In this series on learning SEO with Google patents, I will explain what the Document Locator is, how it works, and how Google may use it in their infrastructure to provide search results.
The document locator is very relevant to SEO as it contains the search engine and the ranking component. It also has been mentioned in various patent authored by Sergey Brin, Jeffrey Dean, Paul Haahr, Steve Lawrence, etc.
Most of what is described here is based on the Google Patent named:
Enhanced document browsing with automatically generated links to relevant information
Navigation
Show
What is the Document Locator?
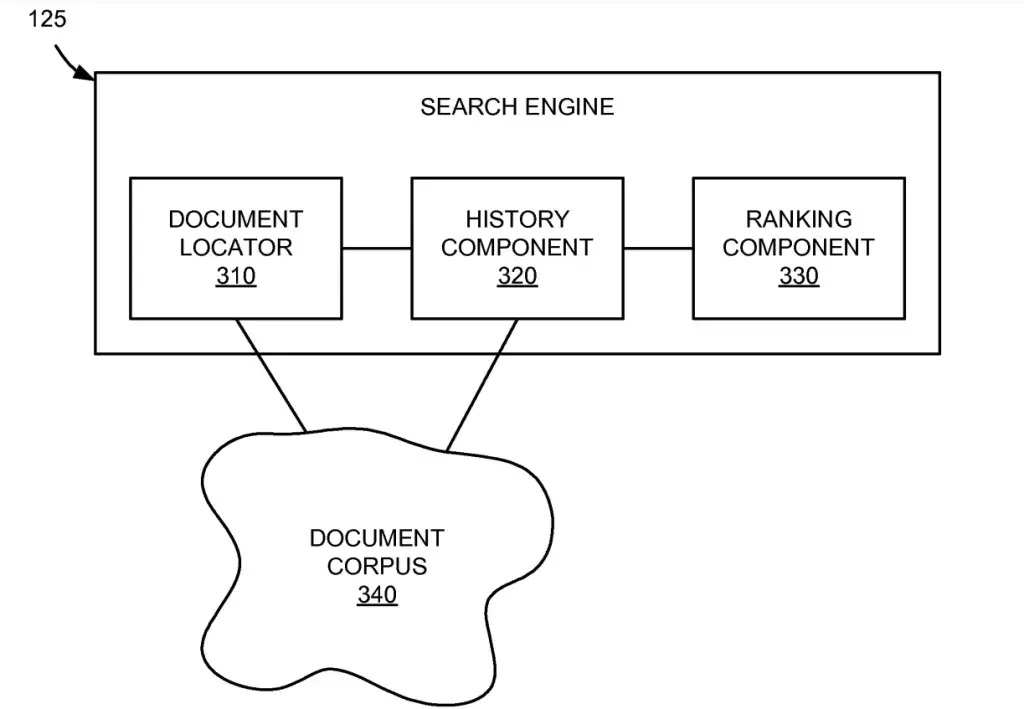
The document locator component that locates documents from a document corpus stored in database by comparing the terms in the user’s search query to the documents in the corpus. Simply put, the document locator is the component that identifies the set of documents whose contents match a user search query.
It locates and add references to documents related to a query or input document.
The document locator is mostly used to return the initial set of search results for a given search query.
Why is the Document Locator Important in Google Search?
The document locator is a major component of Google’s Search Engine.
It is the component that takes care of information retrieval. When given a search query, it returns the documents relevant to the search query.
It can also be used to enhance documents, such as described in the patent.
How the Document Locator Works?
It locates documents from a document corpus (index) by comparing the terms in the user’s search query to the documents in the corpus.
It is the first component involved in the information retrieval.
It is composed of:
- Descriptive Information Generator
- Search Component
- Formatting Component
The descriptive information generator receives personal information and current input document data. With that information, it builds a search query (e.g. descriptive information) to be sent to the search component. The search component receives the search query from the descriptive information generator. The search engine locates documents relevant to the search query. The ranking component ranks the documents based on their match score.
