In this post, I will explain how Google uses history data to rank documents in search.
The learnings come from the patent titled “Document scoring based on query analysis” by Jeffrey Dean, Paul Haahr, Monika Henzinger, Steve Lawrence and Al.
I don’t know if you know engineer above-mentioned, but this is a very important patent to understand ranking and SEO.
This patent discusses various techniques that can be used to detect spam, evaluate content freshness and influence scores associated with a document.
Navigation
Show
Why is History data Important in Search?
It is likely that the history component provides data used for ranking search results.
the [ranking] score is based, at least in part, on the history data from history component
“Document scoring based on query analysis” by Jeffrey Dean and Al.
Highlights of the Patent
- Most ranking factors are evaluated as trends, not absolutes. Google tries to see upwards or downwards trends as well as spikes in order to draw conclusions.
- Multiple ranking factors are exposed in the patent along with examples (e.g. freshness of content and links, …)
- Multiple ways to fight spam are exposed (spikes in link growth, tokens in anchor texts, …)
- Multiple examples of how Google evaluates the freshness of content
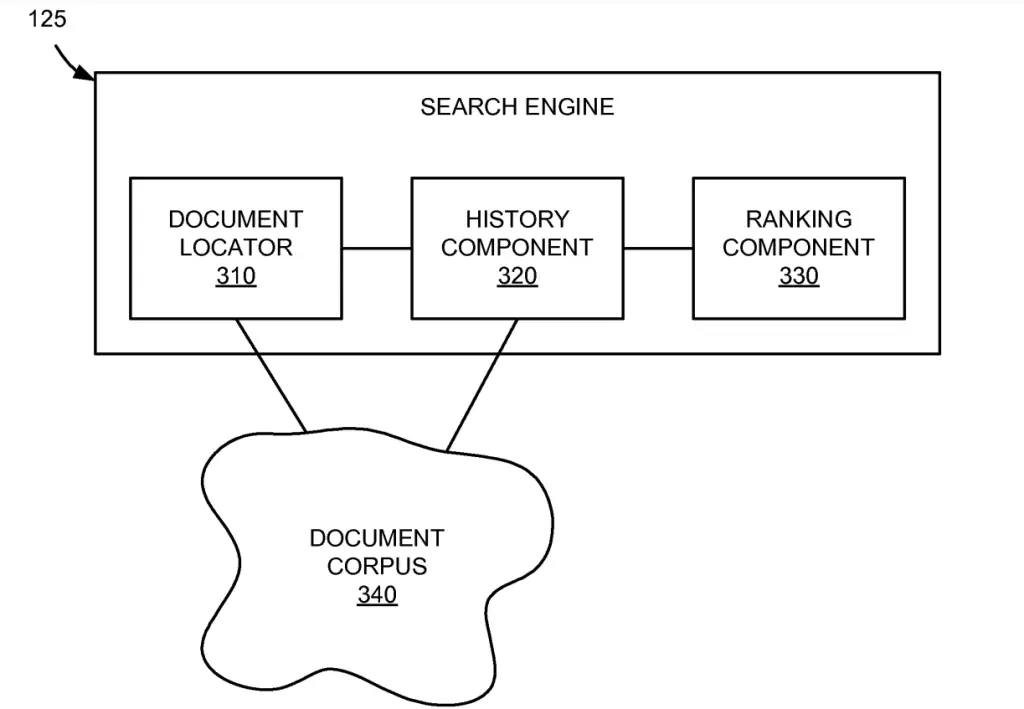
High-Level Overview of the History Component in Search
Ranking in Google Search is done within the search system by the Ranking Component of the Search Engine.
Ranking is done prior to, independent of, or in connection with the search query.
The ranking scores that are generated are based in part on the history scores generated by the history component.
The document locator is the component that does the information retrieval (identifying documents whose contents match a search query).
The document corpus is essentially Google’s index database.
What is the History Component?
