This article is part of the Complete Guide on Google Search Console (GSC)
The Index Coverage report helps you understand quickly what’s happening with your website. By using the index coverage report, you can understand which web pages have problems and which domains.
There’s a lot of coverage issues that can happen and they are divided into four status: error, warning, excluded & valid.
Google is saying that this report is not necessary if you have less than 500 pages. Alternatively, you can use queries on Google searches like site:example.com to show index size.
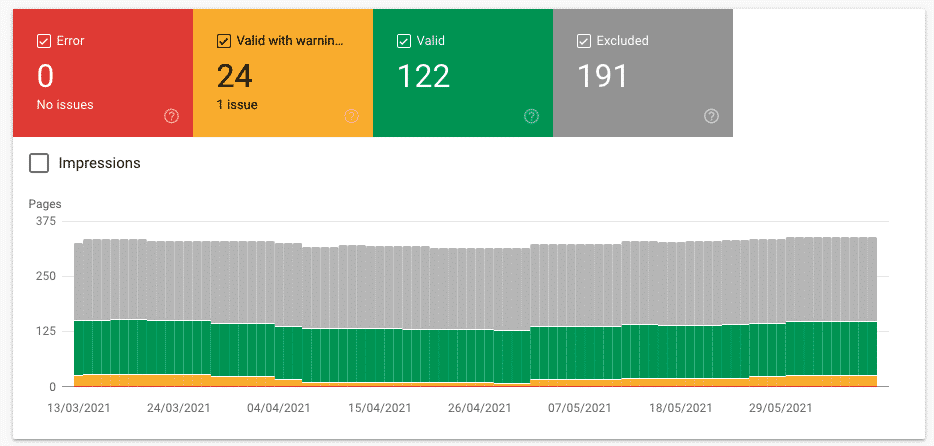
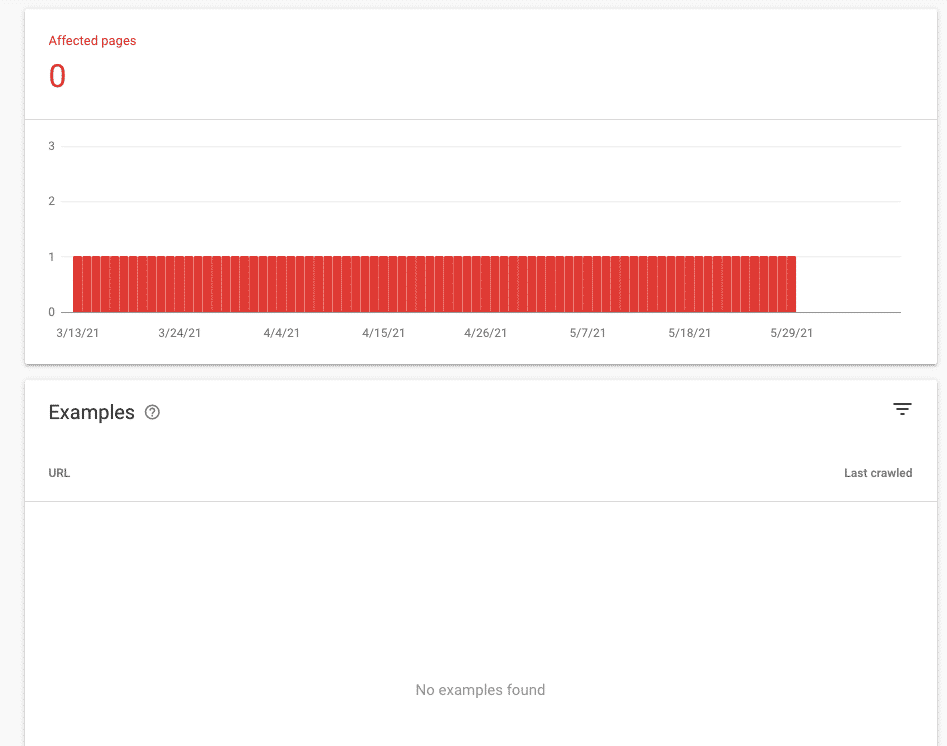
Index Report is Heavily Sampled
The index Report has only three months of data.
Not only that.
When issues are fixed, the URLs are removed from the examples, which is horrible to look at data over time.
How to get more data from the Index Report?