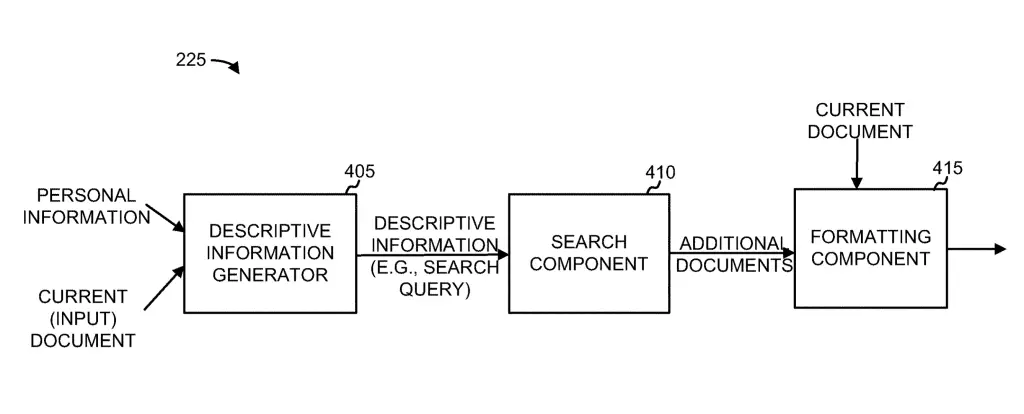
Descriptive Information Generator
The descriptive information generator is the component that generates descriptive information describing the current document, based on personal information of the user and information relating the input document.
What is Descriptive Information?
The descriptive information is a mix of information coming from the document and information coming from the user.
Document Descriptive information
- All terms appearing more than X number of times
- Automatically Extracted Named entities
- Dates in the document
- Author
- Publication name
- Keyword or category extraction
User Descriptive information
- Geographical location of the user (e.g. IP address)
- Personal Information derived from previous search queries or links selected
- Personal information provided when registering to an account
- Browsing history
- Documents generated by the user
- Current date or season
How is Descriptive Information Gathered?
Important Terms
Important terms may be derived from:
- the most frequently occurring terms
- terms considered descriptive for the document
- term frequency in the document vs all documents (poss. TF-IDF)
Named Entities
The descriptive information generator may store name entities from documents.
It matches a parsed document to a list of predetermined named entities or nouns:
- location names
- celebrity names
- product names
- company names
- etc.
The predetermined named entities may have been gathered manually, or by automatic techniques.
Date, Author and Publication Name
To store the dates, the author name and the publication name in the descriptive information, simple pattern matching may be used (e.g. Regular Expressions).
Personal Information derived from previous search queries
User search queries can be useful in search.
Google may proceed to category mapping in order to discover user’s interests.
For example, the concept of DataFrames exist in both Python and R programming.
If a user searches often for queries related to “Python Programming” (category), Google may serve documents regarding Pandas DataFrames (Python) for an ambiguous query such as “How to create a DataFrame”.
The mapping is done by looking at a lot of historical search sessions.
If users often search for two terms in multiple queries, but in a same session, then it is likely that they are related.
Example: A lot of users that searched for “python dataframes”, end up searching for “python pandas” in a same session (e.g. before closing the browser).
Thus, “dataframe” and “pandas” are two closely related terms for the “Python” category.
If a user that have search often for Python programming related queries, and then searches for “how to create a DataFrame”, Google may understand that the user searches for a “Pandas DataFrame”
How is the Descriptive Information Formatted?
The Document Locator will send the descriptive information to the search engine as a search query.
But instead of simply sending the search query, it may concatenate the search query along with the descriptive information.
[the] descriptive information generator may generate the descriptive information “Mt. Everest,” “Novolog Peaks and Poles Challenge,” “diabetes,” “San Jose,” and “photography.”
These terms may be combined into a single search query
“Mt. Everest Novolog Peaks Poles Challenge diabetes San Jose photography.”
