User behaviour impacts rankings. What if your web page ranks 9th for a query? Your page may not get much user behaviour data to show off for. But, what if the page that ranks 1st links to you?
Turns out your web page may inherit some of the high quality user behaviour data the the top result(s) has and help you move closer to the top.
In this post, I will cover how Google may use anchors (<a> links) to rank search results based on the patent titled “Ranking Search Results Based on Anchors” by Ajay P. Nerurkar.
Navigation
Show
What is the Patent About?
Google’s “Ranking Search Results Based on Anchors” patent is about how the rank modifier engine refines the initial set of search results that was returned by the search engine using behaviour data and anchor links.
The patent talks a lot about behaviour data and quality of result statistics which hints at how UX may influence search results ranking.
Highlights From Ranking Search Results Based on Anchors
What this patent stipulates essentially is that:
If a web page (A) links to another web page (B), and that linked web page (B) is also relevant to the query (Q) for which the linking page (A) ranks, then behaviour data for the linking page (A) will be passed on the linked page (B).
Here are some highlights.
- Behaviour data can impact not only a search result, but pages that it links to.
- Behaviour data is query-specific
- Links on page that do not rank, nor have behaviour data for a given query are not impacted by this patent.
- Links with negative anchor text about a page may be excluded (e.g. containing text like “bad”, “terrible”, “horrible”, etc.). This feature may only be done for specific categories of queries such as travel and products.
- Similar queries may be combined to increase the pool of pages that have behaviour data
- Though internal links may be used, in some cases, utilizing behaviour data may be limited to external links (from different domain addresses)
What is the Link Between User Behaviour and Anchors?
Many users visit web pages as secondary sources to find additional content.
For example, you may use secondary sources like Twitter or news feeds to find news worthy content to read. What you actually read is considered as the primary source.
Google can know user data about users clicking on the secondary sources from its search results, but have no idea which page you may have clicked on from the primary source (e.g. Twitter feed).
To overcome this challenge, Google tries to allocate at least some of the user behaviour data of the secondary source that was clicked on initially, to the links found in that web page.
What is an Anchor?
An anchor is the <a> an HTML element that is used to create hyperlinks to other locations.
It can link to web pages, files, or other locations within the same document.
It can take the form of a text-based hyperlink, an image, a video, etc.
Example of an anchor:
<a href="https://somelink.com">Anchor text</a>
What is User Behaviour Data?
According to the patent, user behaviour data is used to generate a quality of result statistic for each document. The quality of result statistic can impact ranking for a given query.
Behaviour data can be derived from:
- click data,
- biometric data,
- historical data,
- purchase decision data
Examples of behaviour data:
- Web pages where users visit for a “long” period of time (long click)
- Which document the user clicks on
- Tracking eye movements as they view search results
- Products searched for, viewed, purchased by consumers as well as details regarding those products.
Click data can be gathered in real-time or by looking at historical data.
It does not include:
- Web pages seen after viewing the selected document
Behaviour data is returned as a tuple
(document, query, aggregation of click data, location:"optional", language:"optional")
For more information on user behaviour data, read “Ranking search results based on similar queries” or “Propagating query classifications“.
