In this tutorial, you will learn everything about the document processing system used in information retrieval (e.g. Google Search Engine). I will explain what the Document Processing System is, how it works, and how Google may use it in their infrastructure to provide search results.
This tutorial is part of a series on learning information retrieval and learning SEO using Google patents, specifically related to the article on “Multi-stage query processing system and method for use with tokenspace repository“.
Navigation
Show
What is Google’s Document Processing System?
At Google, a document processing system represents any computer system used to receive and process documents.
The document processing system is the system that prepares the inverted index from documents, pages or sites retrieved from the document corpus.

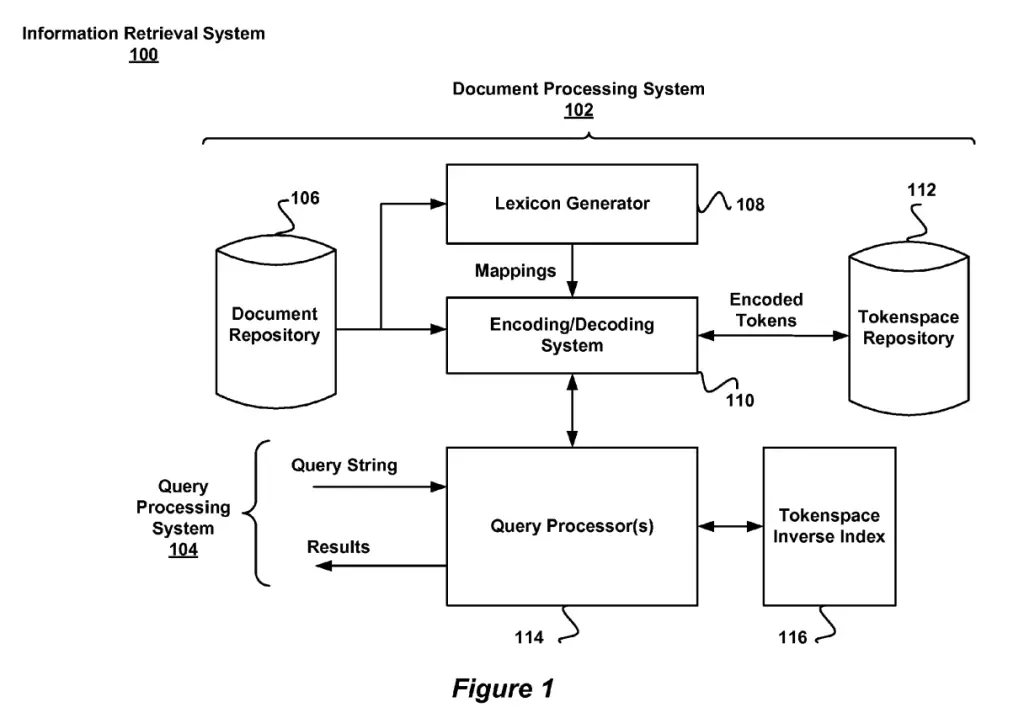
Document Processing System in the Information Retrieval System
In Google’s information retrieval system, the document processing system include the systems used to crawl, parse, cluster and store documents or portions of documents into a document repository to be processed by the query processing system.
It is likely located inside the Indexing system.
The document processing system here
- builds the document inverted index and the tokenspace repository.
- can be connected to various networks, such as the Internet and Intranets.
Various Configurations of Document Processing Systems
Document processing systems may be implemented in different ways in Google infrastructure. For instance, depending on the task, a document processing system may or may not include crawling, clustering or indexing modules.
Different Document Processing Systems at Google
There is not only one document processing system as document processing systems are used to perform various additional tasks, such as identifying semantics from image documents, generate classification data from a document or extracting facts from documents. Each document processing system will thus have its own configuration.
Document Processing System in the Web Crawler System
Document processing in the web crawler system is done by the content processing servers.
For the rest of this tutorial, we will focus on the document processing system used inside the information retrieval system as described in the “Multi-stage query processing system and method for use with tokenspace repository” patent.
How Google’s Document Processing System Works?
The document processing system used in information retrieval works by crawling documents, then parsing the documents into tokens and finally storing tokens into lexicons by assigning token IDs to each unique token.
Parsing the Documents
The goal of the document processing system is to turn each document of a document corpus into a list of tokens and then use linguistic preprocessing to normalize them into indexing terms (e.g. tokens).
A token is any object found in a document. Tokens can be terms, phrases, punctuations or even HTML tags.
