This post is for technical SEOs that want to understand how Googlebot renders a website.
I will help you understand what is rendering and show you in detail how chrome renders a web page as Googlebot uses evergreen Chromium renderer.
If you want to learn more, a lot of this content comes from Martin’s Splitt conference on Web Rendering Services at TechSEOBoost 2019 or this presentation at Chrome Dev Summit 2018.
You can also look at this presentation by Erik Hendriks, Software Engineer at Google to get some of the most common pitfalls of rendering.
What is Rendering?
According to Martin Splitt at Google, rendering is the process of turning (hyper)text into pixels.

In simple words, rendering consists of using a browser to run the JavaScript and “see” what the page would look like to a user.
Google uses Puppeteer (headless chrome) to read a web page in a similar way that you would by going to a URL with your browser. The difference is that Google does this without “opening” the page, but by running Puppeteer on a web server.
When does Rendering Happen?
Rendering happens after a page has been crawled, and before it is indexed
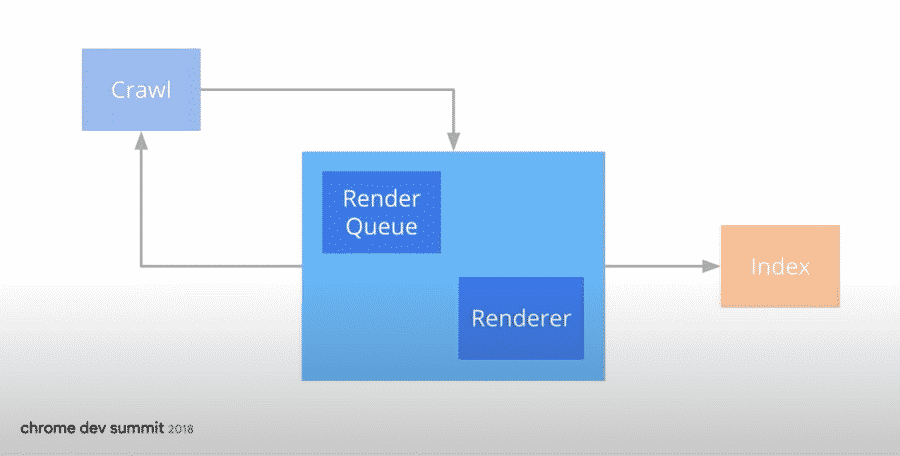
What is the Name of Google’s Rendering System?
Google’s rendering system is called Rendertron.
It is a headless chrome rendering solution built with Puppeteer that renders and serialises web pages.
How Does a Browser Display a Website to a User?
For a browser to display a web page to a user, it follows a few steps.
- Sends an HTTP Request to the server
- Parse the documents received by the server
- Create a Layout from the elements of the DOM tree.
- Paint the HTML
HTTP Request
The browser makes an HTTP Request to the server and the server sends data back to the browser.
In the case of a web page, the data sent back to the browser is HTML.
Then, the browser parses the HTML file.
and show the page to the user.
Parsing of the HTML
When a browser renders an HTML file to the user, takes each element one by one and parse it into DOM tree.
What is Parsing
Parsing means to analyze a sentence or a document into its parts. Parsing of an HTML means to analyze one by one each element of the HTML to understand their syntactic roles.
Simply put, parsing the HTML is to understand the structure of the HTML file.
How Chrome Parse the HTML File?
When Chrome Parse the HTML, it sends events to load each element into a DOM tree.
The Document Object Model, or DOM, represents the structure of the content.
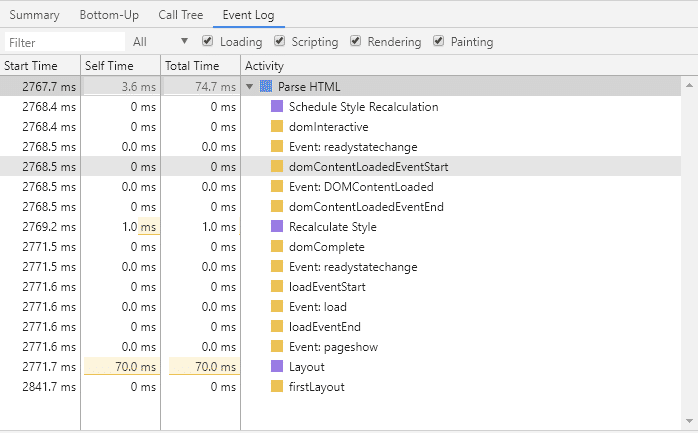
As you can see in the picture above, Chrome uses events to parse the HTML. It sends an event when the DOM starts to load, another one to load the DOM, and another one when it ends.
In the performance report, the Onload event is shown by the red line and the DOMContentLoaded Event is show by the blue line.