That being said, the way they do it is not important, what is important is that they send this information along with the query. Additional information is described in the patent.
How the Search Component Works
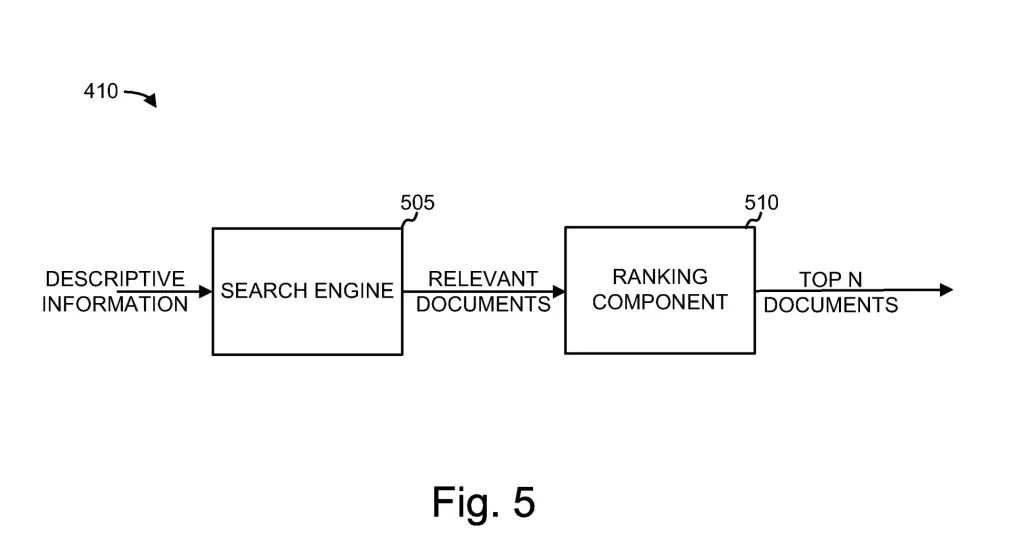
Google’s search component is the component that contains the search engine and the ranking component.
You will soon realize that there is two search engines here:
Search Engine > Document Locator > Search Component > Search Engine
This happens a lot in Google patents. It may be the same search engine searching different document corpuses, or different search engines (e.g. query-based vs general search engines).
How the Search Engine Works
Google’s Search Engine, found within Google’s search component, is the engine hat locate documents relevant to a search query.
The search engine receives the descriptive information from the descriptive information generator in the form of a search query.
The search engine then locates one or more documents relevant to the search query (e.g. descriptive information). It then returns the sorted documents to the ranking component.
The search engine may be a general search engine (i.e. Google Search) or a specialized search engine (i.e. Google News).
For more information, read the blog post on how search engines work.
How the Ranking Component Works
Google’s ranking component, found within Google’s search component, is the component that ranks and/or prune the set of documents returned by the search engine.
It sorts the documents based on various scores and then a subset of the top-ranked documents may be selected to be presented to the user.
Example of scores used by the ranking component
- Query-match score
- Link-based score
- Topical score
- Recency / Freshness score
- User Engagement Score (e.g. number of clicks) inferred from user behaviour data
- etc.
On top of these examples, for some queries, commercial sites may be explicitly excluded (or included).
Combining Multiple Queries
The ranking engine may combine multiple search queries and use the queries that return the best results.
How the Document Locator Enhance Documents
The document is mostly used to get the initial set of search results for a given query.
This is how it is used in “Document scoring based on query analysis”.
However, it can also be used to enhance individual documents from the search results.
This is the process described in “Enhanced document browsing with automatically generated links to relevant information”.
The formatting component is probably more related to the enhancing part, and less related to the initial ranking part.
Formatting Component
Google’s Formatting Component may insert additional documents into a document being viewed by the user.
It may insert links and/or float-over text on the page.
