This post is part of the complete Guide on Python for SEO
In this post, we will learn how to check the number of indexed pages on multiple websites using Python and Selenium into a CSV file.
Beware, by doing this you are going against Google guidelines on web scraping. Try not to do that at a massive scale.
And I mean it! Just read this.
How am I Extracting Indexed Pages?
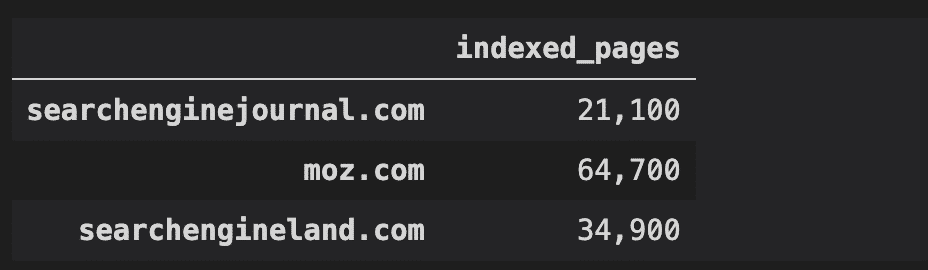
This Python script performs a site: search to check to the number of indexed pages on Google for multiple sites using Selenium and Python.
I know that this is not exact at all. But it is good enough for you to have an idea of your competitor’s index sizes when building an SEO strategy.
Python Code to Scrape Site: Search Results
The code below uses Python Pandas and selenium to scrape the results.
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
urls = [
'searchenginejournal.com',
'moz.com',
'searchengineland.com'
]
indexes = {}
xpath = '//*[@id="result-stats"]'
def get_index(url,xpath,headless=True):
'''
Run Selenium.
Get number of indexed pages.
url: full url that you want to extract
headless: define if your want to see the browser opening or not.
'''
print(f'Opening {url}')
options = Options()
options.headless = headless
driver = webdriver.Chrome(options=options)
driver.get(url)
index = driver.find_element_by_xpath(xpath).text
index = index.split('About ')[1].split(' results')[0]
print(f'Index: {index}')
driver.quit()
return index
for url in urls:
search_url = f'https://www.google.com/search?q=site%3A{url}&oq=site%3A{url}&aqs=chrome..69i57j69i58.6029j0j1&sourceid=chrome&ie=UTF-8'
index = get_index(search_url,xpath,headless=True)
indexes[url] = index
time.sleep(1)
df = pd.DataFrame.from_dict(indexes, orient='index', columns=['indexed_pages'])
df.to_csv('indexed_pages.csv')
Reactions From the Community
This post, although very simple, had a fair amount of reaction from the community (see linkedin post). Most comments were very relevant, so I decided to create this caveat section to address some of the comments.
Take the site: Operator with a grain of salt.
One of the most important comment was made by Mark Williams-Cook founder of AlsoAsked.com.
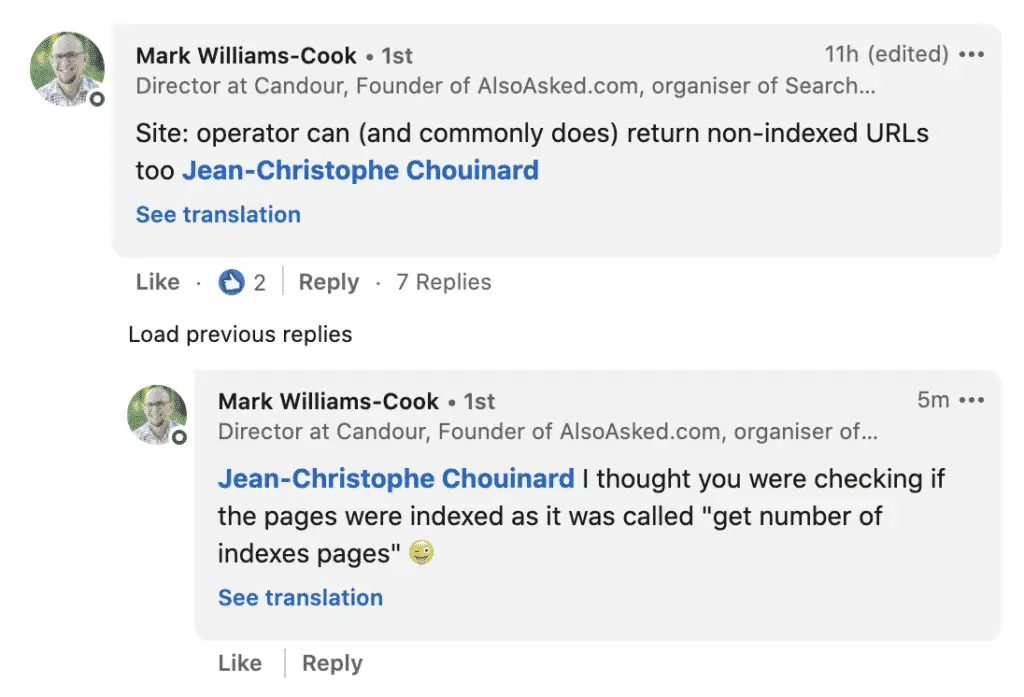
The site: search operator gives a rough estimate only. It is not reliable to make business decisions. Hence the decision to add the “(rough)” in the title of the article.