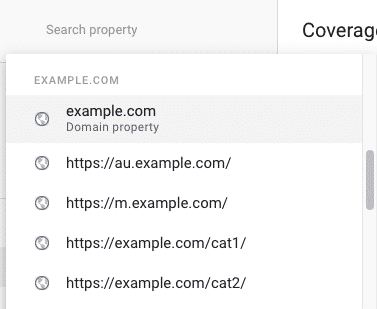
To dive deeper into your performance report you can validate subdomains and subdirectories, and use the Google Search Console API.
Validate Subdirectories
Glenn Gabe has written a fantastic guide on How to juice up your Index Coverage reporting by adding directories to Google Search Console (GSC).
When possible, this is the single most useful technique to gain more insights into your performance report and your indexation issues.
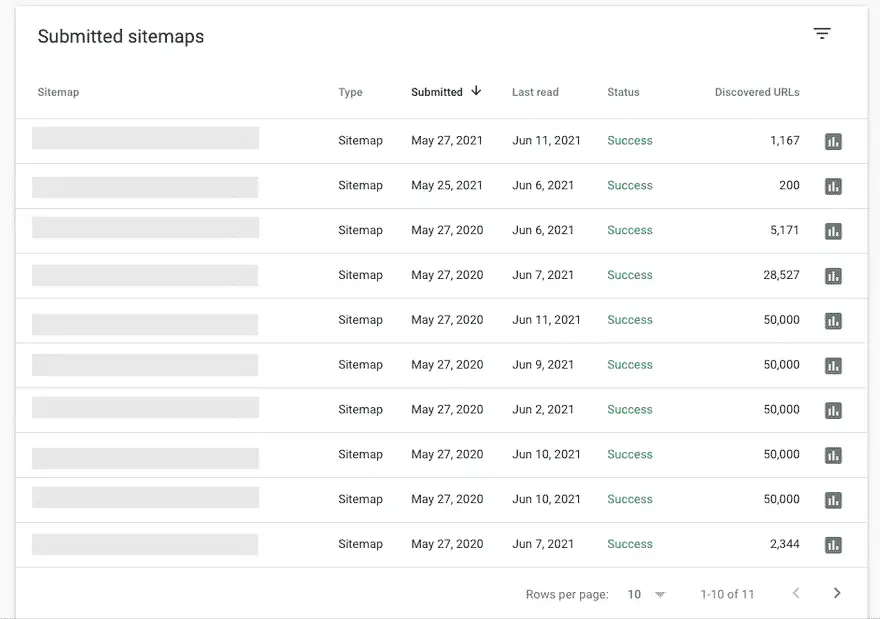
Break-up Your Sitemaps
Some sites have opted for the URL structure where all URLs are located at the root.
Hence, no subfolders.
This causes a problem from an analytics point of view, being unable to dive deeper into subdirectories.
Barry Adams shared an approach that recommends splitting sitemaps into smaller chunks. This can be useful to gain more insights into indexation issues.
Backup the Data
Index report is super important. It is even more important for larger sites.
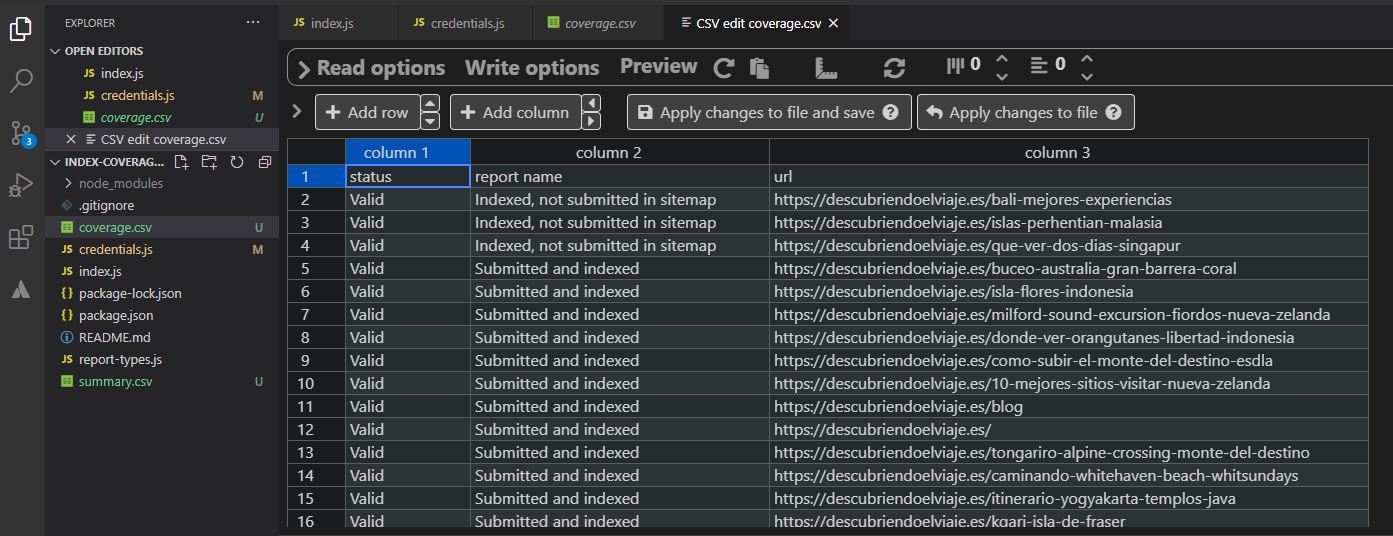
I’d recommend that you back up the data from the index report at least once in a while to have an idea of how your site is indexed over time.
