In this post, I will explain the learning from the Google patent titled “Document scoring based on query analysis” by Jeffrey Dean, Paul Haahr, Monika Henzinger, Steve Lawrence and Al.
This is a very important patent to understand ranking and SEO.
This patent discusses various techniques that can be used to detect spam, evaluate content freshness and influence scores associated with a document.
Navigation
Show
Highlights of the Patent
This patents shows that Google may alter the ranks based on:
- The staleness of documents
- Spam signals such as discordant queries that signal overly broad pages
- Trends in search queries and document topics
- Frequency of selection
- Speed of ranking growth
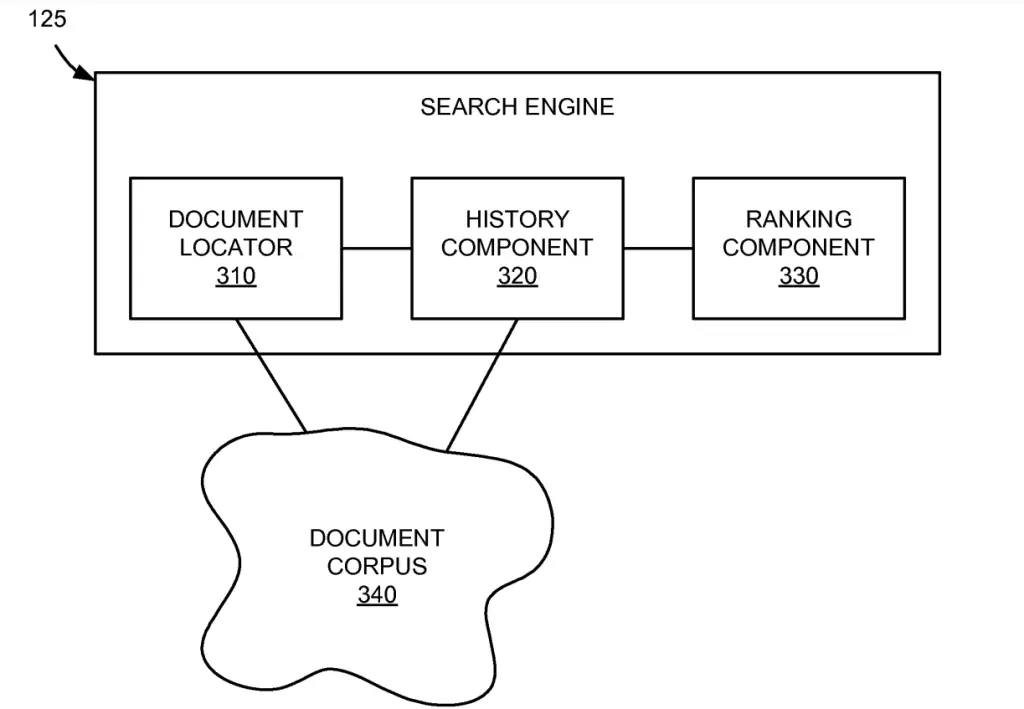
Components of the Search Engine
The components of the search engine discussed in this patent are the:
- Document Locator
- History Component
- Ranking Component
The document locator and the ranking component are only discussed in surface, the core of the patent is related to the history component.
Document Locator
The document locator is the component of the search engine that takes care of the information retrieval.
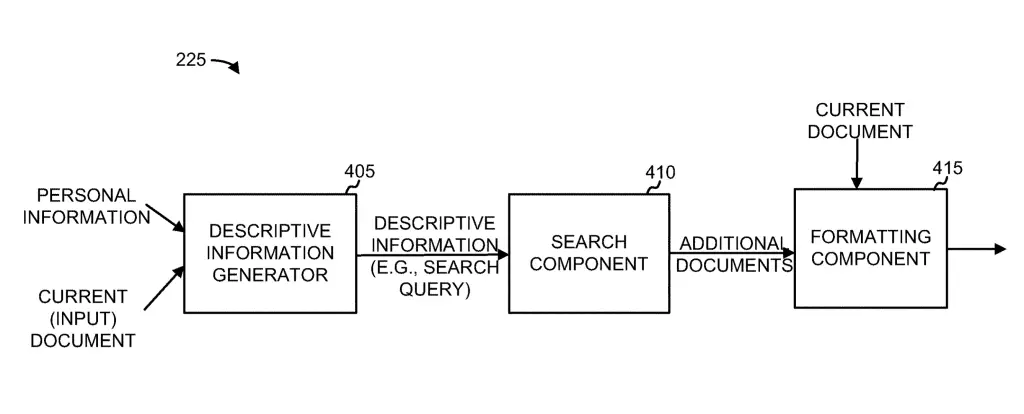
It identifies the set of documents whose contents match a user search query.
It locates and add references to documents related to a query or input document.
The document locator is mostly used to return the initial set of search results for a given search query.