Another interesting comment by Martin McGarry, consultant at SearchAssistance.co.uk.
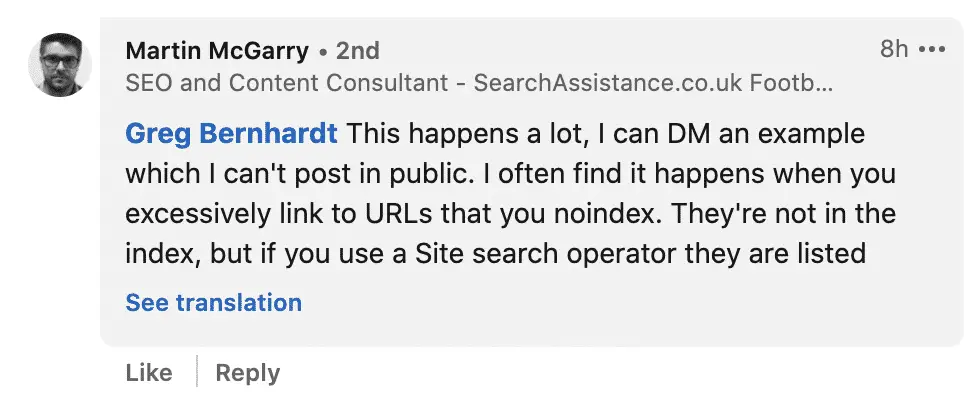
And a compelling article on searchenginejournal.com by Roger Montti. According to John Mueller:
The site: search operator can be off by a factor of ten to as high as a hundred.
Why making this script then? Because a lot of times you just want to have an idea of how committed a site is in a market. Around how many pages does the business deal with 200 or 200M.
I have learned through the years that a lot about SEO is imprecise, and trying to make it more precise sometimes makes it as blurry as the rough estimate. But Mark is right. SEO’s should know what is behind the “site:” operator and I have decided to take his side on it.
Why Not Requests?
Derek Hawkins from Reprise Digital, from whom I learned quite a bit in the past as asked me why not use requests?
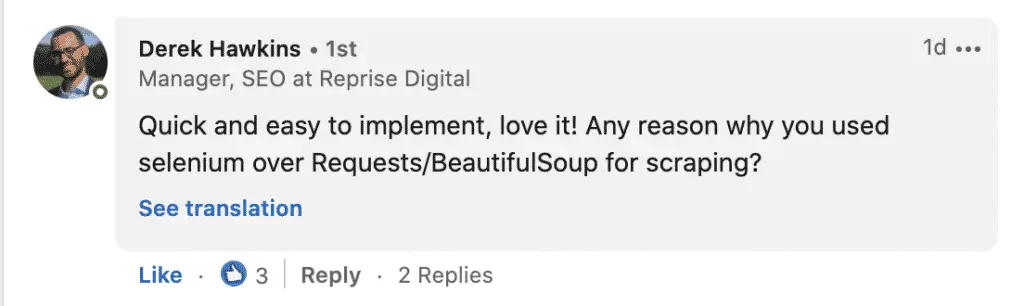
No good reason. He is right. The requests module does not use the browser. Instead, it makes simple HTTP requests which are faster and take less computing resources.
Here is the code to do it with requests.
import pandas as pd
import requests
import time
from bs4 import BeautifulSoup
urls = [
'searchenginejournal.com',
'moz.com',
'searchengineland.com'
]
indexes = {}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
def make_request(url,headers):
try:
r = requests.get(url, headers=headers)
except requests.exceptions.RequestException as e:
raise SystemExit(e)
return r
for url in urls:
search_url = f'https://www.google.com/search?q=site%3A{url}&oq=site%3A{url}&aqs=chrome..69i57j69i58.6029j0j1&sourceid=chrome&ie=UTF-8'
r = make_request(search_url,headers)
soup = BeautifulSoup(r.text, "html.parser")
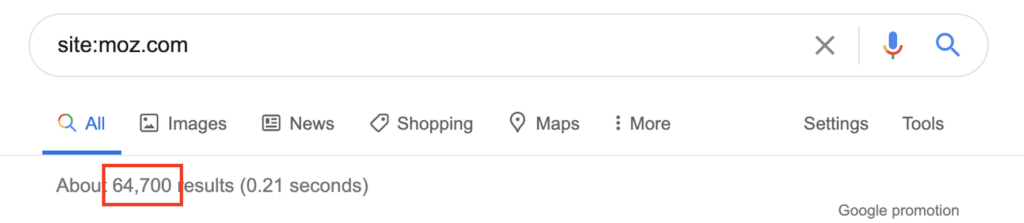
index = soup.find('div',{'id':'result-stats'}).text
index = index.split('About ')[1].split(' results')[0]
indexes[url] = index
time.sleep(1)
df = pd.DataFrame.from_dict(indexes, orient='index', columns=['indexed_pages'])
df.to_csv('indexed_pages.csv')
Avoid Bot Detection
Niall O’ Gribin was being practical. Doing this at scale, you will hit captcha’s, over and over. Or get your IP banned.
