In this series on learning SEO with Google patents, I will cover some of what I have learned reading the Google patent titled “Multi-stage query processing system and method for use with tokenspace repository” by Jeffrey A. Dean, Paul G. Haahr, Olcan Sercinoglu, Amitabh K. Singhal.
From the names in this list of author, we can tell that this is a very important patent to understand query processing in search engines.
Navigation
Show
What is the Patent About?
Google’s Multi-Stage Query Processing patent is about how Google prepares queries to be matched against the terms of the documents prepared as an inverted index.
The patent describes how:
- The inverted index is prepared by the Document Processing System
- The queries are parsed, transformed and expanded into query terms and query expressions
- 4 stages of query processing happens to generate relevancy signals between query terms and document terms
Highlights From Multi-Stage Query Processing
The most interesting highlights of the multi-stage query processing system patent are:
- The tokenspace inverted index is split in smaller indexes of closely related terms
- Sub-indexes are grouped by prioritizing terms found in similar language, same domain, same folder, etc.
- Queries are parsed, tokenized, stemmed, striped from stop words and expanded with synonyms
- There is a ton of work done to partition, encode/decode and compress each lexicon to save bytes
- The query processing system generates snippets from ranked documents and these generated snippets can be used to score documents in a second pass
- Google has a DocId, so even if a URL changes, the DocID stays the same.
Document Relevancy Score
The patent mentions relevancy scores that are computed by one or more scoring algorithms. The relevancy ranking factors influencing query-document relevancy score that were mentioned in the patent are:
