How does Google know if a document if fresh? Better yet, from that knowledge, does Google Search use document freshness in ranking? This article will shed light on the subject.
In this post, I will cover Google’s patent titled “Systems and methods for determining document freshness” by Monika Henzinger.

Navigation
Show
What is the Patent About?
Google’s determining freshness of documents patent shows how Google may determine and use freshness to score documents in retrieval.
The patent is an attempt to avoid returning out-of-date documents in search results.
Highlights From Determining Document Freshness Patent
- The freshness score may be used in ranking documents (ranking factor)
- Freshness comes from internal factors (last-modified-since) and external factors (linking documents)
- Having more fresh linking documents than outdated ones improves freshness score
- Having more links today than yesterday improves freshness score
- Having more fresh links than outdated ones improves freshness score
- HTTP header last-modified-since is used to evaluate the freshness of a document
Freshness as a Ranking Factor
According to the patent, freshness may be used as a ranking factor.
A freshness score (F), that, in some implementations, may be used in ranking document
when document is returned at a result of an executed document search, may be assigned to document based on the freshness attributes associated with each linking document of the set of documents, and/or based on times at which each link, pointing to document, existed.
What are “Fresh” Documents?
According to the patent, “fresh” documents are documents that have been updated or modified within a configurable period of time relative to a current time.
Generating the Freshness Score of a Document
Google tries to assign a freshness score based on the freshness attributes of a documents.
Freshness comes from internal factors (last-modified-since) and external factors (linking document).
1. Identifying Freshness Attributes
When the Google Search Engine receives a search query, it uses information retrieval techniques to search trough a corpus of documents.
For each document, Google tries to identify reliable associated freshness attributes to score the freshness of web documents. Mentioned attributes are:
- HTTP last-modified-since
- Proportion of “fresh” documents linking to the document
- Creation and removal time of links pointing to the document
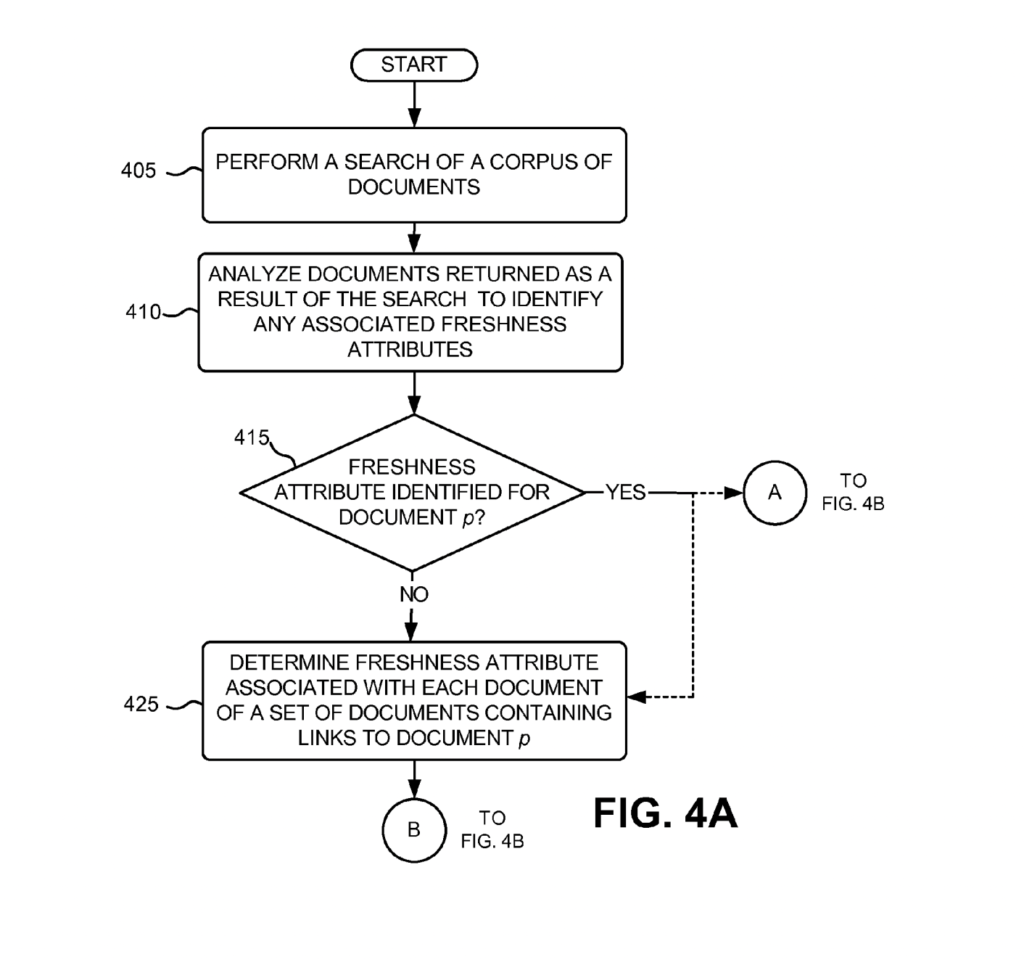
First, Google checks if the document has an HTTP last-modified-since attribute. If yes, it uses it as a basis for the freshness score.
If it doesn’t, then the freshness score must be evaluated.