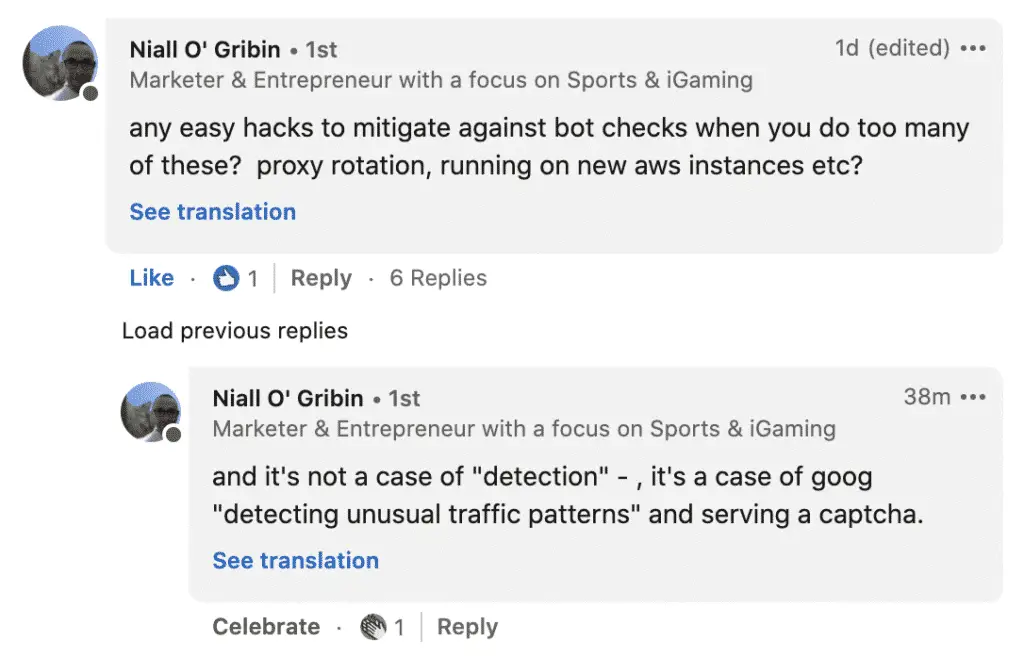
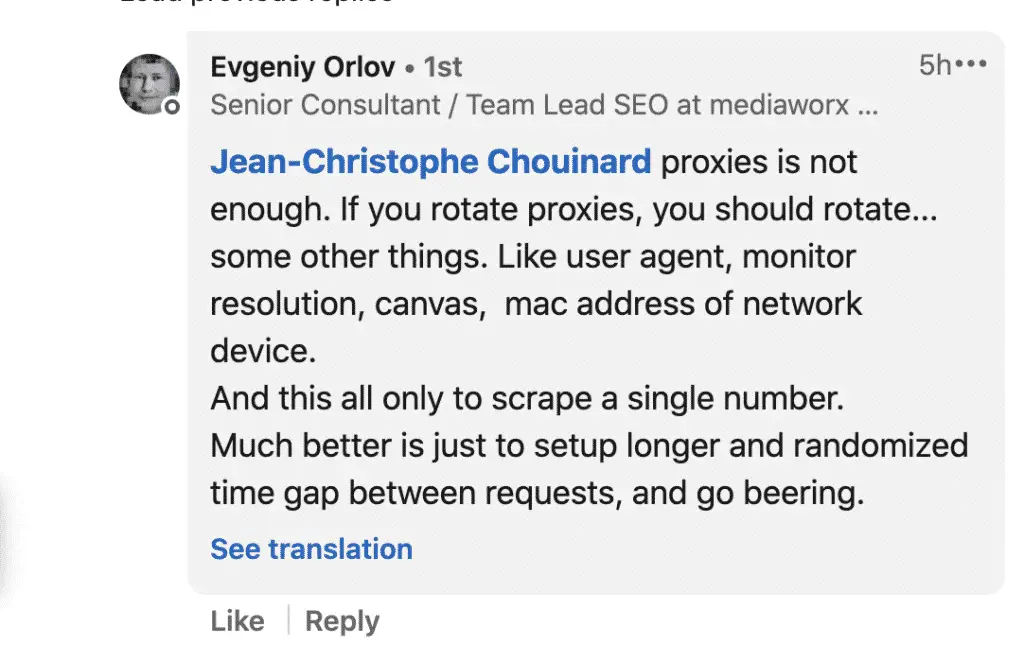
How do you avoid bots detecting these “unusual traffic patterns”?
I am not a pro in those techniques. But, here some good tutorials to help when trying to avoid bot detection.
- Evan Sangaline wrote a fantastic post using Puppeteer and avoid bot detection.
- Proxy Rotation
This is it. You now have a simple way to get the number of indexed pages for multiple sites with Python.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.