In this post, I will cover some of what I have learned reading the Google patent titled “Clustering Queries for Image Search” by Yushi Jing, Michele Covell and Stephen C. Holiday.
The patent was filed in 2012 and has a pending status.
Navigation
Show
What is the Patent About?
This patent is showing how Google may cluster image queries together to provide more relevant and interesting image search results.
Query clustering can also be used reduce amount of storage required by reducing the need to calculate distance functions for each queries but instead do it only for each clusters of queries.
Highlights From Clustering Queries for Image Search
- Google clusters image queries to provide more relevant image search results
- Google uses either Kmeans clustering or hierarchical clustering to cluster queries
- Google may use image Ads as input to compute pairwise image similarity
- Google uses machine learning to train models to identify the most important image features in relation to the query.
How Image Query Clusters are Used?
Before we go into how clustering image queries work, let’s understand what is its objective.
Google wants to identify similar queries and then gather important image features for each group. This way, image features can be used to improve search results of the given query clusters.
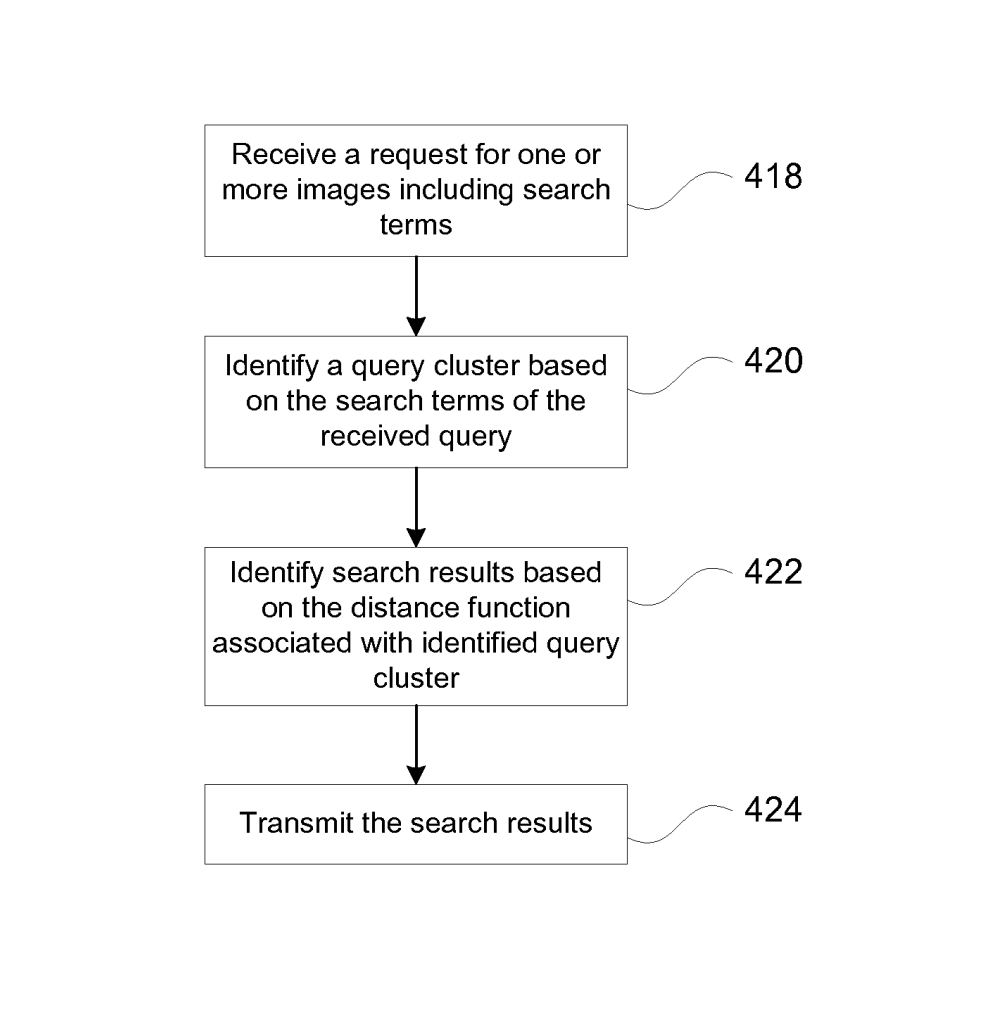
First, when Google receives an image search query, it associates the query to a query cluster.
That query cluster returns information about important features for the query (such as the colour, shape, …).
Then, it will identify the search results that are more appropriate to the query giving more weight to important features.
Then, it ends by serving search results.