The history component is a technology patented by Google LLC that is used as part of the Google Search Engine to gather history data for a given document in a document corpus.
How the History Component Works?
The history component gathers history data associated with documents in a corpus (index) and returns history scores for the documents.
What History Data is Tracked at Google?
For most of the ranking factors mentioned hereafter, Google tries to identify trends that help to spot big changes, spam or outdated content.
TL; DR
The history data that is tracked is:
- Inception dates
- Content updates and changes
- Query Analysis
- Link-based criteria
- Anchor text
- Traffic
- User-Behavior
- Domain Related Information
- Ranking history
- User maintained/generated data (bookmarks)
- Unique Words, Bigrams and Phrases in Anchor Text
- Linkage of independent peers
- Document topics
Document Inception Date
The inception date is when a document was created.
Search Engines may used the inception date to score a documents.
The inception date can be used to show alter scores of documents for fresh seeking queries and evaluate link growth instead of relying on the absolute number of links
TL;DR
The importance of the inception date may be smaller or larger depending on the query.
How it may be used in Ranking
An old document would generally outrank a new one because of the number of links.
Using the inception date can be used to calculate the link growth instead. Thus helping to re-adjust the ranks.
A page created yesterday with 10 links can have an higher link growth than a page built 10 years ago with 100 links, thus making it suitable for higher ranks.
That being said, Google has other methods to fight link spam and a great growth may be flagged as spammy.
UPDATE: After GoogleAPI content warehouse Leak in Mai 2024, one document has a LINK_SPAM_PHRASE_SPIKE tag that hints that this spam fighting might still be used in search.
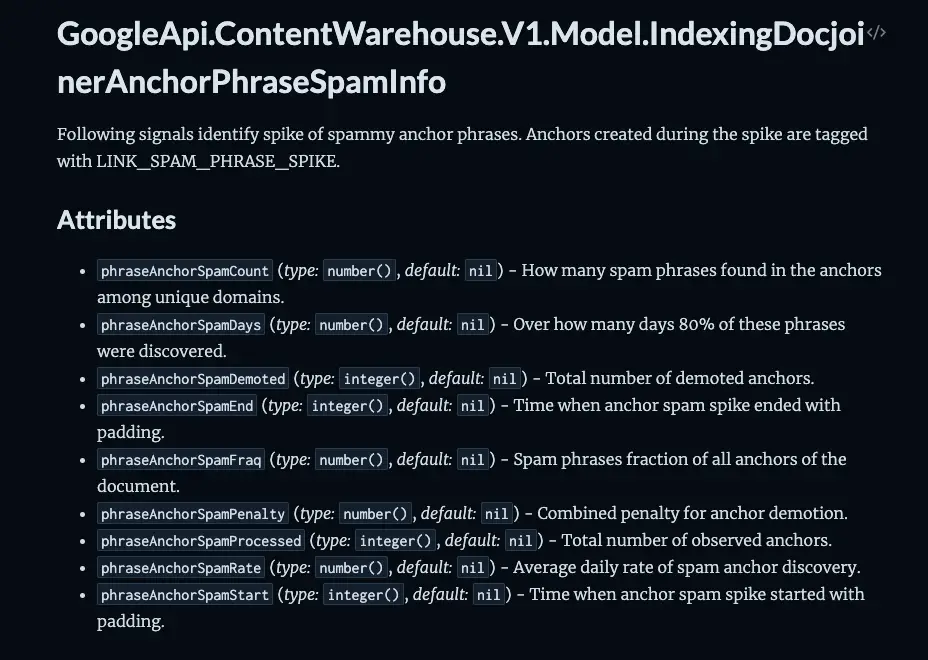
They can also try to find if the inception date is an important factor by comparing the inception date with the inception date of all documents related to the query.
