Google’s “Image retrieval” patent is about how the Google Image Search Engine manages duplicate images and how the collections of duplicate images are ranked when a user uses an image (query image) as a search query.

In this post, I will cover some of what I have learned on the Google Image Search Engine patent titled “Image Retrieval” by Henrik C. Stewenius.
Navigation
Show
Highlights From Image Retrieval
The “image retrieval” patent give a lot of insights into how duplicate images are handled. Here are some of the takeaways.
- Near-duplicate images are clustered into groups of near-duplicate images called collections.
- Google indexes collections of near-duplicate images instead of indexing each images individually.
- Google sorts collections of images, not individual images, speeding up the information retrieval time.
- Depending on the query Google picks different images from the collection of images.
- With no specific parameters in the query, Google may simply pick the largest, or higher quality image.
How Google Handles Duplicate Images
Handling duplicate images is done to improve both indexing and information retrieval.
Here is how duplicate images are handled in Google Images.
Google gathers images from the web along with image related text (caption, alt, anchors, …).
Google computes the similarity between images.
Google clusters near-duplicate images into groups, called collections.
Google assigns each image related text to the collection (aggregation).
Google indexes the group of images along with the aggregated related text instead of indexing each image individually.
Google creates posting lists (see definitions at the end) with each cluster of near-duplicate images.
Each posting list is assigned one visual word .
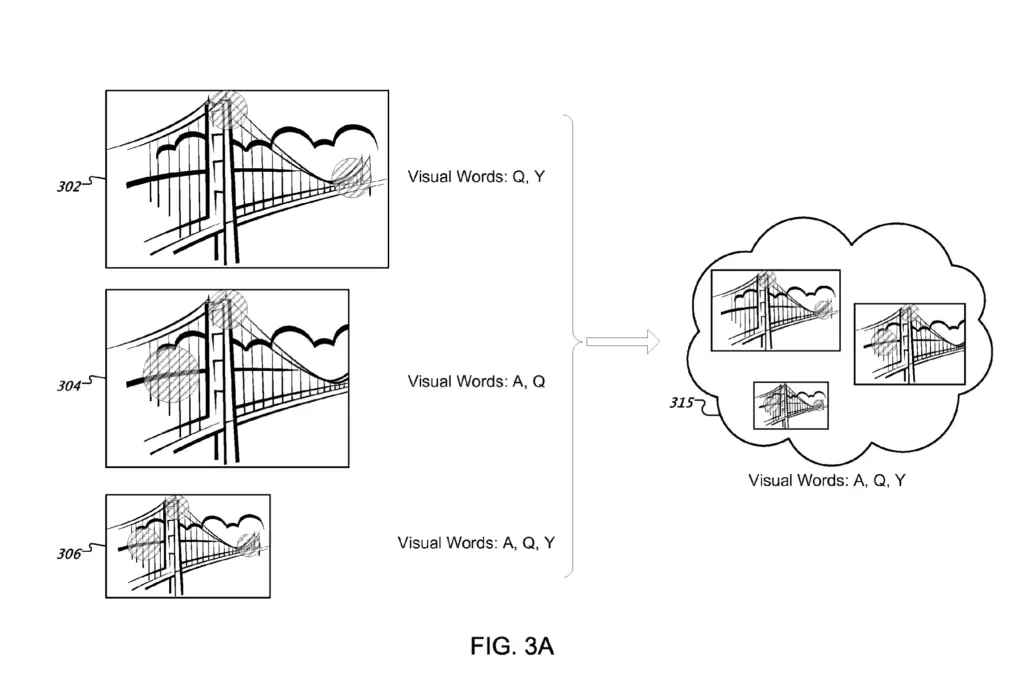
If a duplicate image cluster has too many aggregated visual words, the cluster can be split in smaller clusters where each image is assigned to a single cluster.
When the search query comes in, the collections of duplicated images are sorted by relevancy.
Based on the query, the most appropriate image from each collection of duplicated images is selected and shown to the user.
Images taken at different times by different cameras, with different compression, cropping, and scale can still be considered near-duplicate images. Even when text is added, or other minor alterations can images be bundled together as duplicates.
In Image retrieval, the collection of duplicate images is retrieved as a single unit.