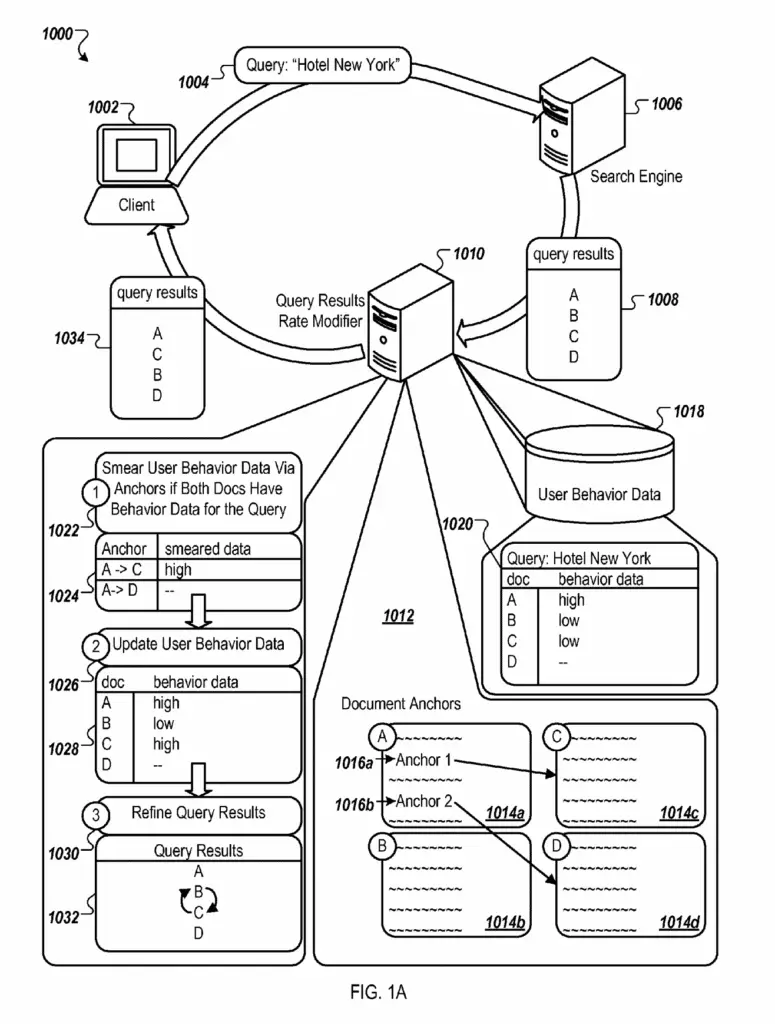
Understand the Query Results Rank Modifier
When a query is searched on Google, the search engine uses information retrieval to return an initial set of search results relevant to the query.
Then, Google tries to further improve search results using various techniques (rank transition, anchors, user feedback, …). This is done through the rank modifier engine. It is the core of the current article.
The rank modifier engine includes a software component called the query results rank modifier. The job of that software is to refine search results based on quality of results statistics of documents.
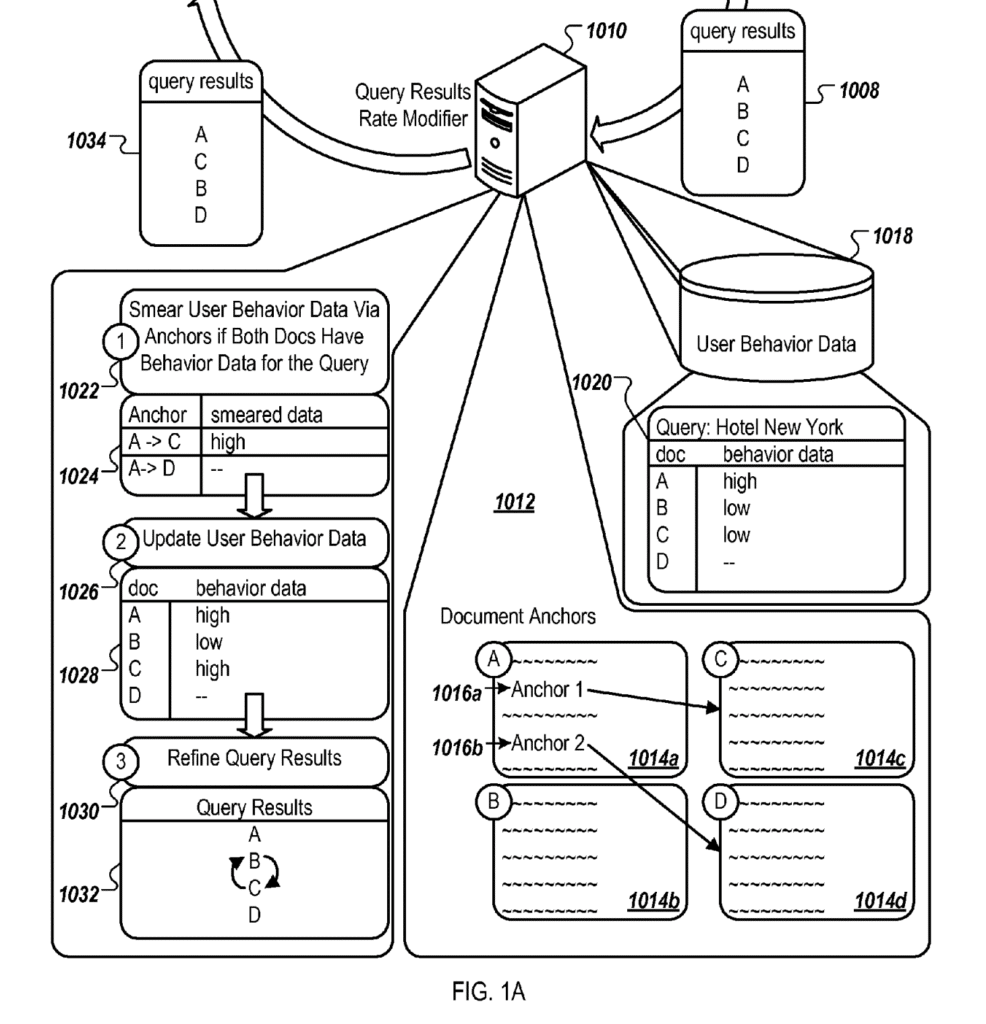
How the Rank Modifier Works
The way the query results rank modifier works goes like this:
- Receives an initial set of search result for a query
- Gathers quality statistics from user behaviour data
- Gathers relevant document anchors (see definition at the end)
- Fully or partially updates user behaviour data for the relevant linked-to documents
- Refines query results using the updated user data
For additional information on the query rank modifier engine, you can also read a patent named “Ranking search results based on similar queries” .
How Relevant Anchors are Determined
Anchors (e.g. <a> HTML links) are not always relevant to a query.
The analysis and identification of relevant anchors contained in search results is done by the results anchor analyzing component.
Four (4) things may determine the relevancy of an anchor.
To start, only links where both the document containing the anchor and the linked-to document have behaviour data for the query may be defined as relevant.