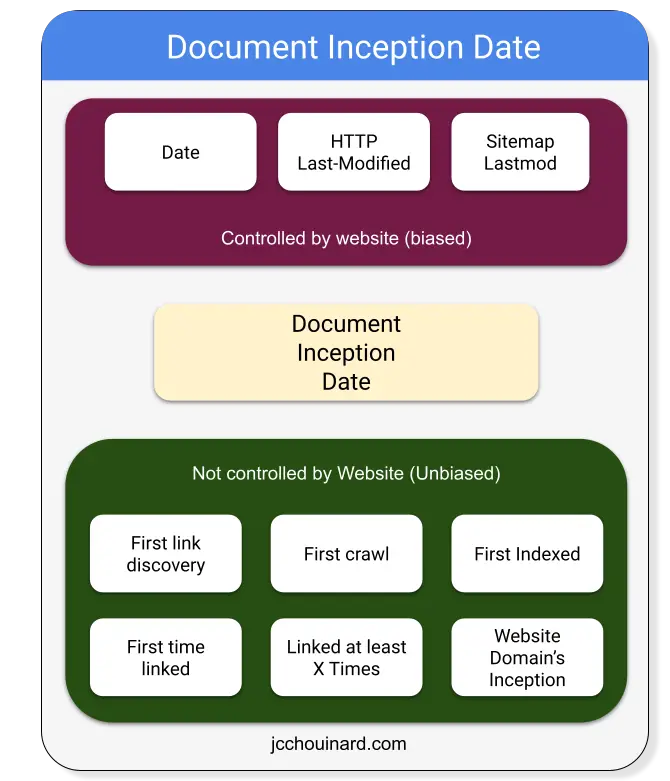
How Google Knows the Inception Date?
The inception date can be inferred from things like:
- Date shown on a document
- Timestamp of document sent by the server (Last-modified HTTP header)
- Lastmod tag in Sitemap
- etc.
This metric is biased as many websites may try to influence the score associated with their documents.
Thus, Google uses many techniques to identify a document’s inception date.
- Date the search engine first discovered a link to the document
- Date the search engine first crawled a document
- Date the search engine first of indexed the document
- Date of the website’s domain
- First time that a document is referenced in another document, such as a news article, newsgroup, mailing list, …
- When at least X pages linked to the document
Modifying Link Score Based on Inception Date
The history-adjusted link score formula goes something like this:
H = L / log(F+2)Where :
- H: History Adjusted Link-Score
- L: Initial Link-Score (with techniques similar to what is mentioned in these patent, patent, patent)
- F: Elapsed time from inception date
Varying Importance of Inception Date
The importance of the inception date may vary depending on the query.
Sports scores, covid cases, news all are seeking for “new” content.
In opposition, research papers don’t require as much the freshness attribute.
Thus, if the query has a fresh-seeking intent, the inception date has more impact.
To account for that, Google may compare the age of a document with the average age of all documents and modify the score accordingly.
Content Updates and Changes
How a document changes over time mat be used to change ranking scores.
Often edited content may score higher than content that stays static over time.
Often updated content gets better scoring. Not all changes are equal. The scores are based on the update frequency and how much of the content gets updated
TL;DR
How it may be used in Ranking
Google may try to find out if content are being updated more frequently or less frequently than they were in the past.
They can also try to find if this is an important factor by comparing the date of change with the average date of change of all documents related to the query.
Modifying Content Update Score
The Content Update Score formula goes something like this:
U = f(UF, UA)Where :
- U: Content Update Score
- UF: Update Frequency Score
- UA: Update Amount Score
Update frequency score
- Average time between updates
- Number of updates in a given time period
- …
Update amount score
- Number of new pages associated with a document over a period of time
- Ratio of the number of new (or unique) pages associated with the document over a period of time VS total number of pages associated with the document
- Amount that the document is updated over certain periods of time (e.g. % of document that has changed in the past year)
- Amount that the document has changed in a period of time.
Weighing Different Portions Differently
Some changes to a page have more value than others.