Checking Image Similarity
Many patents discuss about how image similarity is calculated and they all say the same thing.
The image search system, specifically the image similarity module (not mentioned in this patent), compares images against each other to evaluate the degree of similarity between the images.
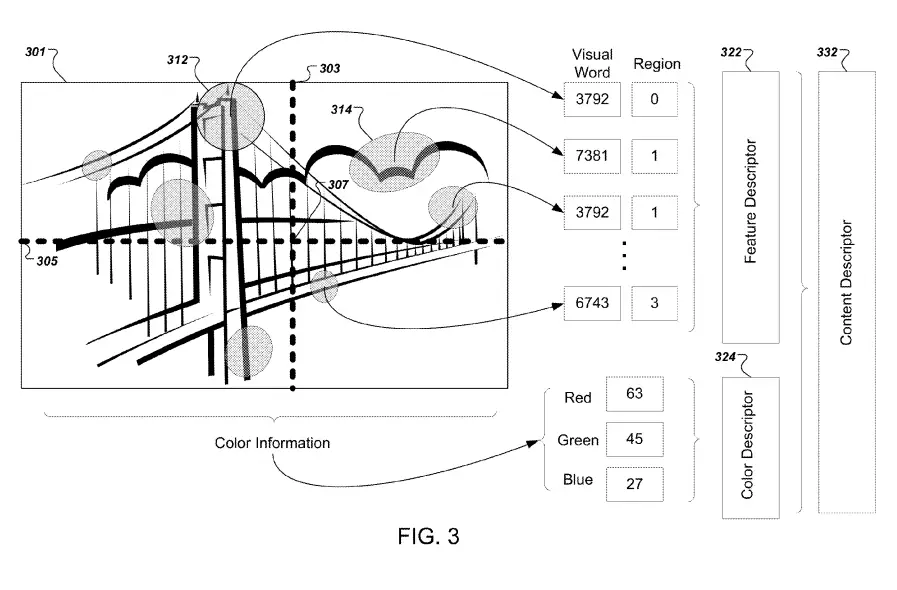
They way it works is that it defines feature regions using geometrical shapes (ellipses) like shown below.
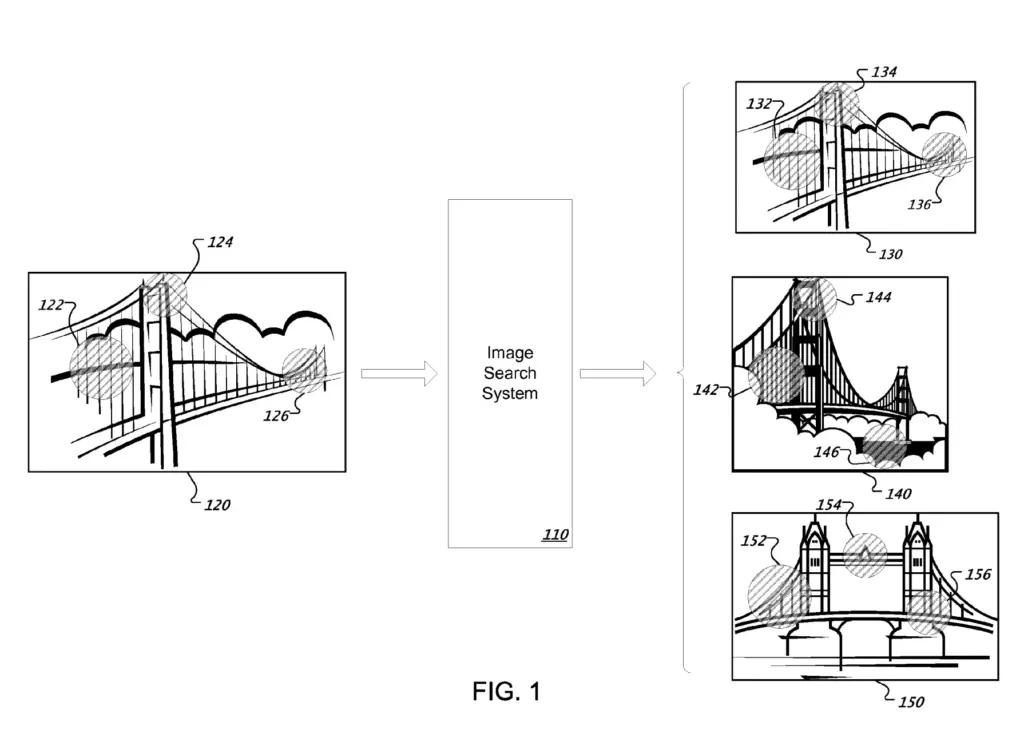
For each feature region, it logs feature data points into feature vectors. Then, visual words are assigned to each feature vector. Finally, it determines similarity by counting how many visual words each image have in common.
