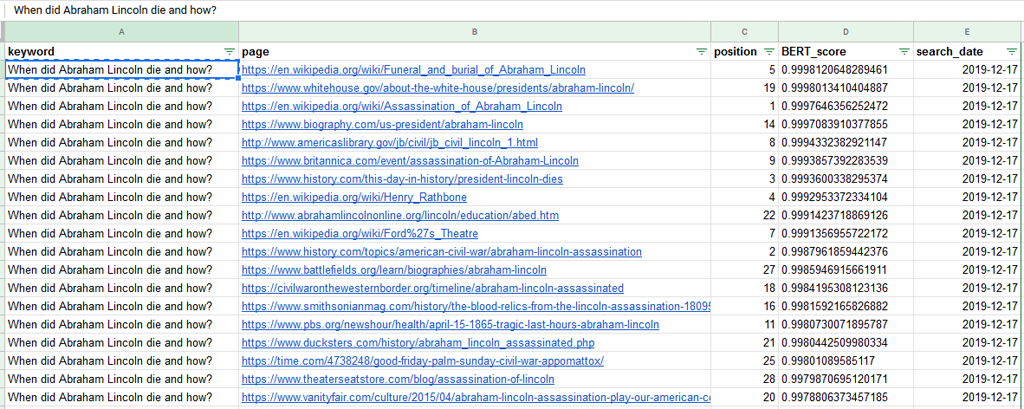
As you can see in the image, most pages that rank well have a high BERT score.
Let’s look at the dfPagesAnswers to sort results to si if the program answers to the question:
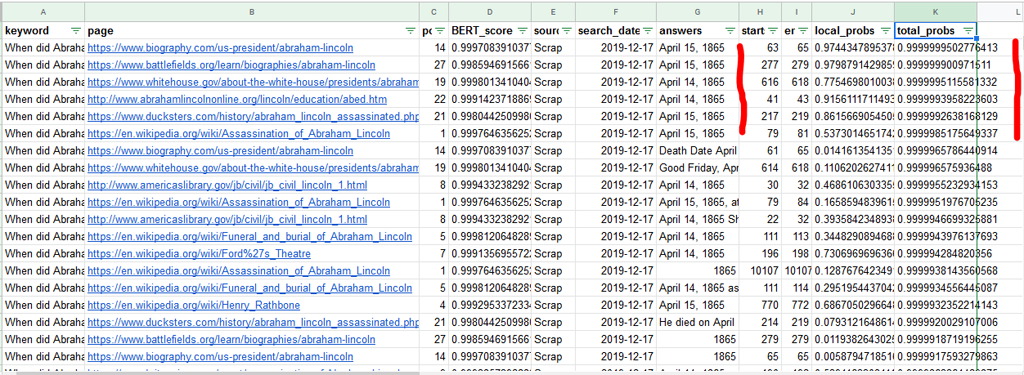
As we can see in the “answers” column, the program is efficient to find good answers. The score that we look at here is the “total_probs” score. This is the absolute score for the question (not the page). We see that scores are really important.
The “local_probs” score is the score for this answer compared to the other 19 answers.
Start and end elements show the number of the word (should I say the token) at the beginning and the end of the answer. If we would increase the interval surrounding the answer, we could see the context and have help to write efficient answers.
Rem: we could reuse BERT scores calculated this way and add them as ranking factors in SEO by adding them to our Deep Learning and Machine Learning classification models. (French)
Source Code: bert.py
We will not cover extensively the bert.py program, but only modifications that we have made to the original script created by Kamal Raj.
Reminder: the bert.py program is entirely accessible on Anakeyn’s Github.
Here we show the start of the program where we made changes:
- We modified « pytorch_transformers » into « transformers », the name has changed at Hugging Face (line 13);
- We have created the “n_best_size” parameter in the QA class that you can change in any way you like. (line 27 and 32);
- In
Load Modelwe have decided to load a model pre-trained by Hugging Face (view the entire list of models) instead of the pre-trained model by Kamal.
#Original by Kamal Raj see https://github.com/kamalkraj/BERT-SQuAD
#modified by Pierre Rouarch 16/12/2019. see #PR
from __future__ import absolute_import, division, print_function
import collections
import logging
import math
import numpy as np
import torch
#PR new : transformers instead of pytorch_transformers
from transformers import (WEIGHTS_NAME, BertConfig,
BertForQuestionAnswering, BertTokenizer)
from torch.utils.data import DataLoader, SequentialSampler, TensorDataset
from utils import (get_answer, input_to_squad_example,
squad_examples_to_features, to_list)
RawResult = collections.namedtuple("RawResult",
["unique_id", "start_logits", "end_logits"])
class QA:
def __init__(self,model_path: str, n_best_size=20):
self.max_seq_length = 384 #original 384
self.doc_stride = 128
self.do_lower_case = True
self.max_query_length =64# orig 64
self.n_best_size = n_best_size #orig 20 #PR we set this as an input parameter in QA
self.max_answer_length = 30
self.model, self.tokenizer = self.load_model(model_path)
if torch.cuda.is_available():
self.device = 'cuda'
else:
self.device = 'cpu'
self.model.to(self.device)
self.model.eval()
def load_model(self,model_path: str,do_lower_case=False):
#old version by Kam
#config = BertConfig.from_pretrained(model_path + "/bert_config.json")
#tokenizer = BertTokenizer.from_pretrained(model_path, do_lower_case=do_lower_case)
#model = BertForQuestionAnswering.from_pretrained(model_path, from_tf=False, config=config)
#PR use a standard https://huggingface.co/transformers/pretrained_models.html SQuAD fine Tune Model
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForQuestionAnswering.from_pretrained(model_path)
return model, tokenizer
Source Code: utils.py
Again, we are not going to comment and post the entire utils.py program.