- Presence of query term,
- term frequency,
- matching boolean logic and operators (AND/OR),
- query terms weight,
- document popularity
- document importance
- document interconnectedness
- proximity of the query terms to each other
- query context
- query attributes
- font attribute (font size, bold, underlined, etc.),
- position attribute (in title or headings vs body, first paragraph vs any paragraph in the content)
- metadata
- position in the query tree (terms in the query string may weigh more than terms the expanded representation of the query)
- relevancy feedback from ranked documents (2nd pass)
- terms found in the ranked documents are used to expand query and these expanded terms modify relevancy score
- terms found in the generated documents’ snippets of ranked document are used to expand query and modify query term weights. These new weights and expanded terms modify relevancy score
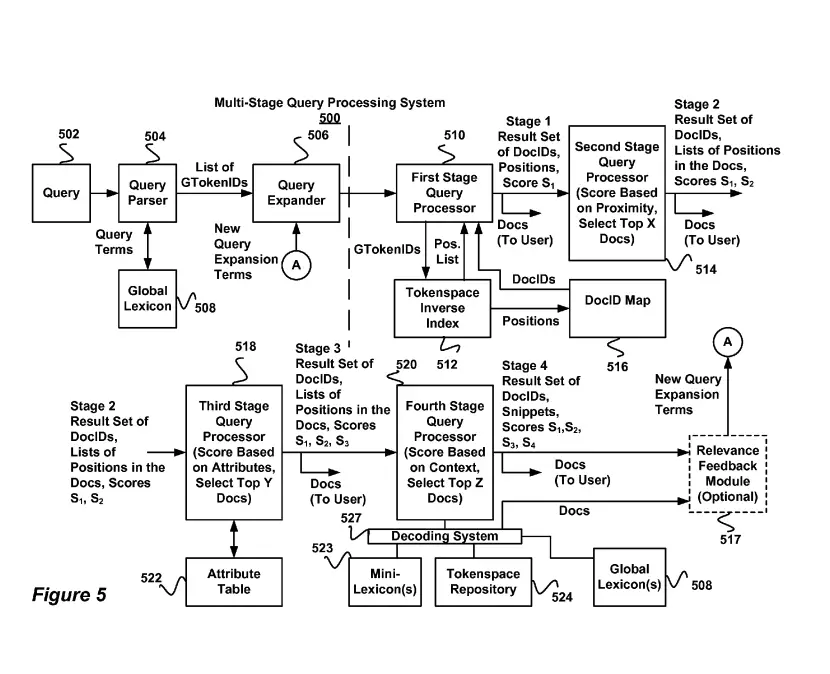
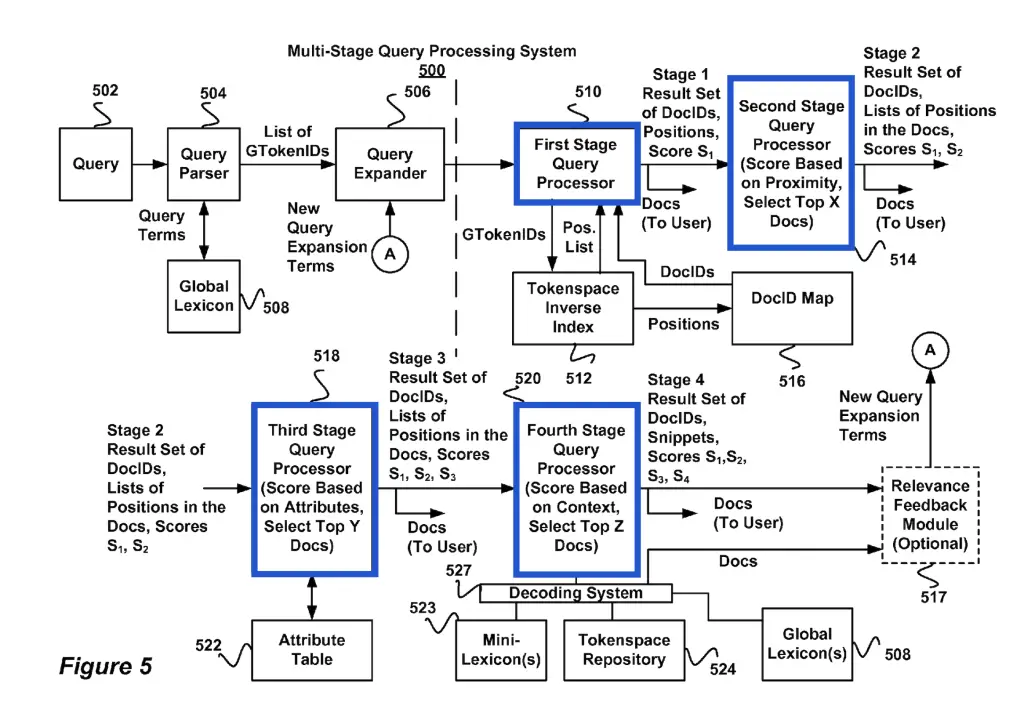
How Multi-Stage Query Processing Works at Google
Multi-stage query processing works in 4 stages, where the first stage parses and transforms the queries into query terms and their query expressions.
The second and third query processing stages generate relevancy scores for document terms in relation to the query using the inverted index received from the document processing system
The last stage generates a relevancy feedback to expand the query and use the expanded query expression to re-process the first 3 stages once again.
How it works at a high-level:
- Documents are processed into tokens and then creates an inverted index with the words in the documents
- Query processing system (QPS) understands and parses the query into tokens
- QPS generates scores for queries based on proximity with document terms
- QPS generates second score based on term attributes (e.g. H1) 5.