For now, it is still a manual process. This is why we are forced to rely on techniques such as the one shared by Jose Luis Hernando Sanz to automate a bit of the process (image below).
Does the Google Search Console API cover the Index Report?
Unfortunately no. The Google Search Console API does not cover the index report. It is about time they do.
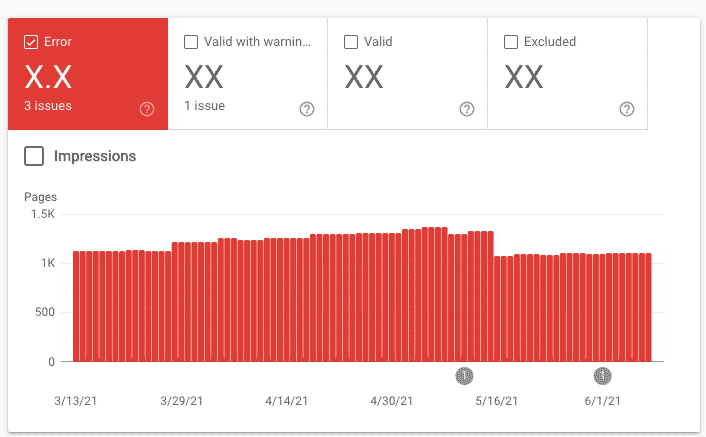
Errors
Error Submitted URL seems to be a Soft 404
There are some pages submitted through an XML sitemap that has content that’s saying it’s a 404 page. However, the URL doesn’t return an HTTP 404 status code. That means that you have a soft 404. This can happen a lot on e-commerce sites.
The solution: Analyze if you need this page to be a 404. If yes, make sure that the HTTP status code returns the real action and is removed from your sitemap. If not, change the content to remove this idea that the page “can’t be found”.
Error Submitted URL has crawl issue
This error is pretty complicated since it’s like an “other” category for all the other crawl errors that haven’t been classified yet. The first thing to do would be to fetch the URL targeted by this error yourself to see if you can find a pattern.
The solution: It might be javascript redirects or Google requests being blocked. It’s tough to provide you with a solution when you’re facing a broad issue like this one.
Error Submitted URL not found (404)
Similar to the 404 error, the only difference is that you submitted the URL through an XML sitemap.
The solution: You can either remove these URLs from your sitemap or you can fix them individually if they are relevant (putting them accessible again or adding a 301 redirect to similar pages.).
Error Server error (5xx)
You have some links that are not accessible by Google because of a server problem.
The solution: Usually, this type of error is temporary and will solve itself. However, it’s best practice to analyze the URL individually by yourself. Make sure to contact your hosting provider if this error is related to a lot of pages and doesn’t seem to go away, even if you change user-agent.
Error Redirect error
These URLs cannot be crawled by Google because they might redirect to a redirect that’s too long, because there’s a redirect loop or because the redirect chain is too long(More than 5).
The solution: Depending on the problem, you should investigate your redirect organization. Make sure they are not too long or that they are sending searchers to the right place is crucial for your technical SEO health.