After parsing, a set of documents is represented as a sequence of tokens, along with their position in the document.
In “Indexing the World Wide Web“, Google engineers mention some of the linguistic text processing that is generally done on documents such as:
- Stripping HTML tags
- Tokenization
- Stopword removal
- Case Conversion
- Stemming
Other patents hint that these two additional document processing steps may be added to the funnel.
- Generation of descriptive information (see: document locator)
- Attribute labelling
At this point, the tokenization may be done with the MapReduce algorithm.
Each token is assigned a token ID and the position of the token within the document.
Building the Lexicon with the Lexicon Generator
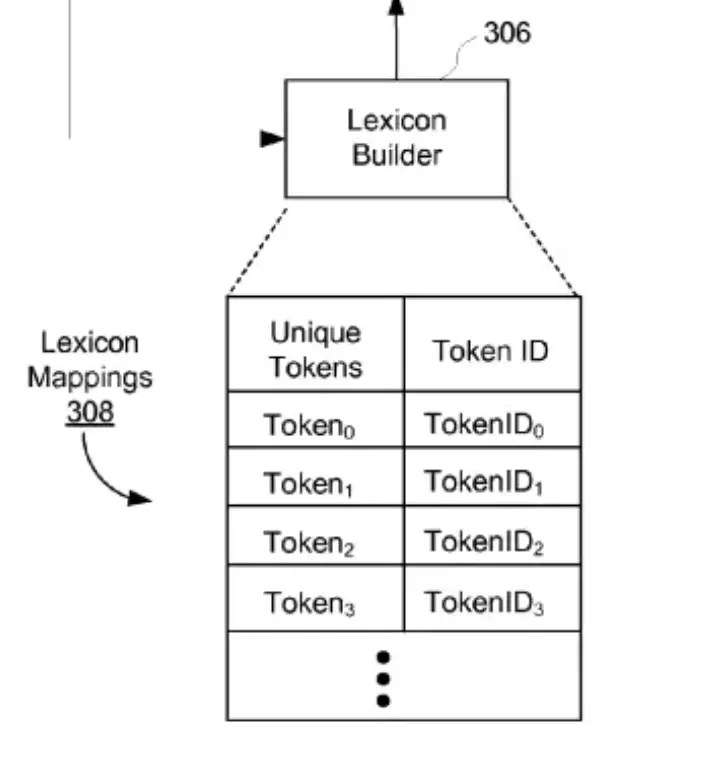
The lexicon generator, also known as the lexicon builder, is the software that generates the lexicon mappings encoding a set of parsed documents.
Here the goal of the lexicon builder is to:
- prepare the main dictionary (lexicon) of tokens,
- sort it in a way that related tokens are closer to each other,
- split it in smaller sub-dictionaries (mini-lexicons),
- generate the mappings to be able to map back smaller dictionaries to the main dictionary
- send the lexicons to be encoded and reduce their sizes
- send the compressed data to the tokenspace repository.
The lexicon generator includes a global-lexicon builder and a mini-lexicon builder. The global lexicon stores all the token, and the mini-lexicon generate mappings in groups to save some space in storage.
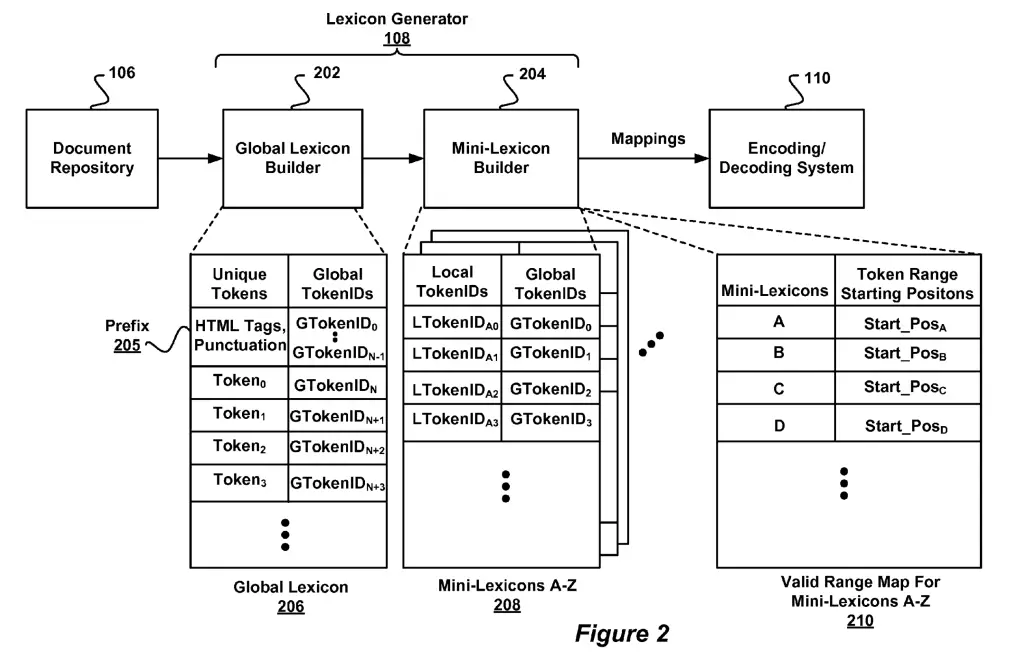
This information is sent to the query processing system that will decode the encoded tokens by matching them to the tokenspace repository.