Clustering Queries Pipeline
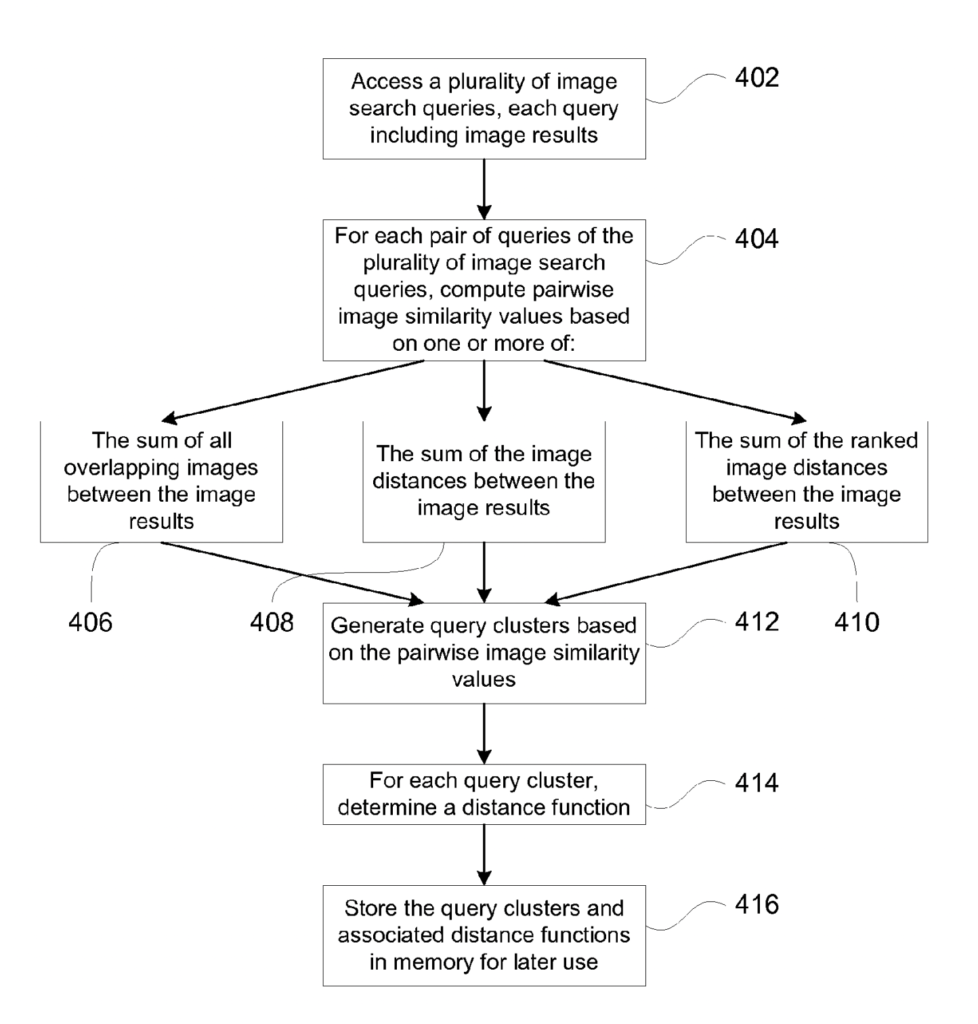
In this patent, Google:
- Receives image search queries
- Associates image search queries with a set of image results
- Groups queries in pairs
- Computes the similarity of images for each pair of queries
- Clusters queries based on pairwise image similarity values. Each cluster contains multiple image search queries
How is the Pairwise Image Similarity Calculated?
The pairwise image similarity can be calculated in four ways:
- Percentage of overlapping images between image results of the query pair
- Sum of the image distances between image results of the query pair
- Sum of the ranked image distances between image results of the query pair
- Co-occurence of pair of image search queries as keywords for image ads
- Simple hierarchical agglomerative clustering
- Computing KMeans on pairwise image similarity values
In 1, if 5 out of 10 images overlap, the overlapping score will be 50%.
In -3, if two image or ranked image queries return very similar sets of images, they will be clustered together. The image distance can be compared at image distance pixel by pixel for features that include color, brightness, texture, …
In 4, if keywords are used for the same advertising, the similarity value is increased.
In 5, combine queries clusters centers closest to each other until the optimal number of clusters is met.
In 6, select random cluster centers and reassign the mean as the cluster centers until convergence.
Historical Image Search Data
The historical image search data is a data store that includes:
- queries received,
- image results,
- user interaction,
- date and time,
- co-selected images for a query,
- co-selection value
- source of the image content,
- annotation information
How Query Pairs are Selected
Steps can be in a different order or even be skipped.
- Select queries from the historical search data
- Select candidate query based on annotations of images
- Collect all other queries apart from candidate query that has the same annotation
- Sort queries based on the frequency that it occurs in annotations.
Defining Most Important Features of Images Based on the Query
Google uses machine learning to train models to identify the most important image features in relation to the query.
