This post is part of the complete Guide on Python for SEO
This tutorial is for you that wants to crawl a website with Screaming Frog and extract more URLs from those pages to be recrawled.
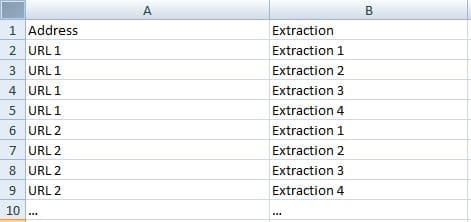
By using custom extraction, you will end up with a list of new URLs placed into columns not ready to be sent the crawler.

What you need to do is to convert the extraction columns into a database that you can send back to Screaming Frog.
It should be a built-in function, right?
But no.
It is simple to copy them manually if you have crawled 10 pages, but not if you have crawled a hundred thousand pages.
However, it is really simple to solve this using Python.
If you don’t know how to use Python, I have an entire Guide dedicated to Python for SEO.
Convert Your Extracted URLs to a Database Using Pandas
First, you need to export your crawl.

Then, we will convert your extracted URLs to a database format using Pandas.
import pandas as pd
crawl = pd.read_excel(r'C:\Users\j-c.chouinard\Python\Screaming Frog\burnabycrawl.xlsx')
#Transpose DataFrame
crawl_transposed = crawl.transpose()
#Remove duplicates in all rows
for i in range(len(crawl_transposed)):
crawl_transposed.iloc[:,i]=crawl_transposed.iloc[:,i].drop_duplicates()
#Bring back to the original row/column order
crawl_dedup=crawl_transposed.transpose()
#Remove Statuses Columns
crawl_drop=crawl_tdedup.drop(crawl_tdedup.columns[1:3],axis="columns")
#Send it to a database format
crawl_db=pd.melt(crawl_drop, id_vars='Address', value_vars=crawl_drop.iloc[:,2:], var_name='extractedUrls', value_name='Extraction').dropna()
#Write to excel
crawled_urls.to_excel("urls_to_recrawl.xlsx",index=False,header=False)
Other Technical SEO Guides With Python
- Find Rendering Problems On Large Scale Using Python + Screaming Frog
- Recrawl URLs Extracted with Screaming Frog (using Python)
- Find Keyword Cannibalization Using Google Search Console and Python
- Get BERT Score for SEO
- Web Scraping With Python and Requests-HTML
- Randomize User-Agent With Python and BeautifulSoup
- Create a Simple XML Sitemap With Python
- Web Scraping with Scrapy and Python
You now have a file that you can use to recrawl the URLs extracted from your previous crawl.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.