Low Weight:
- JavaScript
- Comments
- Advertisements
- Navigational Elements
- Boilerplate material
- Date and time tags
Higher Weights:
- Title
- Anchor text associated with forward links
Trends May Be Drawn
Rather than utilizing absolute values, such as the number of new links to a page, Google may try to identify downward or upward trends.
By comparing the % of update in the past year, versus the % of update of the previous year, Google may discover a deceleration or acceleration to the update rate of a piece of content.
Documents with an increased rate of change may be score higher.
Saving Bandwidth
If Google does not have the resources to store documents when monitoring for changes, it may store “signatures”.
May store a term vector and monitor for relatively large changes. They may only store certain terms that are deemed important (e.g. main keyword in the Title) and only check for changes to these words.
They may decide to only compare hashes for near-duplication detection.
Query Analysis
Query-based factors may influence the score of a document.
When topics become trending, it may influence temporarily rankings.
Search queries and user-behaviour with search results are used to check changes in search intent, trending topics, outdated content and spam. Documents that adapt with change of intent and trending terms will be scored better, even more if people start clicking on this document more than higher ranked outdated documents.
TL; DR
Interpreting Changes from Search Queries/Results
Web search changes according to real-world events.
In 2007, Rhianna released “umbrella” and the Red Sox won the world series.
These changes had to be reflected in search. Otherwise, Google may still have shown the Amazon umbrella product page and results about how Babe Ruth called his shot in the 1932 world series.
How it may be used in Ranking
Google looks at search queries and search results to identify changes and adapt rankings according to those changes.
More clicks on it
How much document is selected when it is included, over time. When suddenly, users start clicking on the second result instead of the first, that may signify a change in intent.
More people search for it
Increase of search terms appearing in queries over time signify that a topic is trending.
Documents targeting these “hot” terms may see temporary or permanent ranking improvements.
More people talk about it
Increase of documents appearing in search result for a set of similar queries may indicate that a query is trending.
The search engine may increase the scores of documents related to those queries.
Equal number of searches but very different results
Some topic are always trending, such as major sports events.
The Super Bowl is always popular, but websites stop talking about last year’s teams and all talk about this year’s.
Thus, results talking about last year’s teams lower their rankings and the ones about this year’s increase their rankings.
Google can know about these changes when:
- The number of searches stays relatively constant over time.
- The number of documents also stays relatively constant.
- The topics in the documents related to the query change.
Staleness of documents
Here, Google tries to identify which documents are stale and which are not.
Some queries may require fresher documents (fresh seeking), other more stale documents.
This is a concept that is discussed when we talk about queries deserve freshness (QDF) or in Freshness Based Ranking.
If the stale document is preferred, the score is increased, if the fresh document is preferred, the score is decreased.
The weight of this ranking factor can change depending on how often users select a lower/higher ranked stale document vs a higher/lower ranked fresh document.
Staleness of documents can be inferred from:
- Document creation date
- Anchor growth
- Traffic
- Content change
- Forward/Back links growth
- User selections
How often users select a more recent document that is ranked lower than an older document in the search results.
How often a document is included with topical queries (world series champions) vs specific queries (Boston Red Sox). This change in inclusion may infer that a document is becoming more stale.
Nothing explains this better than how the patent exactly says it:
Search engine may learn which queries recent changes are most important for by analyzing which documents in search results are selected by users.
More specifically, search engine may consider how often users favor a more recent document that is ranked lower than an older document in the search results.
Additionally, if over time a particular document is included in mostly topical queries (e.g., “World Series Champions”) versus more specific queries (e.g., “New York Yankees”), then this query-based factor—by itself or with others mentioned herein—may be used to lower a score for a document that appears to be stale.
Discordant Queries
If a document ranks for various unrelated queries, the document may be considered spam and the score may be reduced.
Link-Based Criteria
Google tries to find when links were added and removed, the rate of link change, the number of added and removed links and the trend of increase or decrease in link growth.