Image features are visual elements such as the colour and the shape of the image.
Creating Buckets of Duplicated Images
After computing image similarities, Google has vectors of images that contain geographical data (coordinates, shape and size of feature regions).
Each feature region has a visual word assigned to it.
Then, a similarity threshold is defined. Google may determine that for images to be considered near-duplicates, they need 5 common visual words (overlapping feature regions).
Then, any images that have more common words than the defined threshold would be clustered into a collection of near-duplicate images.
All the visual words of each image would be added together and assigned to the collection.
Each collection stores a collection ID, visual words and document IDs of each image in the collection.
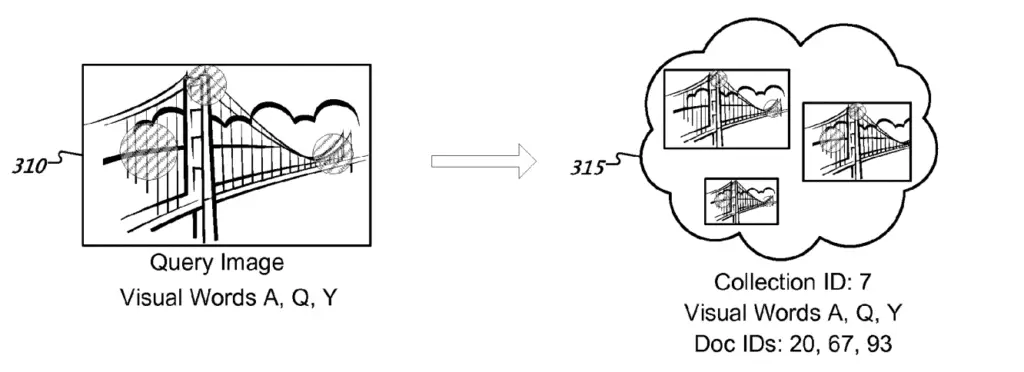
Adapting to Large Duplicate Images Collections
As the collection of duplicates grows, so does the number of visual words for that collection. Thus, larger collections are more likely to match a query image than smaller ones.
Two things can safeguard this issue:
- Having a maximum number of visual words per collection
- Requiring more matching words for larger collections than for smaller ones.
Large buckets of image collections can be separated into smaller buckets if they have too many visual words.
Alternatively, in order for the collection to match an image query, Google may require larger collections to match with more visual words than what they would require for smaller collections.
Assigning Duplicate Images to Posting Lists
Once we have collections of duplicated images, posting lists are created.
Posting lists are collections of documents containing a certain word.
In the image below, we see that each posting list includes a list where each element is a collection of near duplicate images along with its collection identifier.