Furthermore, anchors that negatively describe the page may be deemed irrelevant. For instance, if a reviews says that the “hotel is disgusting and horrible”, the link that page may not be used to transfer behaviour data as users are more likely to have selected positive rather than negative reviews.
Moreover, terms present in both the query and the anchor text can indicate higher relevancy anchors. In opposition, important terms in the query are not present in the anchor can indicate lower relevancy anchors.
Finally, the location of the anchor may determine the relevancy of a link. Anchors present in boilerplate content or in footer for example, may be deemed less relevant to that query.
Example of Relevant Anchor Determination
Let’s see an example of how Google determines the relevance of an anchor for a query.
For instance, when searching for “Hotels in New-York” on Google, you may end-up on Tripadvisor.com.
On Tripadvisor, you may see a link to the “Margaritaville Resort in Times Square”, but also links pointing to “Expedia.com”, “Booking.com” and “Hotels.com”.
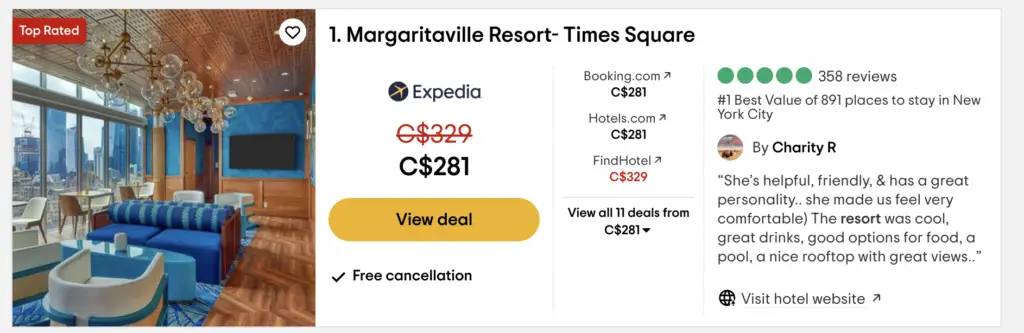
You may also see links to “things to do in New-York city” in the navigation or “terms of use” in the footer, which are not relevant to the query “hotels in new-york”.
Let’s evaluate the links below:
- Margaritaville Resort in Time Square
- things to do in New-York city
- terms of use
By looking in its behaviour data, Google sees no behaviour data related to any of the pages above because they simply do not rank for the query “hotels in new-york”.