- QPS gathers ranked documents and run the scoring algorithm again to improve score based on ranked documents
Steps Described in Multi-Stage Query Processing Patent
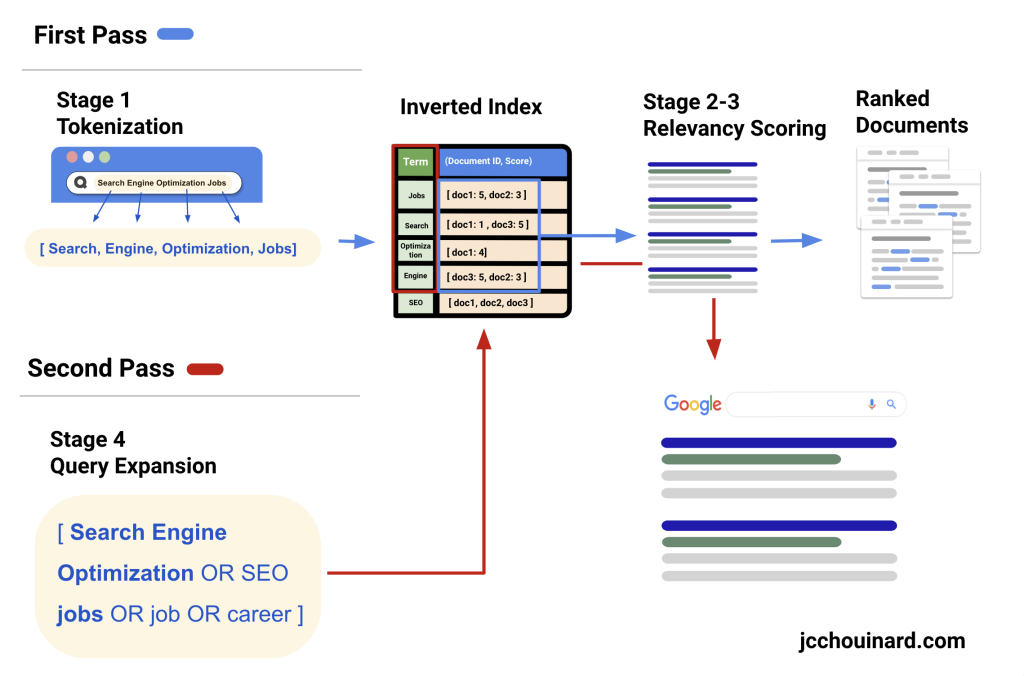
The Multi-Stage Query Processing Patent describes the following elements relevant to query processing:
- How the document processing system creates and encodes the inverted index
- How the query processing system parse the query and generates relevancy scores for the documents in the inverted index.
1. Document Processing System
The document processing system is the system that prepares the inverted index from documents, pages or sites retrieved from the document corpus. It is not part of the query processing system but is described here because the way the inverted index is built depends on the query processing system.
It is mainly composed of:
- Lexicon generator(s)
- Encoding System

The document processing system describes how a lexicon (or vocabulary) of terms is extracted from documents and stored in an inverted index where each term is associated with a posting list. This task is done by the lexicon generator(s).
Lexicon Generator(s)
The lexicon generator is the software that generates the lexicon mappings encoding a set of parsed documents. In a nutshell, it builds a lexicon, organize and split it into smaller lexicons for efficiency and sends the lexicons for encoding before it is stored in the tokenspace repository.
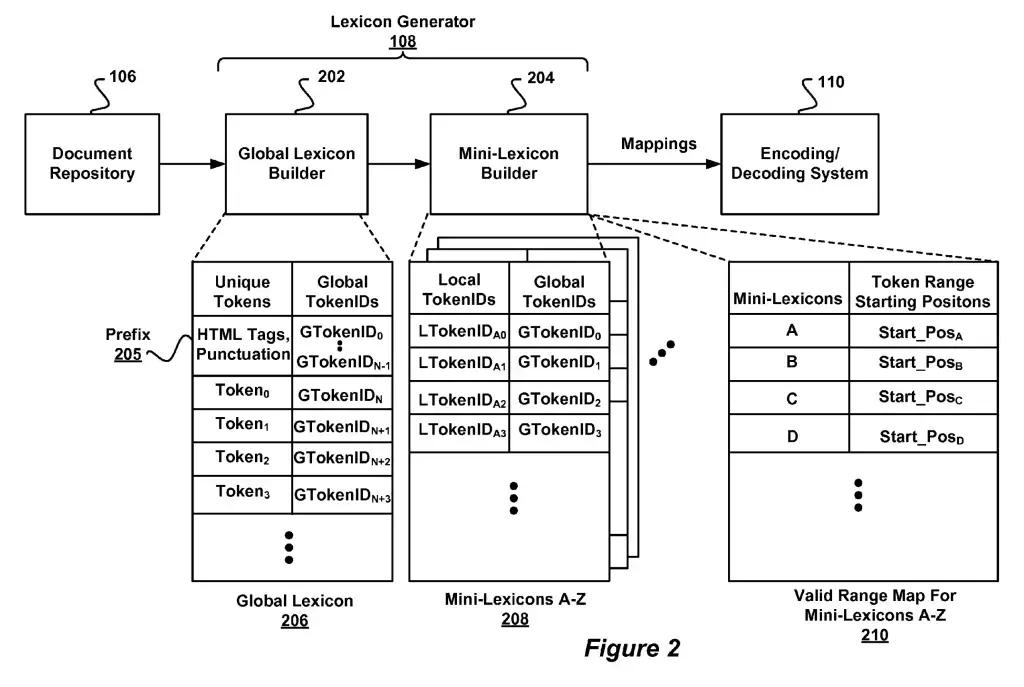
To understand that, we need to explain that the inverted index (used in information retrieval) has two parts: a vocabulary of terms (lexicon) and a inverted list (posting list) associated with each term.