For instance, for the query “apple” the most important image feature may be the colour. On the other hand, for the query “table”, the shape is probably more appropriate than the colour.
The way it is does is that Google calculates the pairwise similarity (pixel by pixel) of an image against a subset of other images in the cluster of image queries.
The result is a vector of weights of image feature in relation to the query context.
Example of how I believe the end vector may look like:
| query | color | brightness | shape | texture | … |
|---|---|---|---|---|---|
| apple | 0.9 | 0.1 | 0.6 | 0.5 | … |
| table | 0.1 | 0.2 | 0.9 | 0.3 | … |
| tree | 0.1 | 0.1 | 0.8 | 0.7 | … |
Let’s take a cluster of queries, such as a cluster that would contain the search terms: “apple”, “fuji apple”, “spartan apples”
If most query terms in the vector has “colour” as an important feature, the colour could be used to improve the image search.
How Google Assigns Image Features
From multiple patents, here are the listed features that can be assigned to images by the Image Features Module. The best patent to read if you are interested in how image features are generated is the patent named “Ranking of images and image labels” which I have covered in depth in the post titled “How the Google Image Search Engine Works“.
- Color
- Brightness
- Intensity
- Texture
- Shape
- Edges
- Wavelet based techniques
Reducing the Cost of Storage
Google evaluates visual distances between a set of images for each query and stores the distance function between queries.
By clustering queries together, you can store distance functions between clusters of queries instead.
Thus, when a new query emerges, instead of a new distance function being stored, the query may be clustered within a group of queries and inherit the distance functions from it.
What Categories is the Patent About?
- Query processing
- Image SEO
- Annotations
Definitions
| Patent term | Definition |
|---|---|
| Image Search Query | Search query for which the intent is to get a particular image content |
| Image Query Terms | Query terms with an image intent can be implied (rose bouquet), image features (color), filetype (jpg) or a combination |
| Pairwise image similarity | Similarity between the image results of pairs of image search queries |
| K-Means Clustering | Machine learning algorithm used for clustering. |
| Historical Image Search Data | Image search data store of queries, image results, user interaction and more. |
| Distance Function | Function that provides distance between the elements of a set |
Google Search Infrastructure Involved
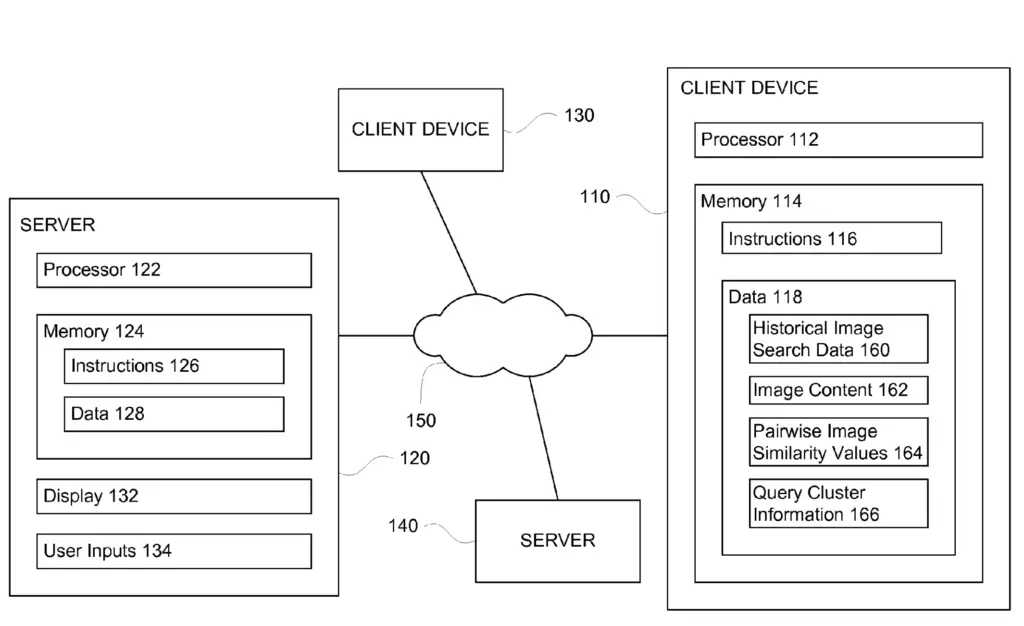
The Clustering Queries for Image Search patent mentions these elements from the Google Search Infrastructure:
- Databases
- Historical Image Search Data
- Image Content
- Pairwise Image Similarity Values
- Query Cluster Information
Sources
[1] Determining User Intent from Query Patterns
[2] Grouping of image search results
Conclusion
This patent was insightful on the way image search is returned, but mostly how these query cluster may impact the way images are returned based on the important features of a given cluster.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.