In this post, we are going to see how to make a mirror of a web page or even your entire website with Wget and Python. Then, we will run the mirror on Ngrok to make a public URL.
That way you will be able to make changes and test it in any tool: Screaming Frog, GTMetrix, Google tools (lighthouse, mobile-friendly test, Rich Results,…), or most other tools.
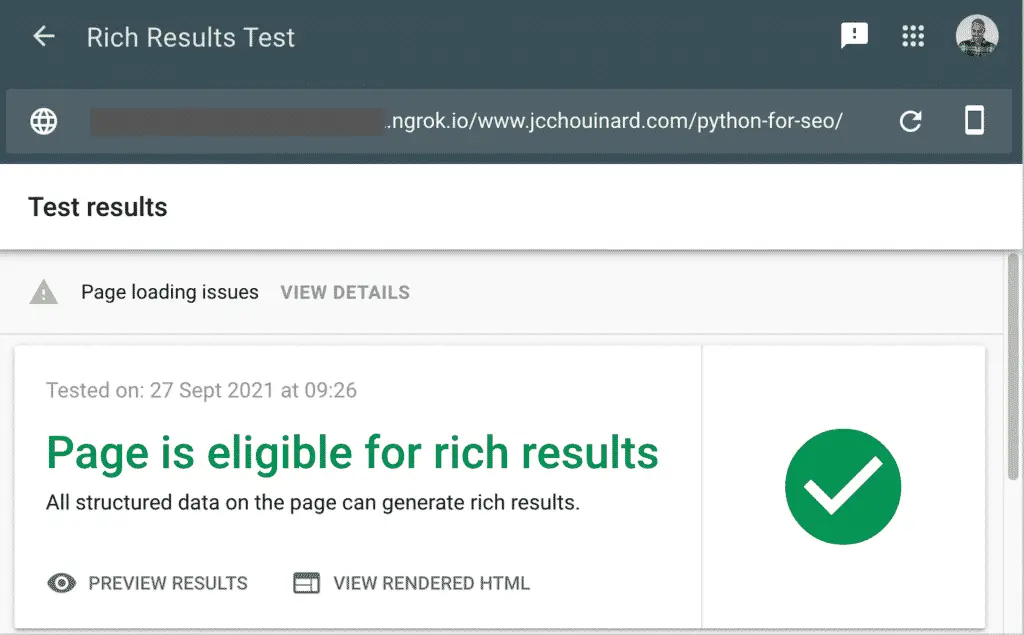
For example, I could test the structured data implementation before sending it to the web developers for implementation.
You will need to install Python first.
Install Ngrok and Wget
On Mac
We will install both packages using Homebrew.
Open Terminal and run:
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
$ brew install wget
$ brew cask install ngrok
On Windows
To install Ngrok on Windows according to Twilio.
- Download the ngrok ZIP file
- Unzip the ngrok.exe file
- Place the ngrok.exe in a folder of your choosing
- Make sure the folder is in your PATH environment variable
Read this guide to install Wget on Windows.
Extract Web pages with Wget
WGET is a free tool to crawl websites and download files via the command line. We are going to use it to download files from a website to make a copy on NGrok.
Extract a single Web Page
Open the Terminal and run:
$ wget -E -H -k -K -p --convert-links https://www.example.com/path
Extract Multiple URLs
Add all urls in a urls.txt file.
https://example.com/1
https://example.com/2
https://example.com/3
Then, open the Terminal and run this command.
$ wget -E -H -k -K -p --convert-links -i urls.txt
Run a Python Server
$ python -m http.server
Run Ngrok
To run Ngrok on the server you created, you need to open another Terminal.
In the second Terminal, run this command.
$ ngrok http http://0.0.0.0:8000/
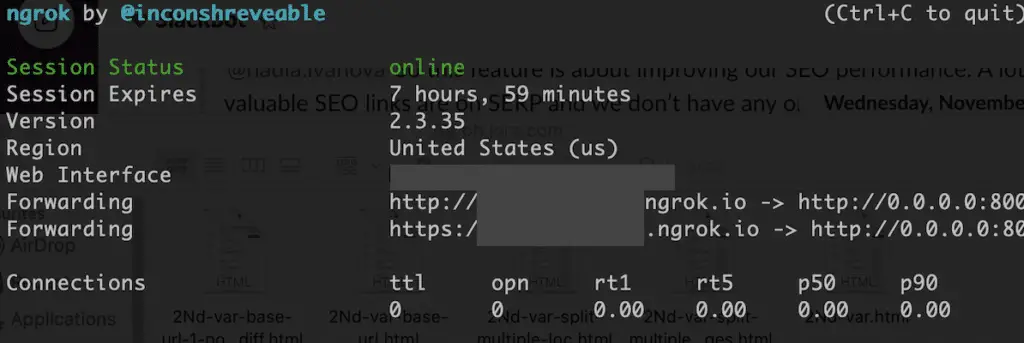
Copy the forwarding URL in your browser and that’s it.
Conclusion
This is it. If you go to the Ngrok url, you now have a public URL that you can use to test in any tool.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.