Each term in the vocabulary is mapped to an ID. This mapping is what we call a lexicon. The vocabulary is generally too big for a single index, so that it is organized so that similar terms are closer to each other and it is split so that it smaller and more efficient at retrieval time.
The main (global) lexicon is built by the global-lexicon builder and sub-lexicons are created and mapped back the global lexicon by either the mini-lexicon builder or the region lexicon lexicon builder.
Encoding System
Then encoding system is the system used in Google’s Information retrieval system for encoding data of variable-length to conserve space and increase throughput. Simply put, it is the system used to encode and compress the inverse index in an efficient manner.
2. Query Processing System
The query processing systems receives a query, parse it, and generates relevancy signal for the documents in the inverted index in order to return the best matching result for the query.
It does so in 2 passes and 4 stages. The first pass (stage 1-3) parses the query, generates relevancy signals and return an initial set of results. The second pass (stage 4 and 1-3 again) generates a query expansion based terms found in ranked documents and reranks documents using the expanded query.
- First Stage: Query string is parsed, transformed and expanded in a query expression used to search against the inverted index to return an initial list of document IDs.
- Second Stage: Relevancy scores are generated based on the proximity of query terms in documents. (sales jobs – sales jobs is better than jobs in sales)
- Third Stage: Refining relevancy scores using term attributes (e.g. terms in H1 weigh more than in body)
- Fourth Stage: Generates fourth set of relevancy scores using the relevance feedback module, sort the lexicon and generate snippets for the documents listed in the result set.
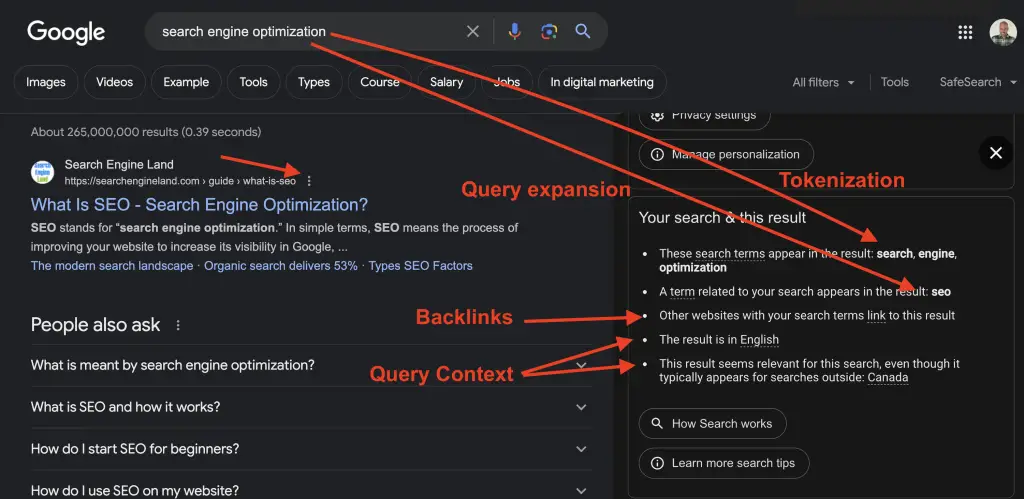
How to Know How Google Processed a Query?
By clicking on the 3 dots next to a search result in Google search , you can view the “About this result”. If you scroll down to the “Your search & this result”, you can gain insights into Google’s processing of your search query.