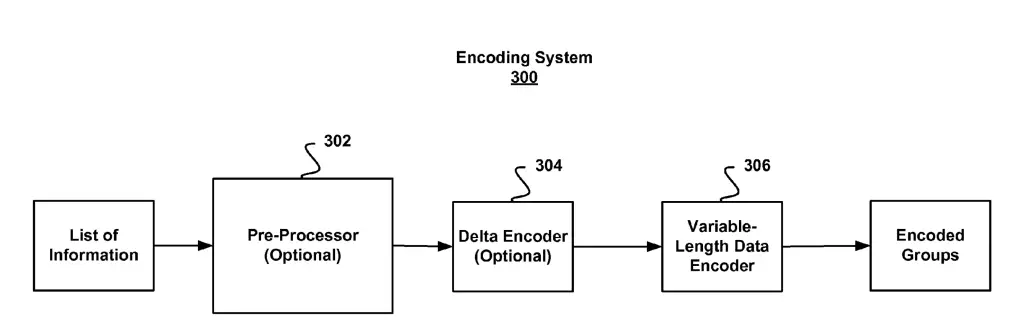
Compress the Lexicons with Encoding System
What the encoding system does essentially is that it encodes documents into compressed representations that take fewer bytes than they normally would.
The encoding and decoding systems are described in detail in the patent titled: “System and method for encoding and decoding variable-length data“.
Store the Compressed Inverted Index in the Tokenspace Repository
Which Patents Mentions the Document Processing System?
- Multi-stage query processing system and method for use with tokenspace repository
- Efficient document clustering
- Identifying the unifying subject of a set of facts
- Generating content snippets using a tokenspace repository
- Processing structured documents using convolutional neural networks
Google Parent Infrastructure Involved
Where does the Document Processing System falls into?
- Information Retrieval System
- Document Processing System
- Web Crawling System
- Document Processing System
Google Children Infrastructure Involved
Here are some of the components used inside or along with the following:
- Document Processing System
- Document repositories
- Lexicon Generator
- Encoding System
- Pre-processor,
- Delta encoder,
- Variable-length data encoder
- Decoding System
- Delta Decoder,
- Variable-length data decoder
- Tokenspace repository
The Document Processing System is often used in conjunction with the query processing system.
Definitions
| Patent term | Definition |
|---|---|
| Document Processing System | System that prepares the inverted index from documents, pages or sites retrieved from the document corpus. It processes the contents using an automated or manual process |
| Token | Any object found in a document (terms, phrases, punctuations, HTML tags). |
| Inverted Index | Data structure used by information retrieval systems that is composed of a vocabulary of terms, along with list of term occurrences and locations in documents |
| Tokenspace Repository | Tokenized collection of documents |
| Lexicon | Other name for a dictionary of terms, or vocabulary |
| Dictionary | Data structure that stores terms, or vocabulary |
| Vocabulary | Set of terms stored in a dictionary |
| Lexicon generator | Software that generates the lexicon mappings encoding a set of parsed documents |
| Lexicon Mappings | Data store for the mappings of all the unique tokens and token IDs |
| Global-Lexicon | Data store for the mappings of all unique tokens and their global token identifier in a set of document |
| Mini-Lexicon | Data store of sequences of mappings of unique tokens and their global token identifier used for encoding and decoding specific range of positions in documents. |
| Query Processing System | Any computing or processing system that can take action responsive to a query |

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.