Thus, they will not impact the re-ranking process.
Expedia, Booking and Hotels web pages however do have a lot of behaviour data for the query.
So, these 3 websites may inherit some behaviour data from the Tripadvisor website.
In addition, this would be true only if the links mentioned above truly were links that Google could see. In real-life, none of the links are visible to Google. Thus, no behaviour data is transferred to any of the links mentioned above.
Note that I am not talking of Tripadvisor here as an insider, nor commenting on the SEO strategy that may be used, but simply stating observations that anyone could see by analyzing the website.
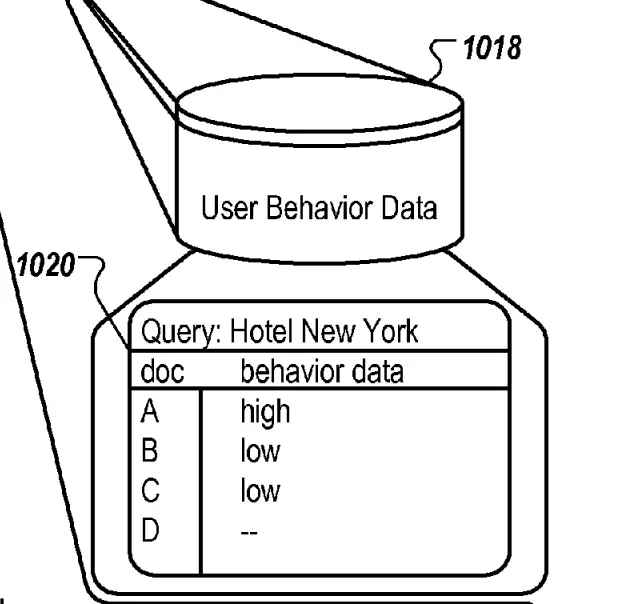
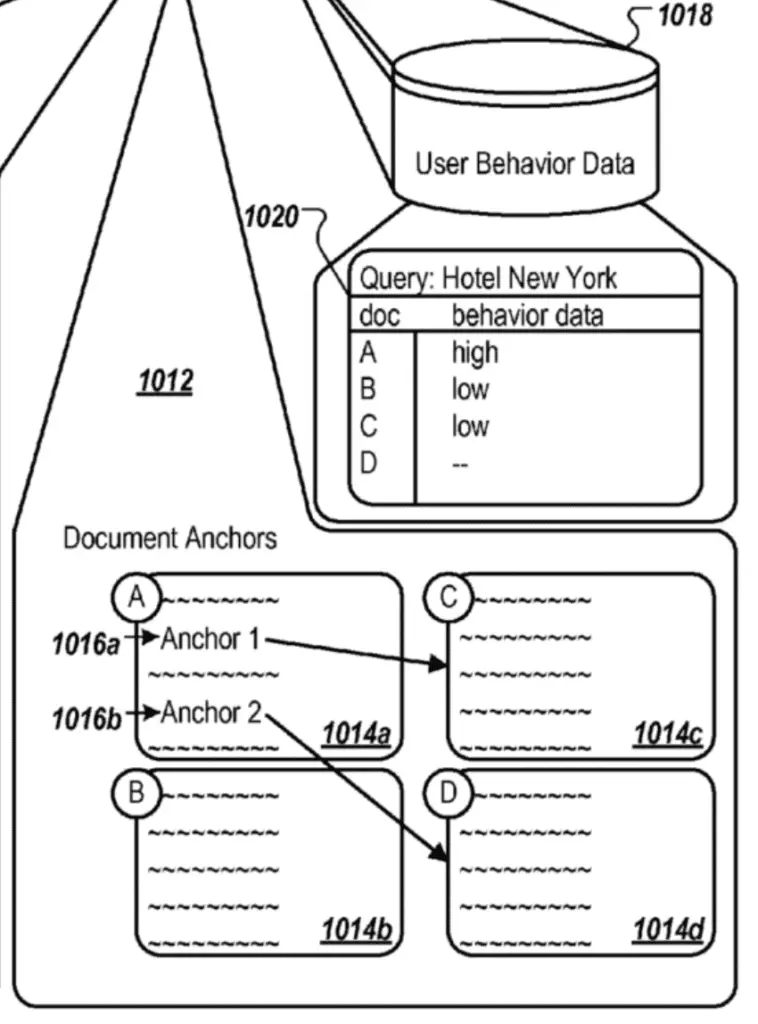
In the image below:
- B would not be impacted as no anchors link to them
- D would not be impacted as the anchor has no behaviour data for the query, thus not relevant to the query (1020)
- C would inherit full or shared behaviour data from A
- A may decrease or not depending on whether Google has browsing patterns data (not clear where Google would get that data).