This example shows how Google tokenized and expanded the search query. If you check different types of queries, you’ll discover that certain words don’t always mean the same thing to Google based on the context of the query.
What Categories is the Patent About?
- Semantic SEO
- Query processing
- Document processing
Definitions
| Patent term | Definition |
|---|---|
| Query Processing System | Any processing system used to retrieve documents based on the terms found in a query |
| Query Processing | Process by which search engines try to generate the best-matching answers to a given user query, in the least amount of time. |
| Query Term | Distinct terms found in a user search query. Query terms can consist of words or phrases. |
| Query Parser | Module used to tokenize and parse the query string into query terms. |
| Query Expander | Software that is used to expand search queries into a query tree, or other query representation |
| Query Processor | Query processing server containing all the computing systems used in query processing |
| Query String | Unparsed string of text used in a search query |
| Query Tree | Query representation of the textual query after it wase scanned, parsed, validated and expanded |
| Query Session | Record comprised of one or more queries from a single user, including all queries over a short period of time, or a sequence of queries having overlapping query terms over a longer period of time. Record includes the query term(s), timestamp, IP address and language |
| Query Expression | Defines the search criteria for retrieving documents using context. It consists of query terms, operators and special characters that users can use to add context to their query. |
| DocID Map | Set of DocIDs for the documents corresponding to token positions |
| Global Lexicon | Data Store for the mappings of all unique tokens and their global token identifier in a set of document |
| Inverted Index | Data structure used by information retrieval systems that is composed of a vocabulary of terms, along with list of term occurrences and locations in documents |
| Information Retrieval System | System that matches queries against an index of documents generated from a corpus of documents |
| Relevance Feedback Module | Module that generates one or more new query expansion terms based on documents in the result set produced by the last query stage |
| Scoring Tree | Weights associated with terms in the query tree |
| Snippets | Small portions of text from a document, typically including text appearing around keywords being searched |
| Term attributes | Attributes associated with terms such as font attributes, position attributes like title and headings and metadata. |
| Tokenspace inverse index | Inverse index that maps the the token Ids in a set of documents to their positions within the documents |
| Tokenspace repository | Tokenized collection of documents |
Google Search Infrastructure Involved
The “Multi-stage query processing system and method for use with tokenspace repository” patent mentions these elements from the Google Search Infrastructure:
- Information Retrieval System
- Document Processing System
- Document Repository
- Lexicon Generator
- Global Lexicon Builder
- Mini-Lexicon Builder
- Encoding System
- Decoding System
- Query Processing System
- Tokenspace Inverse Index
- Query Processor(s)
- Query Parser
- Query Tree
- Query Expander
- First/Second/Third/Fourth stage Query Processor
- Databases
- Tokenspace Repository
- Global Lexicon
- Mini-Lexicon
- Attribute Records
- Lexicon Translation Tables
- Validity Range Map
- DocID Map
- Document Processing System
Patent Details
| Name | Multi-stage query processing system and method for use with tokenspace repository |
| Assignee | Google LLC |
| Filed | 2013-03-26 |
| Status | Active |
| Expiration | 2025-08-09 |
| Application | 13/851,036 |
| Inventor | Jeffrey A. Dean, Paul G. Haahr, Olcan Sercinoglu, Amitabh K. Singhal |
| Patent | US9146967B2 |
Going Further
The multistage query processing patent is quite old. However, it is continued with these patents, in which you will find lots of structural similarities:
From The Community
Soumyadeep Mondal talked about the cost of retrieval (thanks!), a concept important in Koray’s Topical Authority course. Here is how we can use concepts learned from the Multi-Stage Query Processing patent to reduce cost of retrieval.
- Keep similar topics closer to each other in the page, don’t talk about a topic, switch to another, and talk about the same topic later in the page. Not sure if it is necessarily wrong to do so, but it increases the cost of retrieval.
- Make URL patterns relevant to your topics. Group similar topics under the same URL pattern. This would help google cluster similar tokens under the same compressed inverted index.
- Don’t expand too much out with topics that are too broad. If you talk about widely different topics in a page, or a URL cluster, you will increase cost of retrieval by forcing Google extra processing to keep similar tokens close in the index.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.