Google search engine may modify the score of a document as a function of the sum of the weight of the links pointing to it.
Other Link-Based freshness evaluation metrics are described in the patent named “Systems and methods for determining document freshness”.
New Links VS Disappearing Links
Google finds the dates relevant to a link: when it was created, when it was removed.
These dates are determined during crawling or during index updating.
The date of a new link can be the date that:
- a search engine finds the link;
- date of the document that contains the link or the date it was updated
The date of a lost link is the date that either the link was removed or the document with the link was removed.
New Links VS All Links
- Number of new links in X last days VS Number of links since inception date;
- Oldest age of the most recent y% of links compared to the age of the first link found;
new_vs_all = links_last_10_days / total_links
Link Freshness
The weight of a link may vary according to its freshness.
The freshness of a link may be influenced by:
- Date of the update of the link
- Date of the update of the anchor text
- Date of the update of the document containing the link
Google may update link freshness only when major changes to a document occur (e.g. large portion of document or update to many portions of the document).
Link Growth Rate
Link growth may signal freshness, and possibly better rankings. Link decrease may signal staleness.
Google compares the number or rate of new links in a recent period and compares to an older period.
A downward trend may signal that a document is becoming stale.
Link Trust
Links may be weighted based on how trusted the documents containing the links are (e.g. Governmental documents vs Nutrition blog).
Link Authoritativeness
If you have heard about E-E-A-T in SEO, this is the “A”, for authoritativeness.
How authoritative a page is influences the weight of the links that it contains.
Authoritativeness is discussed in this patent and this paper.
Age Distribution of Links
The age distribution is composed of the dates of links pointing to a document. The age distribution of new documents is very different from that of stale documents.
Ranks may be altered based on the age distribution.
Dynamic-ness of Links
When given two similar pages, update similarly and with similar link authority and page quality, Google may evaluate links differently based on how dynamic they are.
a good link may go unchanged when a document gets updated
If page A has links that change every day, and page B always has the same links even when the page is updated, links from both pages will be weighed differently.
Pages that change every day (e.g. featured links) will be scored lower than links that persist.
Link Decay
Links from a page that never gets updated will loose some value with time.
This is called link decay.
Link Spam Detection Using Dates
Link spam may be detected looking at the dates of links created. Links created at a very high speed either signal a real-world trending topic (which is OK), or link-spam (which is not).
Examples of link spam listed in the patent:
- Buying links
- Exchanging links
- Non editorial links: guest posts, referrer logs (pingback links), page where anyone can add a link
Lost Links
Looking at trends to the rate of which a web page looses backlinks, Google can discover how stale the document is and modify rankings accordingly.
Anchor Text
Changes in anchor texts of links over time may be used to alter the scores of the linked documents.
They estimate the date when
- the page changed focus
- the anchor texts change significantly
All links prior that date may be ignored.
Update in Anchor Texts
Changes to anchor texts may indicate that a document may have been updated.
Update in Documents that Differs From Anchors
If the content of a document (e.g. Web Page) changes in a way that is very different from the anchor texts, Google may assume that the purpose of the content changed.
Google tries to spot attempts of influencing rankings through expired domains acquisition.
They want to make sure that, if the topic of the page has changed, then the page is not ranking for the outdated anchor texts queries.
Freshness of Anchors
According to the patent, a good link is a link that stays the same if it is still relevant even when the document is updated.
To score documents associated with the anchors, the freshness of anchors is evaluated.
The freshness of an anchor can be determined using the date of appearance/update of the:
- Anchor text;
- Link associated with the anchor text;
- Document where the link is found;
- Document where the link points to.
Traffic
Google tracks traffic to a document over time and try to draw trends that can be used in its ranking.
Large reduction may indicate staleness of the document.
Latest Traffic VS Highest Traffic
Google may compare the traffic from the last X days to the average traffic where the document received the most traffic, adjusted to seasonal changes.
