In this article, I will cover some of what I have learned reading the “Ranking Search Results” Google patent by Navneet Panda and Vladimir Ofitserov.
Disclaimer. This patent is now expired, and has been covered much more extensively by the late Bill Slawski (listed at the end of this post). This tutorial is simply an attempt to reconcile and find this piece of engineering’s place within the broad Google search infrastructure. If you have read Bill’s, you will not likely learn new things until the broader picture is drawn at a later date.
This patent is a very important one and likely the one behind the Panda algorithm update.
It is not longer a separate system, but integrated into the core algorithm (see list of ranking systems).
The patent was filed in 2012, renewed in 2017 and set to expire in 2032.
Determining Site Quality
The Panda algorithm update was meant to reward high-quality websites and penalize low-quality ones from Google organic results. The original Panda update was trying to improve search results by demoting low-quality content (not links).
It tried to promote good content rather than trying to identify attempts to manipulate search results.
Summary of the Patent
In a nutshell, based on the “ranking search results” patent, a website with a lot more queries assigned to from unique users compared to the number of links will be re-ranked as a higher quality site.
It works in many parts:
- Grouping pages together
- Looking at Links for the group
- Looking at targeted queries for the group
- Looking at the two factors above as a ratio
- Use the ratio to modify the initial ranking score
Grouping Pages Together
In this patent, Google does not target specific pages. Instead, it groups pages together and provide a score for the group.
A group of resources is a portion of the resources on the Internet.
They way pages are grouped is:
- Same domain: All URLs under the same domain name could be grouped together example.com
- Same hostname: All URLs under the same host. Subdomains for given countries could be grouped separately even if they are all under the same domain.
- Portion of URLs under same host: Larger sites could have a portion of their site grouped together: the “shoes” section of a larger eCommerce site for instance.
- Reference query count: Multiple groups for a single domain, or multiple domains in a single group
Identifying independent Links
Incoming links are used as part of the ratio of independent links to referring queries.
- Determining incoming links to a group of resources.
- Removing links that seem affiliated with the site
- Identify number of independent linking sites and pages
Incoming links can be implied links (mentions without links). Though these links don’t pass authority, they may pass the penalty (Bill Slawski).
The way Google “knows” if links between two sources are independent is by looking at the likelihood of:
- being included in the same groups of resources
- being related (owned, hosted or created by the same entity)
- being duplicate (similar content, images, CSS, …)
The system may consider different number of links from a source to a target to be an independent links depending on the cases. They may consider:
- A single link
- The total number of independent links
- A logarithm of the total number of links
Identifying Reference Queries
The patent then tries to identify content farms (websites targeting one page per commercial query without building quality content around it).
To do so they:
- Count of queries related to the group of resources
- Determining group modification factor based on inlinks and query-count
The queries related to a group of resource are determined by looking at the historical queries that users searched before clicking through a web page.
For instance:
- The query “example.com” can be assigned to the example.com homepage
- The query “example san francisco” can be assigned to the sf.example.com document
Only the first query submitted by any unique users is considered as a reference query.
How Does the Score Modification Engine Works?
Here are a few takeaways from how the scores are modified:
- The modifier score decreases as the initial score increases. Thus, the higher the initial ranking, the less impacted by the score modifier you are.
- Navigational queries are not impacted by the score modifier
- The more reference queries you get compared to the number of links, the higher quality your site is perceived
The score modification engines is separate from the search engine and comes in after the initial scoring is made by the search engine.
The score modification engine receives data identifying a resource and an initial score for the resource, provides a score modifier and stores the data into the modification factor database.
The initial score can be a measure of relevance of the resource to the search query, a measure of the quality of the resource, or both.
The output of the score modification engine provides scores associated with groups of documents. The search system will then use those scores to generate a resource-specific modification factor based on the group modification factor.
To sum up, the search engine sends scored documents to the score modification engine, that groups them and provide a modification factor back to the search system for it to update the score of each document.
It does so only if the query is not navigational and if the resource is score above a certain threshold.
Definitions
| Term | Definition |
|---|---|
| Independent link | Link between two independent resources |
| Independent resources | Resources that are not owned, hosted or created by the same entity and are not likely duplicated |
| Implied Link | Reference to a resource that does not contain an hyperlink |
| Navigational query | Query submitted in order to get a single, particular website or webpage of an entity. e.g. “example.com login” |
| Unique user | User identified by a cookie or login identifier |
| Reference query | Query assigned to a document |
| Modification factor | Number of independent links to reference queries ratio. e.g: M=IL/RQ |
Ranking Search Results Patent FAQ
What is the Score Modification Engine?
Google’s score modification engine is a component of the search systems that generate modification factors to the initial scores generated by the search engine.
What is an Independent Link?
Independent links are the links shared between independent resources.
The links can be express links (hyperlinks), implied links (mentions without a link), or both.
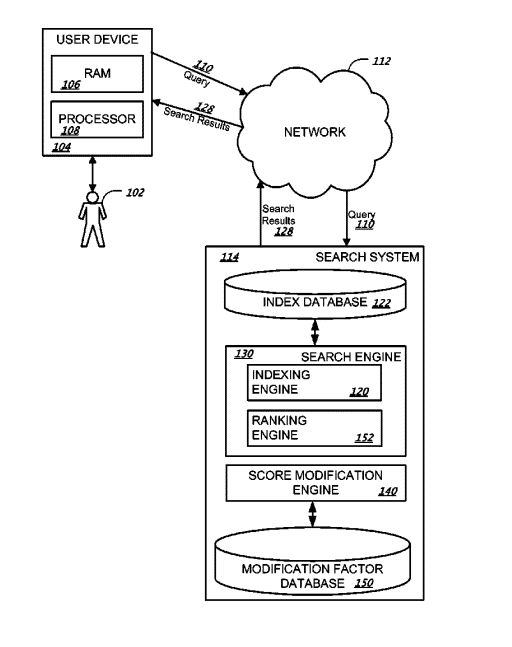
Google Search Infrastructure Involved
The Ranking Search Results Based on Anchors patent mentions these elements from the Google Search Infrastructure:
- Search System
- Search Engine
- Indexing Engine
- Ranking Engine
- Index Database
- Modification Factor Database
- Search Engine
Important Coverage of the Patent
The late Bill Slawski wrote about the patent extensively before me and his work should a source of truth before the present article. I truly recommend reading these two articles to understand the patent more in depth:
- Is Ranking Search Results the Panda Patent?
- Changes to the Panda Patent, Behind Google’s Panda Update
Conclusion
What is to be understood from the “Ranking Search Results” patent is that website that have a very few amount queries assigned to each page of a website would be penalized by the patent.
A website that has 10 searches a going through it from search, but has 10K pages will have a very low referred query, and the rank modifier score will end up penalizing it.
I have tried to make the best out of what I understood from the patent and am happy to discuss with anyone who may have interpreted differently the “ranking search results” patent.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.