The example given is adding links from documents ranked for a search query into documents for which the document clicked on (e.g. adding wikipedia link to Mt. Everest on an article that didn’t link to it).

I never actually saw that anywhere online, but I did see something similar with featured snippets.
Example of what the Formatting Component May Do
Here is an example of a Wikipedia link being added to a featured snippet, even though the link is not actually in the actual page. Possibly returned by the formatting component.
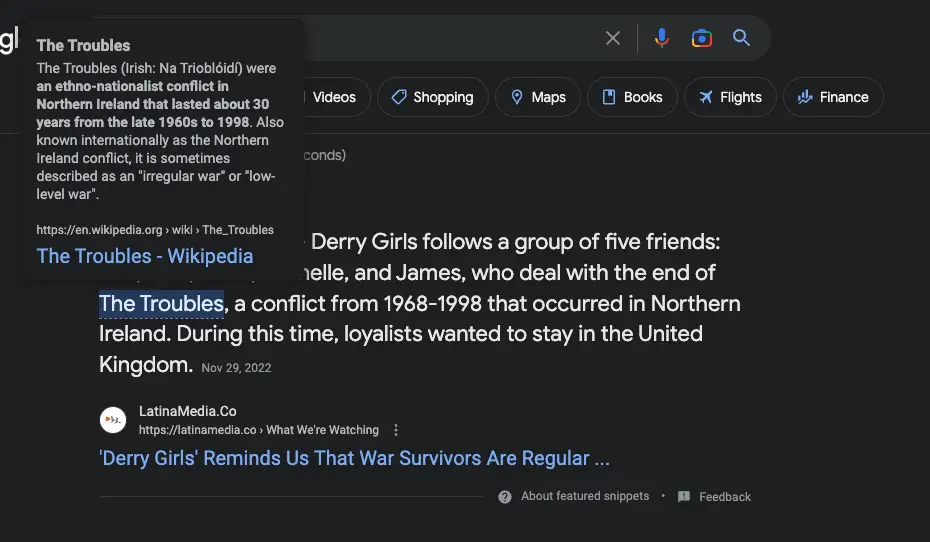
Process of Enhancing Documents
Here is an example of the process used to enhance individual documents with search results.
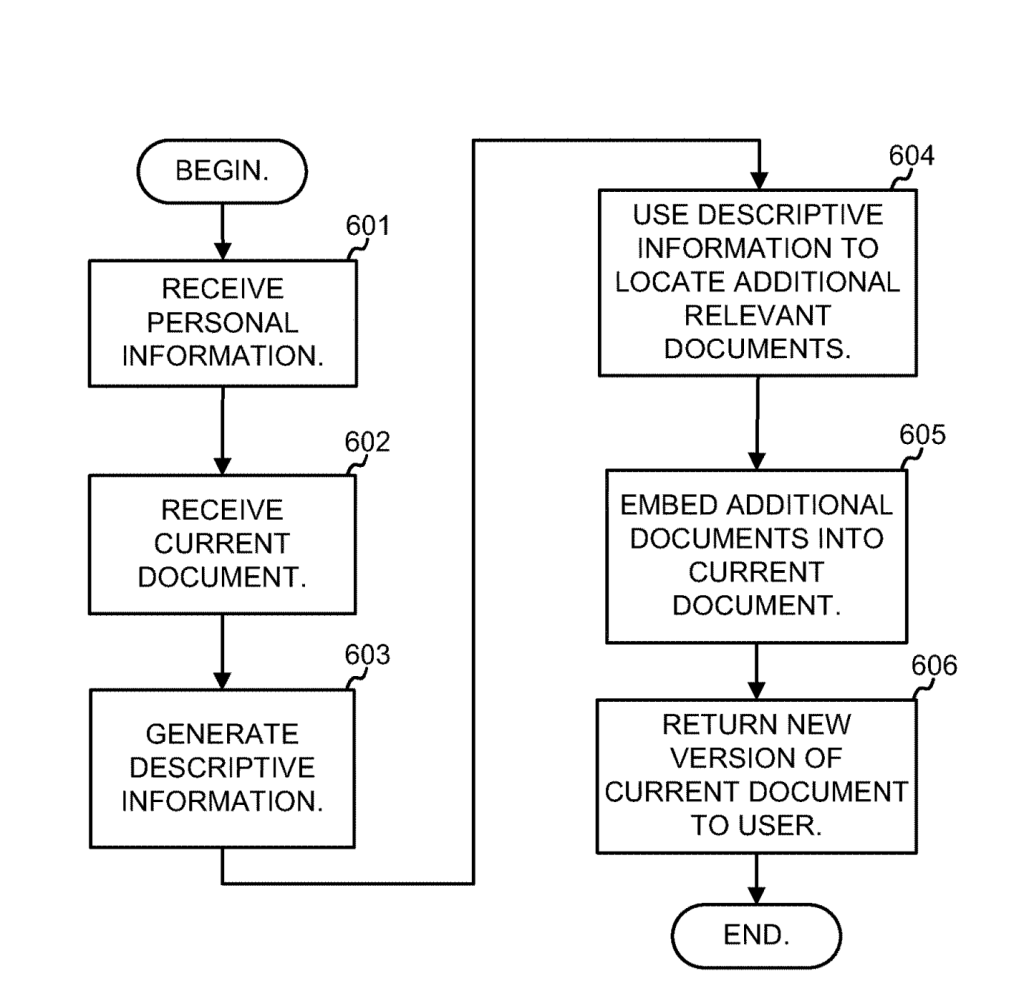
Which Patents Mentions the Document Locator?
- Document scoring based on query analysis
- Enhanced document browsing with automatically generated links to relevant information
- Named URL entry
- Ranking search results by reranking the results based on local inter-connectivity
- Methods and systems for improving a search ranking using related queries
Other Possible Names for the Document Locator?
Another name to the document locator found in various patents is the “additional document locator”.
Google Parent Infrastructure Involved
Where does the Document Locator falls into?
- Search System
- Search Engine
- Document Locator
- Search Engine
Google Children Infrastructure Involved
Google’s Document Locator can include these softwares:
- Descriptive Information Generator
- Search Component
- Search Engine
- Ranking Engine
- Formatting Component
The Document Locator is often used in conjunction with the history component and the ranking component.
Definitions
| Patent term | Definition |
|---|---|
| Document locator | Component that identifies the set of documents whose contents match a user search query. |
| Descriptive Information Generator | Component that generates descriptive information describing the current document |