This way they can identify periods where the page is more, or less, popular (e.g. Christmas).
Knowing these repeating peak and slumps patterns, they may adapt document scoring during and outside the peak periods.
Using Ads
Google may “look” at traffic to advertisements present on a web page and may use this data to score documents.
- Rate at which ads are presented by a document over time
- Quality of advertisers (e.g. linking to Amazon VS Porn)
- CTR of ads
User Behaviour
Individual or aggregate user behaviour may be used to alter the score associated with a document.
Examples of user behaviour data that can be used:
- Number of times a document is selected from a set of search results
- Amount of time one or more users spend accessing the document (e.g. long click)
Time Spent on Page over Time
If for a given set of queries, on average, users spend less time on given a document than they used to, it may be an indicator that a document is stale.
A fresher document would show an increase in the average time users spend on page.
Domain Related Information
In order to score a document, Google looks at the domain’s quality (e.g. how it is hosted).
Google is trying to detect spammers that use doorway domains to gather as much traffic as possible in the shortest possible time.
How Google identifies illegitimate domains?
- Date when the domain is set to expire: Illegitimate domains are short-lived (e.g. 1 year) vs legitimates are often purchased several years in advance (e.g. 10 years).
- Validity of DNS record: Is the address valid, how often the contact information changes, high change rate in names servers and hosting companies, etc. Google keeps a track of known bad contact information, name servers and IP addresses.
- Quality of the name severs: Legitimate name servers would generally host domains from different registrars. Bad names servers could host only a single type of spammy content (e.g. porn related, doorway domains, domains with commercial words, bulk domains from a single registrar). The age of the name servers may also be used to detect brand new registrars.
Ranking History
Prior rankings of a document may be used to modify the score associated with it.
History of Positions
The rate at which a document moves in rankings for multiple queries is either a topical document or an attempt to spam search engines.
Thus, that quantity of ranking changes may be used to influence future scores of the document.
It goes like this:
For a set of queries (e.g. commercial queries).
Documents that get more than X% increase in rankings are flagged.
Percent growth is used in determining scores of the document.
Commercial queries may be identified by the churn rate or by the fact that the top results change a lot from month to month.
For commercial queries, the likelihood of spam is higher and score are thus adjusted.
Number of Queries and Click Rate
Google keeps track of query and click data for web pages, hosts and domains.
If the number of queries and the click rate for which a document is selected within search results indicates the quality of the document.
So, for a URL/Query pair, scores are adjusted depending on:
- If the number of queries that lead to a click increases or decreases over time
- If the click-through rate increases or decreases over time
Search Results Scoring
Independently of your own content, Google may modify scores for a set of results for a given query.
Two queries may have different search results scores.
To score search results, Google may look a the aggregate CTR of all search results for a query in a given time period (source).
Search query scores are drawn from the average score among the top set of documents for the query.
Example things that may influence the search result scores for a given query:
- Number of searches
- Click data
- Number of documents in search results
So, looking a trends, Google may modify search results scores.
The best example of a changing query search result scores is with the Covid related queries.
In an incredibly short time, covid related queries went from the lowest query results score to one of the highest that ever was.
Pages related to that given set of queries may start to rank higher in the future.
Spikes in Ranks
Spike in rankings can be used to identify spam attempts and dealt with accordingly.
To prevent search spam, Google may introduce some limits to:
- Growth rate of rankings;
- Maximum growth threshold for a certain period of time;
Although not mentioned in the current patent, they may also introduce a rank transition function to make it harder for spammers to evaluate the impact of their techniques.
To differentiate spam from a topical phenomenon (hot topic), Google may look at mentions of the document in news articles, discussion groups, etc.
Spike in ranks without an increase in mentions is a signal of a spam attempt.
Note: Google may make exception for highly authoritative websites and assume that rank growth are not spammy in nature, thus not adding any rank growth limitations.
Drops in Ranks
Significant drops in ranks can indicate out-dated content.