Reminder: the utils.py program is entirely accessible on Anakeyn’s Github.
Modifications go like this:
- We modified « pytorch_transformers » into « transformers », the name has changed at Hugging Face (line 12);
- At the end of the program, in the
get_answerfunction, we have calculated “absolute” scores,total_probs(giving probabilities between 0 and 1) fromtotal_scoresunder a logit (between – ∞ and + ∞ ) for each answer found on the page. - The
mean_total_probs, being the Mean of these values, will become our BERT Score.
#PR get values in separate lists
total_scores = []
answers = []
starts = []
ends = []
for entry in nbest:
total_scores.append(entry.start_logit + entry.end_logit)
answers.append(entry.text)
starts.append(entry.start_index)
ends.append(entry.end_index)
#relative to the document sum(local_probs)==1 we keep it
probs = _compute_softmax(total_scores)
#PR Total_probs create from total_scores (which is a logit)
total_probs = []
for score in total_scores : #total score =
total_probs.append(1/(1+math.exp(-score)))
mean_total_prob = np.mean(total_probs )
#PR change answer outputs
answer = {"answers" : answers, #responses texts
"starts" : starts, #Start indexes of responses
"ends" : ends, #end indexes responses
"doc_tokens" : example.doc_tokens, #document tokens
"local_probs" : probs, #all best local probs (old indicators or results after softmax)
"total_scores" :total_scores, #All best scores (not softmaxed)
"total_probs" : total_probs, #All best probs (not softmaxed)
"mean_total_prob" : mean_total_prob #the new bert score indicator !!!
}
return answer
Run the Code on Colab
Google Colab is an open-source online tool by Google that lets you execute Jupyter Notebooks straight into the Cloud.

A Jupyter Notebook is a .ipynb file that can contain text, images and executable source code (including Python).
The advantage of Google Colab is that you can use a virtual GPU graphic processor, or a Tensor Processing Unit (TPU), which can increase speed.
Google Colab can run with Google Drive. Thus, you can easily save your notebooks and your data.
Notebook Bert_Squad_SEO_Score_Colab.ipynb
On our Github, you’ll find the Notebook Bert_Squad_SEO_Score_Colab.ipynb.
To make it easier to use in Google Colab, this Jupyter Notebook contains Bert_Squad_SEO_Score.py, bert.py and utils.py.
Upload on Google Drive
First, you will need to upload the Bert_Squad_SEO_Score_Colab.ipynb file in a repository (example Bert_Squad_SEO) on your Google Drive.
To upload the file, click on New on the top left.
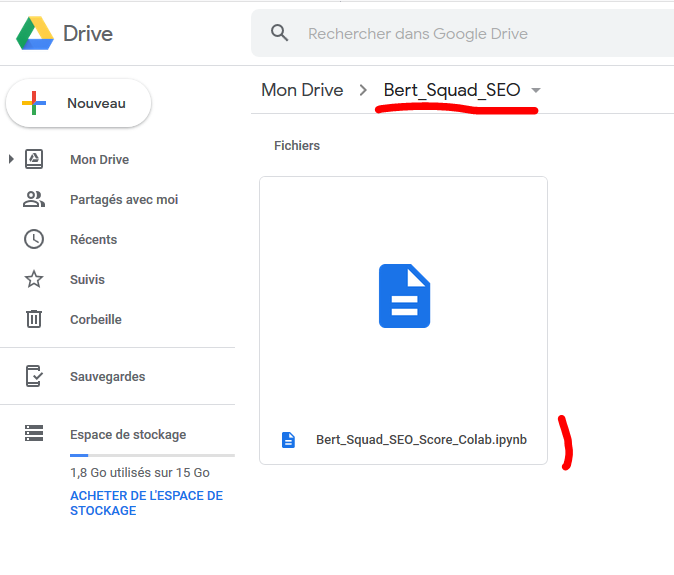
Careful! Don’t use hyphens in your file names, use underscore instead. Hyphens « – » tend to have a problem running in Colab, I don’t know why.