Comparing Anchors to Queries
Estimating the relevance of an anchor to the query is a subject often mentions in Google’s link-related patents.
When comparing anchors to queries, Google go beyond matching text in the query to the text in the anchor.
Indeed, Google will look at:
- Anchor text of hyperlinks
- Surrounding text from the webpage in which the image was linked from
- Text from the webpage that the image links to
- If the anchor is a video or an image, it can look at metadata such as the EXIF metadata.
Before matching, Google processes the query and/or the anchors using techniques such as synonym substitution, stemming, etc.
For matching, Google use various text matchings algorithms like the edit-distance algorithm mentioned in the patent.
You can learn a lot more about query processing by watch Koray and Rebecca’s presentation “The Secret Life of Queries: Parsing, Rewriting & SEO“.
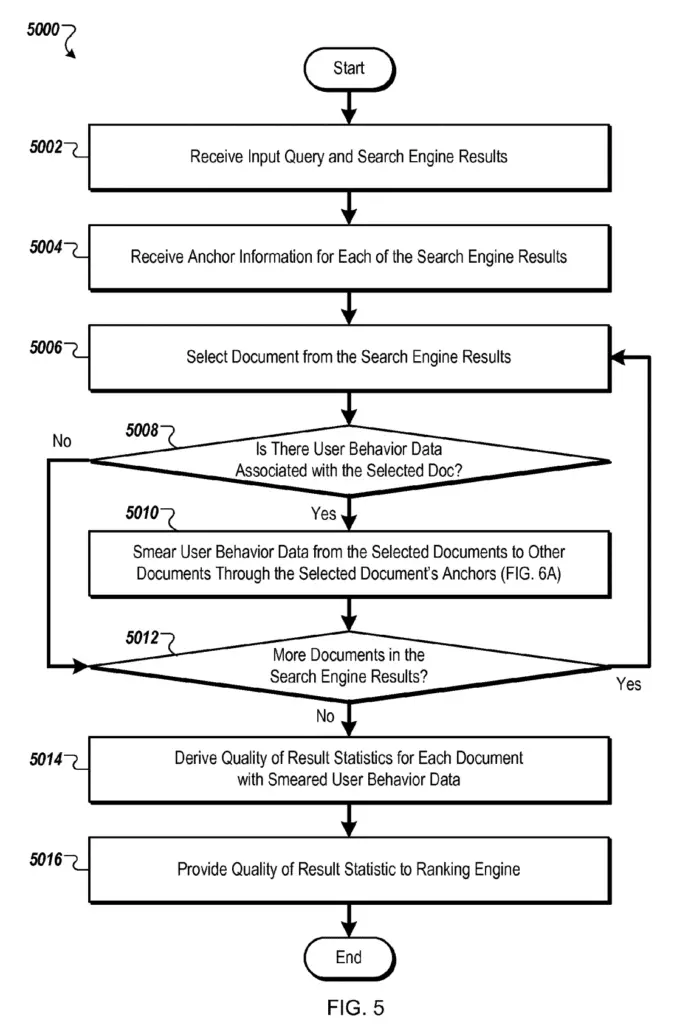
Process Used to Improve Search Results
The process below is a flow chart describing the full process that the query results rank modifier goes through to enhance search results with behaviour data.
Enhancing With Similar Queries
To improve relevancy, or simply to gather more data for pages that may not have enough user behaviour data for a given query, Google may consider similar queries to be relevant in passing on behaviour data.
A search result may not have behaviour data for “Hotels New-York”, but it does for “Accommodations NY”. In this case, Google may consider the results relevant to the query “Hotels New-York”.
This was a very quick overview of how similar queries may be use here. Read the patent linked at the start of this post to learn more about how this works.