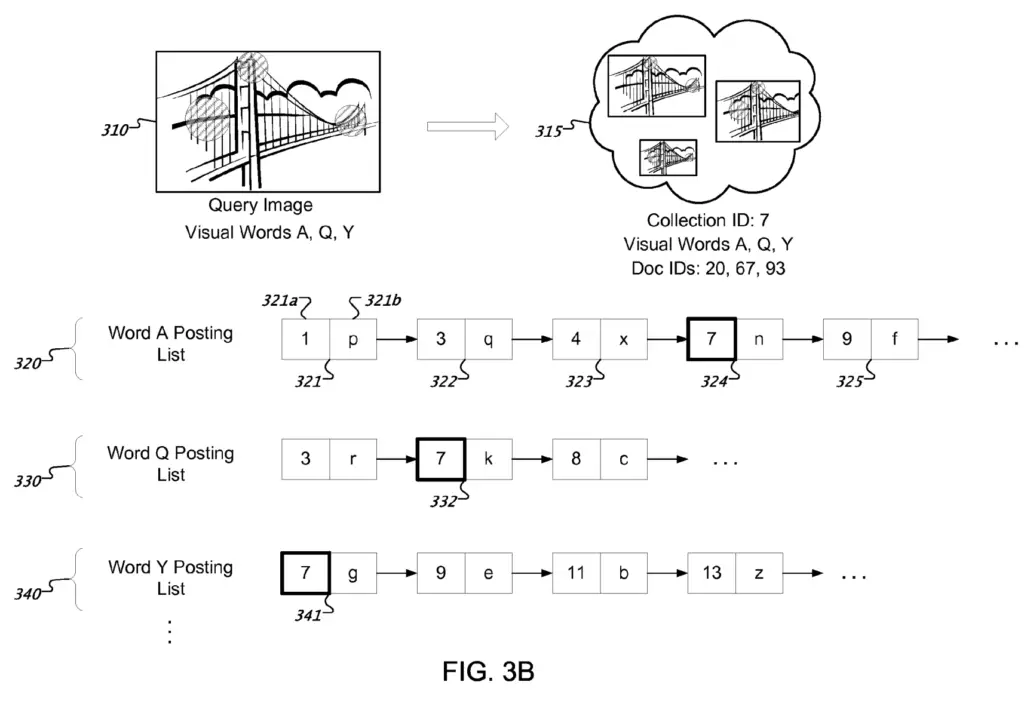
Additional data can be stored in the posting list such as the position and scaled of the feature region associated with the visual word. This can help compare the scale or position of objects of interests in the image.
By going through each posting list, the search system can identify the number of matching visual words between the query image and each collection of duplicate images.
Ranking Image Collections for a Query Image
When ranking images for an image query, Google goes through this process.
When a query image is submitted:
- Collections of near-duplicated images are sorted by relevancy.
- Individual images are selected from each collection.
- Selected images are shown to the user.
1. How Google Sorts Collections
First, in order to sort the collections for the query image, visual similarity is used.
As mentioned earlier, visual similarity can be computed by counting the number of overlapping visual words between the query image and the collection of duplicated images.
Large collections may require more visual words to match than smaller collections.
An additional way this computation can be improved is by checking where the visual words are located in each image.
Thus, when two images have the exact same visual words, the one where the coordinates of visual words are the closest would be considered more similar.
And before computing that distance, all the images in a collection are put on the same coordinate frame. The geographic mapping can be done through scaling, rotation, skewing, etc.
2. How Google Selects the Right Duplicated Image to show the user
When the collection of images is selected as relevant to a query, Google selects the most relevant image to the user.
Then, Google selects the most representative image of a set using the largest, the most selected image by user or the one with the highest similarity score.
Alternatively, they may show the image with the most appropriate size, color, copyright, type or time depending on the parameters that the users are adding to their query.

3. How Google displays Image Results to the User
It is not clear if this process only applies to query image search, but I doubt it.
That being said, Google can display image results in many ways.
The main display is through the recently merged Google Lens and Google Image search, which I have no documentation on how Google chooses to display results.
The alternative display is when showing image results through regular web search.
You can read more how Google does that in the post titled “How Google Displays Images Within Web Search Results?“.
Patent Details
| Name | Image Retrieval |
| Assignee | Google LLC |
| Filed | 2012-06-25 |
| Granted | 2014-12-30 |
| Status | Active |
| Expiration | 2033-06-22 |
| Application | 13/531,912 |
| Inventor | Henrik C. Stewenius |
| Patent | US8923626B1 |
What Categories is the Patent About?
- Indexing
- Image SEO
- Information Retrieval
Definitions
| Patent term | Definition |
|---|---|
| Visual words | Words computed by the image search system from local features of an image |
| Query image | Searches where an image was used to perform a search |
| Posting list | Sequence of documents identifiers associated to a term (posting) |
| Inverted index | Data structure used by information retrieval systems that is composed of a vocabulary of terms, along with list of term occurrences and locations in documents |
| Feature region | Geometrical shape drawn at a specific coordinates of an image that is used to evaluate each feature of an image |
| Image Features | Features that can be used to identify similarities between images. Examples of features are intensity, color, edges, texture, etc. |
| Feature vector | Vector where each element is a quantity that represents a feature value of a feature of the feature region. |
| Collection identifier | Integer ID used to identify a collection of near-duplicate images. Can be the value of any database key (index db, file system id, …) |
| Objects of interest | Elements that tend to commonly occur in a set of images. Can be estimated by looking at areas where color or shape changes significantly. |
Other Articles Related to Google Image
- How the Google Image Search Engine Works
- How Google Displays Images Within Web Search Results?