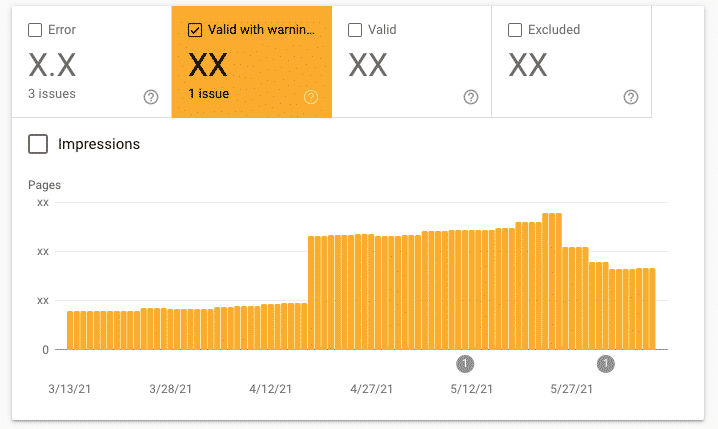
Warning
Warning Indexed, though blocked by robots.txt
Those URLs have been indexed by Google, but they were blocked by your robots.txt file. Since it was not supposed to happen, that’s why you’re getting this warning code.
The solution: You should review your robots.txt file and possibly double-check the noindex on those pages.
Page indexed without content
If Google deems a page important enough to be indexed, but can’t read its content.
The solution: Inspect the page with the URL inspection tool. One of the cases that I have seen is that the page fetch was `Failed: Blocked due to access forbidden (403)`. For some reason, the custom Cloudflare rules were blocking genuine Googlebot requests to the URLs.
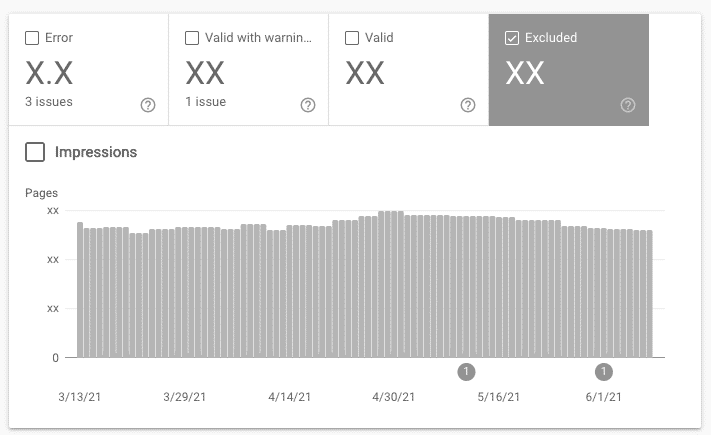
Excluded
Blocked by page removal tool
This happens when a webmaster uses the URL removal request.
The solution: After 90 days the URL will be reindexed unless you added a noindex tag. If you want to cancel a removal, go to the removal tool and cancel the request.

Blocked due to unauthorized request (401)
Google wasn’t authorized to access those URLs because of a 401 HTTP response(Unauthorized error).
The solution: Make sure that those URLs are not considered important. Otherwise, it’s a big problem because you’re forbidding Google(and possibly visitors) to access those URLs. Reverse-engineer how Google found those URLs and make sure to check external as well as internal links.
Excluded Crawled – currently not indexed
Google has crawled your URLs but they are not indexed yet. It might be because Google doesn’t think it’s important enough to index it or because it’s just freshly crawled.
The solution: Make sure the content of those URLs isn’t thin or duplicated. You can also review your internal linking on those pages because the volume might be too low. If the URLs are still not indexed, it’s only a matter of time.
Excluded Soft 404
Similar to the error we got earlier, these pages have content that’s saying it’s a 404 page. However, the URL doesn’t return an HTTP 404 status code. That means that you have a soft 404.
The solution: Change the content or double-check the HTTP status code.
Excluded Page with redirect
This one is really easy. Since those URLs are being redirected, they are not indexed by Google.
The solution: There’s not much you can do inside Google Search Console. A possibility is to take a look at your htaccess or nginx rules(depending on your choice of HTTP server) to see if there are any redirection rules that shouldn’t be there.
Excluded: Blocked by robots.txt
These URLs are blocked because of your robots.txt file. It’s SUPER crucial that you make sure that these pages are not important or that it’s not blocking your domain. Otherwise, your website will become invisible to Google’s eyes.
The solution: Make sure that the URLs are not important and change your robots.txt file otherwise.
Excluded: Discovered – currently not indexed
Google just discovered those URLs so they are not crawled or indexed yet.