| Descriptive information | Information relating a document and the user data (E.g. search query |
| Search Component | Component that contains the search engine and the ranking engine |
| Search Engine | Software that sorts information from documents stored in an index and presents the most relevant search results to the user query. |
| Ranking Engine | Engine that ranks and/or prune the sets of documents returned by the search engine |
| Search Query | Data submitted by the user, and possibly expanded with additional data, to a search engine in order to satisfy an information need. |
| Formatting Component | Component used to enhance a document using data from search results |
Document Locator FAQ
Where is the Document Locator Used?
Within the search engine
What does the document locator do at Google?
It returns a set of initial search results for a query and possibly enhance individual documents with data from the results.
Why is the document locator important for SEO?
It is the component that contains the search engine and ranking engine in order to return the initial set of ranked documents for a search query.
How often is the document locator mentioned in Google Patents?
The document locator is mentioned in a fair number of patents written by some highly relevant Google search engineers.
How likely is the document locator used in search?
Based on the number of patents, the contributors to these patents, the number of mentions and how long it has been mentioned, it is very likely that the document locator is used in search.
Conclusion
We have seen how the document locator is used in Google’s search engine to in order to locate relevant documents related to a search query.
Sources
- [1] Document scoring based on query analysis
- [2] Enhanced document browsing with automatically generated links to relevant information
- [3] Named URL entry

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.