- How Google Selects the Most Representative Image of a Set
- Clustering Queries for Image Search at Google
Google Search Infrastructure Involved
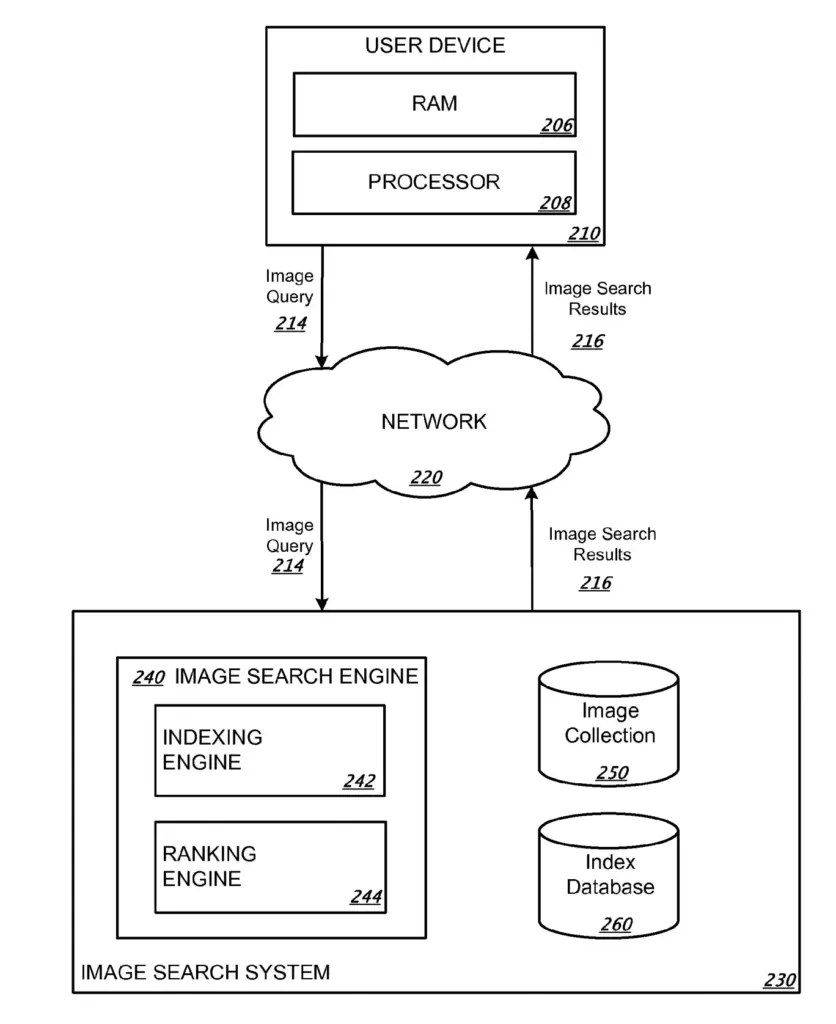
The “Image Retrieval” patent mentions these elements from the Google Search Infrastructure:
- Image Search System
- Image Search Engine
- Indexing Engine
- Ranking Engine
- Image Collection
- Index Database
- Image Search Engine
Google Image Retrieval FAQ
How Google handles duplicate images?
Near-duplicate images are grouped together as a collection of images. The collection is indexed and sorted, not the individual image.
How are the images stored in the image index?
Images are stored in posting lists as collections of duplicated images. Only a document ID points to the actual image.
How are images ranked when using an image as a search query?
Images, or more precisely collections of near-duplicated images, are sorted based on the number of similar sections (visual words) between the query image and each collection.
Conclusion
The “image retrieval” patent by Google was insightful into how Google de-duplicate images for image retrieval and image indexing.
Additionally, it also gives insights into how Google compare a query image and collections of near-duplicate images to compute the initial ranking that can be further improved later in the re-ranking process.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.