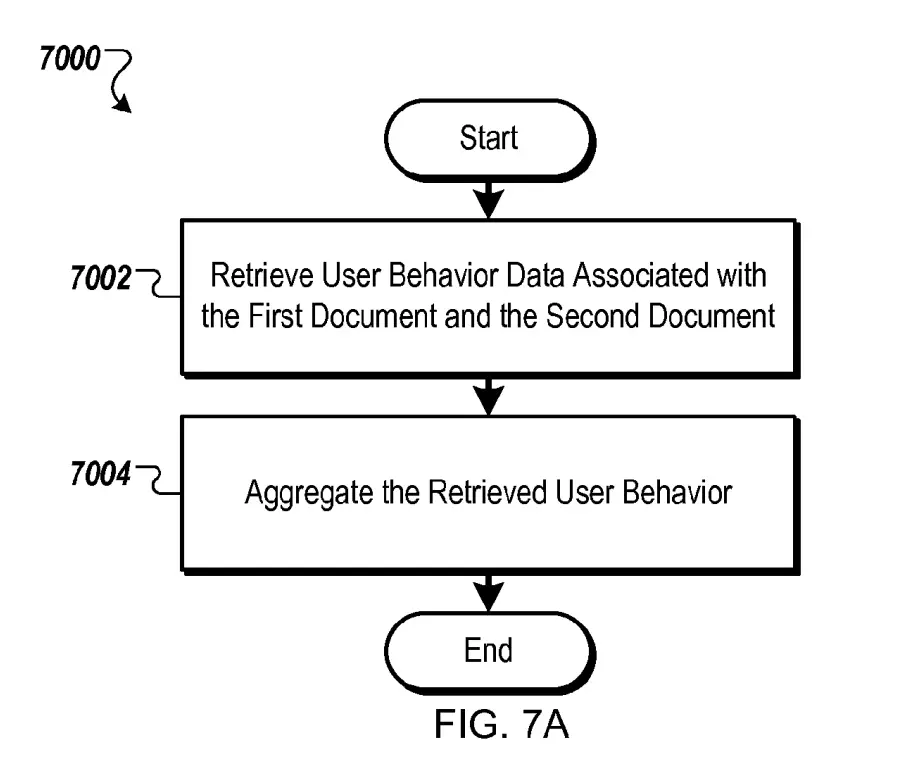
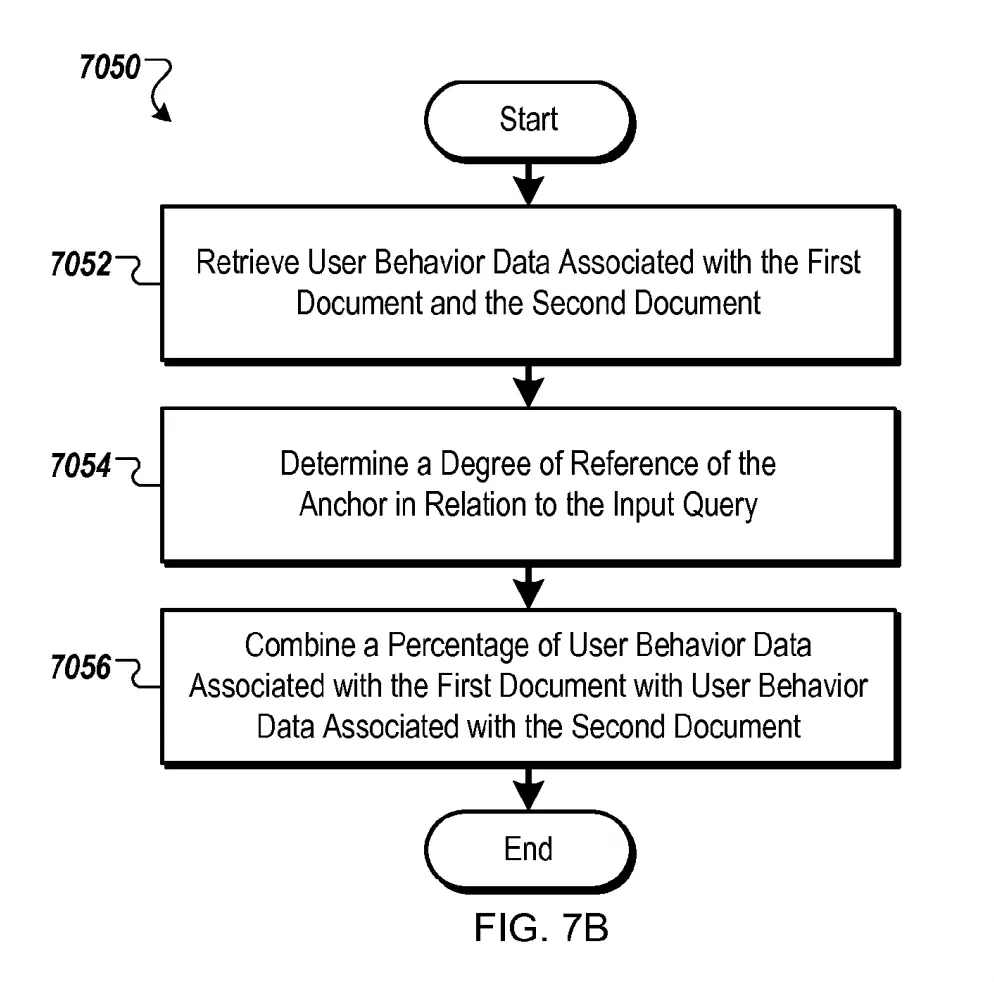
Combining Behaviour Data of Two Documents
There are three different ways how Google could combine the user behaviour of two documents :
- A replaces B in full
- A is combined to B to form an adjusted level for Doc B
- Doc A is combined to Doc B, but this time the percentage of relevance of the anchor to the query affects the percentage of the behaviour data that is combined
Where linking document user behaviour is A and linked document user behaviour is B
Examples Processes
Patent Details
| Name | Ranking Search Results Based on Anchors |
| Assignee | Google LLC |
| Filed | 2010-03-15 |
| Granted | 2015-02-17 |
| Status | Active |
| Expiration | 2030-11-02 |
| Application | 12/723,973 |
| Inventor | Ajay P. Nerurkar |
| Patent | US8959093B1 |
What Categories is the Patent About?
- Links
- Ranking
- Re-Ranking
Definitions
| Patent term | Definition |
|---|---|
| Relevant document anchor | Both the document containing the anchor and the document to which the anchor links have associated user data for the query. |
| Click data | Raw user behaviour data used to evaluate the quality of a search result for a query. |
| Quality of result statistic | Refined user behaviour data used to evaluate the quality of a search result based on historical click data as well other user engagement metrics for a query |
| Behaviour data | Data showing how users interact with search results |
| Anchor | <a> HTML element used to create hyperlinks |
Google Search Infrastructure Involved
The Ranking Search Results Based on Anchors patent mentions these elements from the Google Search Infrastructure:
- Search Engine
- Indexing Engine
- Scoring Engine
- Ranking Engine