Content that loses ranks over time may thus be scored lower in the future.
User Generated Data
Google may gather your Bookmarks and favourites from the Chromium browser.
These can be used and analyzed over time to influence the scores associated with documents.
By analyzing trends into how user add or remove pages from their bookmarks/favourite, search engines may score document higher or lower.
Unique Words, Bigrams and Phrases in Anchor Text
Google tries to identify spam by looking at the link graph.
Specifically, they look at the anchor text.
Spam may be discovered when the growth in anchor words/bigrams/phrases are spiky.
This is what they try to spot:
- Large number of identical anchors for many documents
- Deliberate different anchors from many documents
The anchors may be used to score the documents where their links points to.
How they may limit the impact of bad links:
- They may add a cap to suspect links
- They may use a continuous scale for the likelihood of link-spam and use it to score the document
Linkage of Independent Peers
Links is a known SEO ranking factor, how much so, we don’t exactly know.
Link-based ranking are the basis of the early Google’s success as they shown the “authority” of a web page.
As web developers and SEOs discovered they could influence their rank, they invested in link building tactics.
The “independent peers” thus becomes an important concept.
Whether it be for incoming or outgoing links, a sudden growth in links from unrelated document may be an indicator of a link-spam attempt (synthetic web graph).
Google also looks if anchors are very coherent or discordant to further evaluate the likelihood of link-spam (see the section named: Unique Words, Bigrams and Phrases in Anchor Text).
Google may demote suspect links by a fixed amount or by a multiplicative factor.
Document Topics
Google may perform topic extraction to score documents.
Topic Extraction Techniques
Topic extraction can be done via various techniques:
- Categorization
- URL analysis
- Content analysis
- Clustering
- Summarization
- Unique low frequency words
- etc.
Again, Google may look at how topics change over time for a given page.
Tracking Document Owners
Significant changes in topics may indicate that a document has changed owners.
If this is so, Google may consider all previous indicators such as document scores, links, anchor text.
Tracking Spam
Spike in the number of topics related to a page can indicate spam.
For example, let’s say that, after a period of stability in the documents topics, there is a sudden spike, or alternatively, the topics disappeared.
Google may treat this as an indicator that the document was taken over as a doorway page.
In such case, the scores related to the document may be reduced.
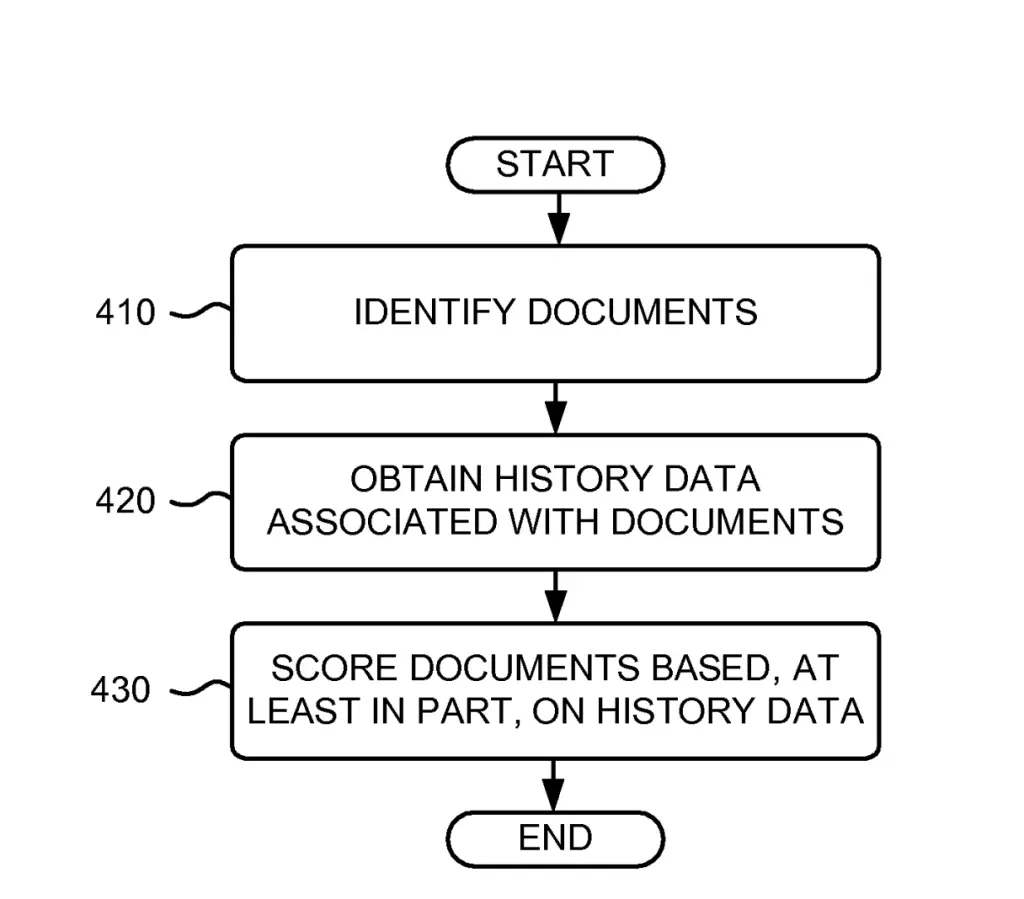
Processing of History Data
How the search engine integrate history data into ranking is quite simple.