The Document Locator is discussed in depth in the Google patent titled:
Enhanced document browsing with automatically generated links to relevant information
I have covered in depth what this patent is about in the patent related to the document locator.
History Component
The history component is a technology patented by Google LLC that is used as part of the Google Search Engine to gather history data for a given document in a document corpus.
Based on this history data, the history returns history scores for the documents to be used in ranking by the ranking component.
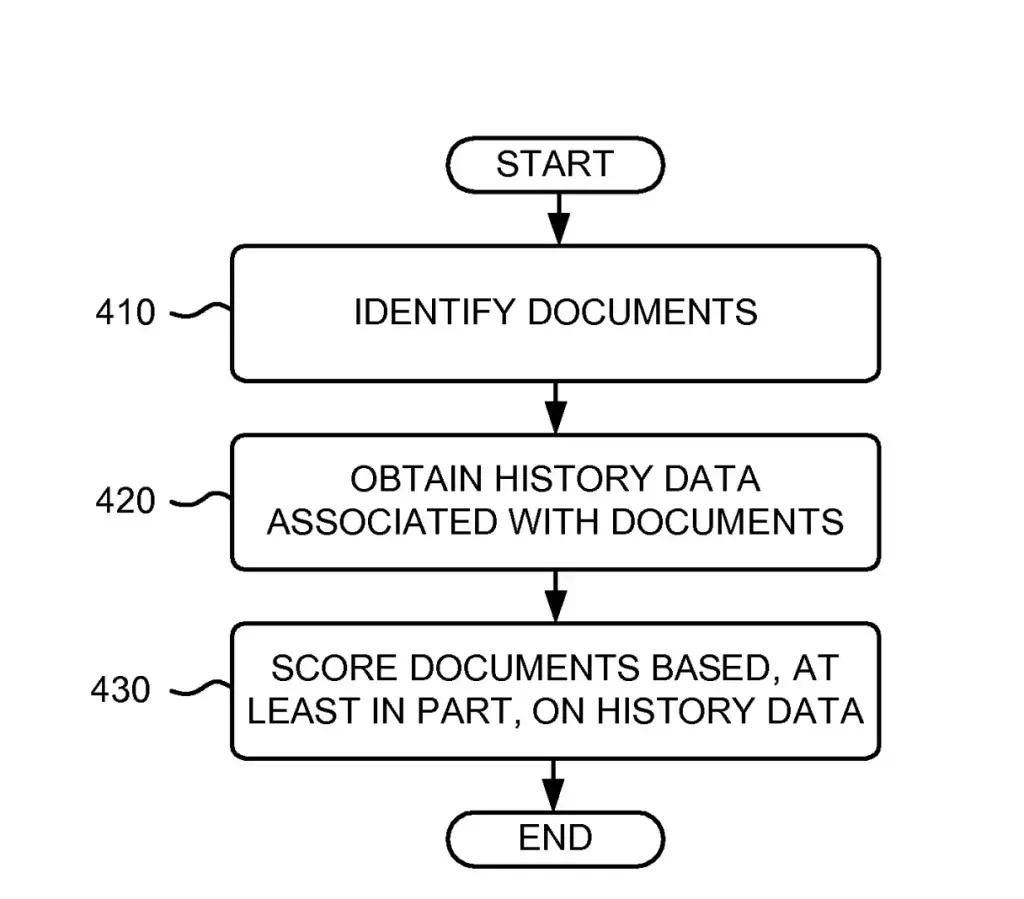
I have covered in depth what this patent is about in the patent related to the history component.
Ranking Component
The ranking component is Google’s piece of software that assigns ranking scores to document(s) before, related to, or independent of the search query.
The ranking component returns relevant documents to the user by ranking the set of documents identified by the document locator.
I have covered in depth what this patent is about in the patent related to the ranking engine.
Document Corpus
The Document Corpus in Google is the corpus that include information associated with documents that were previously crawled, indexed and stored.
Essentially, the document corpus is Google’s index database.
Patent Details
| Name | Document scoring based on Query Analysis |
| Assignee | Google LLC |
| Filed | Apr. 24, 2012 |
| Status | Active |
| Expiration | 2023-12-31 |
| Application | 13/454,424 |
| Inventor | Jeffrey Dean, Paul Haahr, Monika Henzinger, Steve Lawrence and Al. |
| Patent | US8639690B2 |
Related Patents
Comparing these under text comparison, there are some slight differences between patents, but nothing too big as to warrant reading each one.
There is, however, a difference between 6 and 7, in which the same technology seems to be used to improve Google Search, but also used by Google Ad Network to score advertisers.
- Information retrieval based on historical data
- Document scoring based on link-based criteria
- Document scoring based on document inception date
- Document scoring based on document content update
- Document ranking based on document classification
- Document scoring based on query analysis (Google Search)
- Document scoring based on traffic associated with a document (Google Ads)
What Categories is the Patent About?
- Content-Decay
- Freshness
- Ranking
Conclusion
We now have learn a lot about Google search engine by reading this patent.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.