- Rank Modifier Engine
- Query results rank modifier module
- Results Anchor Analyzing Component
- Tracking Component
- Result Selection Logs
- Index DB
Ranking Results Based on Anchors FAQ
What is a “long click”?
The “long click” is a measure of quality of a search result. The longer it takes for a user to come back to search after its initial click, the greater the implied quality of the result to the query. The “long click” is in opposition to the “short click” that denotes lower engagement of the user.
What is the click data?
The “click data” refers to how long a user dwells on a page after clicking on a search result.
How is click data measured?
The click data is the time between the initial click through the document until the time the user comes back to the search result and clicks on another document.
How is behaviour data combined between two documents?
If the anchor of a document is deemed relevant, the linked document will inherit user behaviour data in whole or in part from the linking document. If it is shared, a percentage of user behaviour data will be shared based on the degree of relevance.
Conclusion
That was a lot, so let’s try to summarize simply.
The Ranking Search Results Based on Anchors patent is used to refine search results based on anchors and user behaviour.
It tries to estimate if a page that is linked from another should inherit user behaviour data from the linking page.
If you rank 5th for a query, and don’t get much clicks, but the page that ranks 1st links to you, should you get some the user behaviour preferential treatment that page gets? This patent tries to answer that question and re-order results based on the answer.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.