They gather documents and then obtain the history data.
Then they get relevancy scores for documents and combine the relevancy scores to the history scores.
Alternatively, they may simply alter the relevancy scores without integrating history scores or simply use history scores.
Relevancy scores are discussed in “Determining a quality measure for a resource”.
Which Patents Mentions the History Component?
“Document scoring based on traffic associated with a document“
“Document scoring based on query analysis“
Google Parent Infrastructure Involved
Where does the Document Locator falls into?
- Search System
- Search Engine
- History Component
- Search Engine
The History component is often used in conjunction with the document Locator and the ranking component.
Definitions
| Patent term | Definition |
|---|---|
| History component | Component that used to gather history data for a given document in a document corpus |
| History data | Data relating to a document ranking’s criteria |
| History scores | Scores that can be used to alter or be combined with other scores when ranking documents |
| Churn rate | How often users stop clicking on a link to click on its alternative |
| Hysteresis | Lag or rate limit applied by Google to ranking changes to reduce spam attempts |
| Web Graph | Network of web pages connected to each other by hyperlinks |
| Synthetic web graph | Artificially influenced web graph (e.g. Private Blog Networks, Link exchange, etc) |
| Document corpus | Document available from the internet |
| Document Locator | Component that identifies the set of documents whose contents match a user search query. |
History Component FAQ
Where is the History Component Used?
In the Search Engine
What Factors influence History Scores
There are many factors that influence the history scores: Document inception dates; document content updates/changes; query analysis; link-based criteria; anchor text; traffic; user behavior; domain-related information; ranking history; user maintained/generated data (e.g., bookmarks); unique words, bigrams, and phrases in anchor text; linkage of independent peers; and/or document topics.
How is history data used in Ranking?
History data is used to evaluate the freshness of a document and to identify spam attempts. Depending on the cases, history data is used to score or alter scores of a document.
Patent Details
| Name | Document scoring based on Query Analysis |
| Assignee | Google LLC |
| Filed | Apr. 24, 2012 |
| Status | Active |
| Expiration | 2023-12-31 |
| Application | 13/454,424 |
| Inventor | Jeffrey Dean, Paul Haahr, Monika Henzinger, Steve Lawrence and Al. |
| Patent | US8639690B2 |
What Categories is the Patent About?
- Content-Decay
- Freshness
- Ranking
Conclusion
We now have learn a lot about Google search engine by reading this patent.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.