Once the environment setted-up, click on the Notebook:
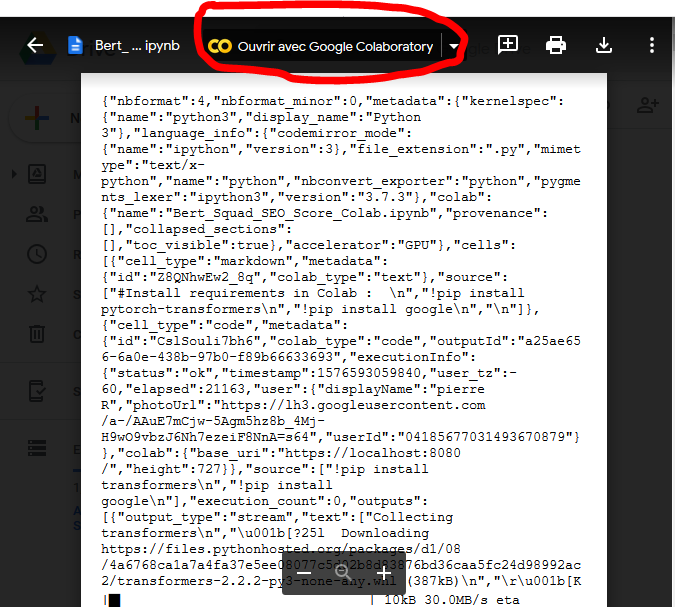
The system will prompt you to open it with Google Colab.
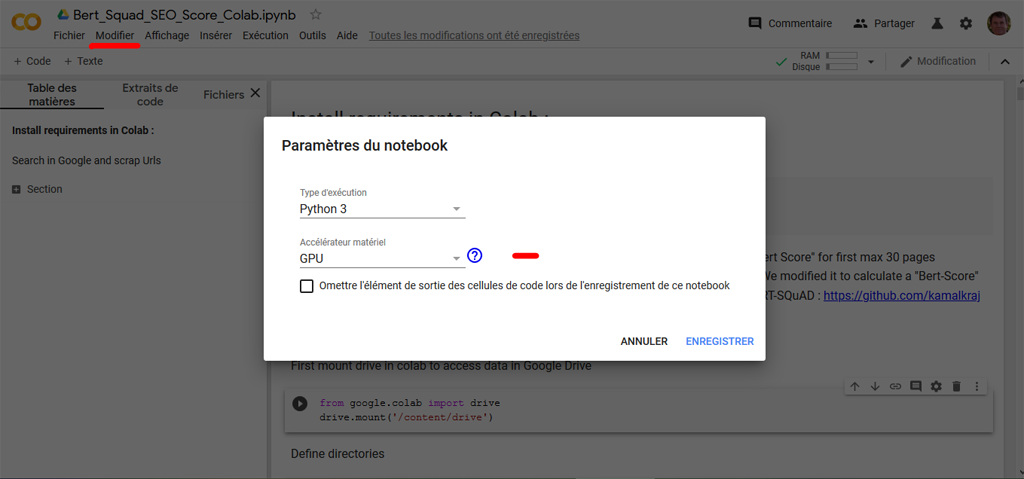
Before you do anything else, it is necessary to set-up the utilization of the Graphical Processing Unit (GPU) for your Notebook.
Edit > Notebook Settings
You can now execute the Notebook. It will run code snippet by code snippet.
We will not come back on what we already have seen in the section running the code locally on your computer. We will only talk about Google Colab specifics.
Load Libraries not Included in Google Colab
Google Colab includes a lot of libraries by default, but some are still missing to run our code. Here we will import « transformers » that manage BERT for Pytorch and « google » library that will be useful to scrape Google Web pages.
In Google Colab, use the “!pip” command to install packages.
!pip install transformers
!pip install google
Connect Google Drive to Google Colab
To use Google Drive to import or save data, you need to mount it (like in Unix/Linux).
Here is the command:
from google.colab import drive
drive.mount('/content/drive')
When you run the command, Google Colab prompts you to input your authorization code. Follow the link and follow the instructions. Add your code in the right section and click “enter”,
Once the connection is made with Google Drive, you can start to use it.
import os
base_dir = 'drive/My Drive/Bert_Squad_SEO'
print(base_dir)
drive/My Drive/Bert_Squad_SEO
But wait! For unknown reasons, the repository to your Google drive is on the “drive/My Drive/” Path, not the “content/drive/My Drive/ ” path.
Execute the Code Line-by-line
At some point, you will encounter this line:
myKeyword="When did Abraham Lincoln die and how?"
you can change to any question that you want.
As you can see, the code execution in Google Colab is much faster than on a computer without GPU.
In the end, the system will save results on your Google Drive.
What are your results? For which queries?
Other Technical SEO Guides With Python
- Find Rendering Problems On Large Scale Using Python + Screaming Frog
- Recrawl URLs Extracted with Screaming Frog (using Python)
- Find Keyword Cannibalization Using Google Search Console and Python
- Get BERT Score for SEO
- Web Scraping With Python and Requests-HTML
- Randomize User-Agent With Python and BeautifulSoup
- Create a Simple XML Sitemap With Python
- Web Scraping with Scrapy and Python

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.