The way I see it: Google found a URL, put it in its crawl queue waiting to be processed. The Discovered - currently not indexed contains, but not limited to, that unprocessed crawl queue.
The solution: This one is about monitoring since there’s a lot of reasons why these URLs might not be crawled or indexed. Check the domain authority of your website, your speed, and your availability. Those factors might be in play here. You might also have a crawling budget too small for those pages.
Excluded: Crawl anomaly
Since January 2021, the crawl anomaly has been retired.
Submitted URL blocked due to other 4xx issues
These URLs cannot be accessed because they received HTTP status code 4XX (It’s not 404, 401, or 403). You submitted them to your XML sitemap beforehand.
The solution: Try to replicate the problem by using the URL inspection tool. Add those URLs to your sitemap once the issue has been solved.
Submitted URL returned 403
These URLs were submitted to your XML sitemap but Google wasn’t allowed to access these URLs.
The solution: If those pages should be available to the public, remove their restricted access. If they should not, remove them from your sitemap.
Blocked due to other 4xx issues
These URLs cannot be accessed because they received HTTP status code 4XX (It’s not 404, 401, or 403).
The solution: The same solution as for the submitted URL blocked due to other 4xx issues.
Blocked due to access forbidden (403)
Google bots are not allowed to see these URLs.
The solution: Judge if those URLs are important to rank for. If they are, remove the restricted access, otherwise put noindex directly in your HTML source. This can also come from Cloudflare blocking Googlebot.
Excluded Duplicate, Google chose different canonical than user
By crawling, Google found those URLs and considered the content has duplicated, even if you already canonicalized. This one is happening a lot on thin content pages.
The solution: Fetch those URLs and try to understand why Google has selected those pages as preferred URLs
Excluded Excluded by ‘noindex’ tag
These URLs are not indexed because you have a noindex tag targeted on them.
The solution: Check the HTML to see if you find a HTML tag like this one:
<meta name="robots" content="noindex">
Alternatively, look at the HTTP Header response (you can use the Ayima Chrome extension), to see if you don’t have an X-Robots-Tag: noindex.
Check if there’s no internal linking going to those pages because these pages will still be available otherwise (and you don’t want that).
Excluded Alternate page with proper canonical tag
All of those pages are duplicates of other pages and are well canonicalized.
The solution: That’s Google’s way of saying “good job!”. You have nothing to do.
Excluded Duplicate, submitted URL not selected as canonical
Another problem with the XML sitemap. You submitted those URLs through your sitemap, but you asked Google to index these pages and you have not defined canonical URLs.
The solution: Add the right canonical URLs to those pages.
Excluded Not found (404)
Those URLs were not included in your XML sitemap but Google still found them. Since they have a 404 on them, they cannot be indexed.
The solution: Make sure to improve the content or redirect them to a worthy alternative(if they are important pages). Otherwise, you might get a soft 404 from this.
Excluded Duplicate without user-selected canonical
Google thinks that those URLs are duplicates. That means that it included them from the index because they don’t seem like the preferred canonical version.
The solution: Noindex those pages if they should not be indexed. Otherwise, simply add canonical URLs to the preferred version of those URLs.
Valid
Valid Indexed, not submitted in sitemap
Those pages are not submitted in your XML sitemap, but Google still found them.
The solution: If those pages are not relevant, modify your robots.txt or put a noindex tag to make sure they are not indexed. If you need them, add them to your sitemap.
Valid Submitted and indexed
These URLs have been submitted through your sitemap and indexed correctly.
The solution: You have nothing to do, another great task done!
Other Articles in the Series on Google Search Console
- How to validate your site in GSC
- How to use the Performance Report in Google Search Console
- How to use the index coverage report
- How to use the URL Inspection Tool
- How to use the Crawl Stats Report
- How to use (and not use) URL Removal tool in GSC (Coming soon…)
- How to use URL Parameters Tools Without Killing Your Site (Coming soon…)
- Google Search Console Use Cases (Coming soon…)
- Regular Expressions (RegEx) in Google Search Console
Tl;dr
To summarize, the Index Coverage report shows you exactly which type of coverage issues you’re experiencing and how to solve them. It’s crucial to take debugging seriously to make sure your website’s most important pages are well indexed.

Tech marketer, SEO, and remote work advocate, Gab is the CMO at V2 Cloud. Living in Quebec City, he’s a big fan of hiking, traveling, gins, and telling bad jokes.