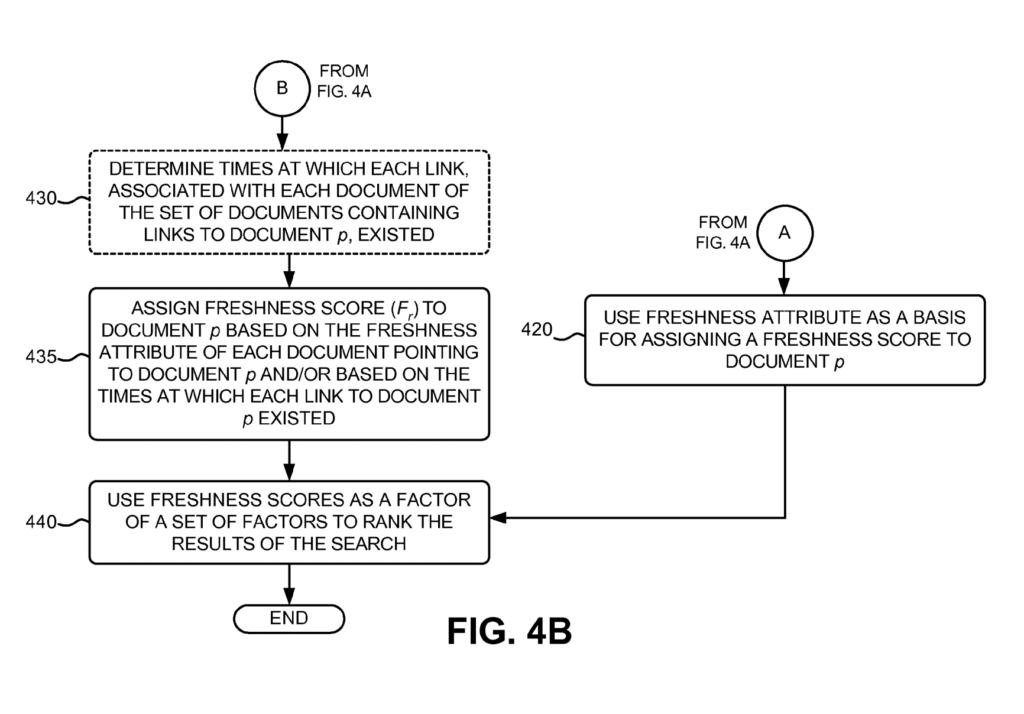
2. Evaluating Linking Documents
When the document freshness attribute is not available, Google must look at linking websites to evaluate the freshness score.
It may select all, or a set of random, documents that have, or previously had, links to the target document.
To determine freshness of linked documents, Google looks at the proportion of the linking documents that are considered “fresh”.
The more recently update documents linking to your page compared to out-of-date, the greater the freshness score of your web page.
#pseudo code for logic
if "out-dated document links" > "fresh document links"
then document freshness score = "low" and is_fresh = False
else if "fresh document links" > "out-dated document links"
then document freshness score = "high" and is_fresh = True3. Evaluating When Links Were Created
In some cases, Google will go even further and evaluate when the specific link was created and/or removed.
So, even if pages are considered fresh, maybe some links aren’t.
The freshness of the links may influence the freshness score.
The freshness score can be reduced by specific links in two ways:
- If there are less links now than it used to (lots of links removed)
- If the ratio of old links vs new links is too high (not enough new links created)
Are There More Links Today Than Yesterday?
If the number of links that currently point to a document is smaller than the number of links that pointed to it at some time in the past, then freshness score is smaller.
#pseudo code for logic
if "links in 2019" > "links in 2022"
then document freshness score = "low" and is_fresh = FalseAre There Many New Links?
Another implementation may look at the proportion of new links compared to older ones?
If there are not enough new links, the freshness score may be reduced.
Last-Modified-Since HTTP Header
I am not sure here what the patent refer to as the “last-modified-since” HTTP header, but it is likely a combination of the “last-modified” and the “if-modified-since” HTTP headers.
What Categories is the Patent About?
- Scoring
- Information Retrieval
- Ranking
- Quality
Definitions
| Patent term | Definition |
|---|---|
| last-modified-since | HTTP attribute that indicates the day a last modification was made to a document. |
| freshness score | Measure of how fresh a document is |
| freshness attribute | Annotation that provides an indication of when a linking document was last updated |
| document | Any machine-readable and machine-storable work product |
Google Search Infrastructure Involved
The “Systems and methods for determining document freshness” patent mentions these elements from the Google Search Infrastructure:
- Server
- Search engine
- Ranking engine
- Search engine
Determining Document Freshness FAQ
How Google Evaluates the Freshness of a Document?
HTTP header last-modified-since and external links and document freshness
What attribute Google uses for Freshness?
The HTTP header last-modified-since
Does Google use Freshness as a Ranking Factor?
According to this patent, yes. However, it is always possible that that a patent is not used in search.
Patent Details
| Name | Systems and methods for determining document freshness |
| Assignee | Google LLC |
| Granted | 2013-08-20 |
| First filed | 2011-12-19 |
| Status | Active |
| Expiration | 2023-12-31 |
| Application | 13/329,938 |
| Inventor | Monika Henzinger |
| Patent | US8515952B2 |
Conclusion
According to this patent, Google uses freshness to rank document so that they are not surfacing outdated content to the user.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.