Note: Make sure that you load all critical content before the DCL event.
Creating the HTML Layout
After the Parsing of the HTML, Chrome knows the structure of your page (what is the H1, H2, where are your p elements, etc.)

Now, Chrome will need to get the layout of the page. It maps each element to a specific position in a browser.
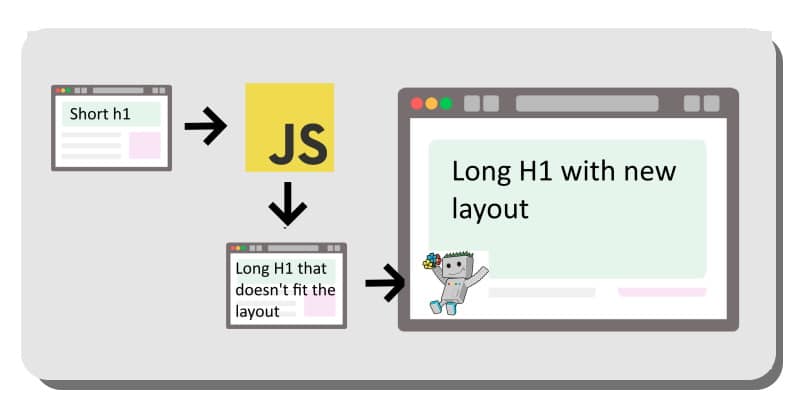
During the layout-ing, the browser is busy with the task and can’t do anything else. This is where the user has no choice but to wait.
These are the red bars that you can see in the graph.

If you continuously do layouting by moving things around in the page inefficiently, that’s a bad idea.
Martin Splitt (Google) – TechSEO Boost 2019
Painting of the HTML
Now, Chrome knows where each box goes and what content goes in each box.
Chrome will then paint the HTML tree with pixels. This is where Chrome adds the content to your page. It writes text, loads your images, adds colors, etc.
This is the step where (in Lighthouse) you start to see stuff like “First Paint”, “First Contentful Paint”, “First Meaningful Paint” and “Largest Contentful Paint” (shown by the acronyms in the image below).

The thing is, painting requires Graphical Processing Units (GPUs), which is expensive. Also, Googlebot doesn’t really need to show pixels of the page to understand our content.
The Place of JavaScript in Rendering
JavaScript can change the content of the page. Without this possibility, single-page JavaScript websites wouldn’t exist.
Javascript can add, remove or change elements from the DOM tree.
If the changes are too big to fit in the initial layout, it can force Googlebot to re-layout, which as we have seen is bad for the user.
To find out how much content is loaded via JavaScript, you can compare the HTML code when you view-source (ctrl+U) versus what you can find in the DOM (ctrl+shift+I)
Indexing Pipeline
Martin Splitt explains that the indexing process is made of many microservices that talk to each other and provide this screenshot.

- The dup eliminator processes canonicalization of pages;
- The robots parser analyses the robots.txt file;
- The crawler crawls the web by following links;
- The web rendering service
- The link parser is used by the crawler to list and “click” on all links found on the page
- The Content Parser serves to interpret the syntax of the content.
Web Rendering Service (WRS)
An amazing part of the Googler’s presentation is when he talked about the Web Rendering Service.
In this part, he talks about some cryptic developer stuff like Puppeteer, Service Wrapper and Shadow DOM (official doc).
I will not go into all the details of it.
To view shadow DOM : Open Chrome Devtools. Go to Settings > Preferences. Show user agent shadow dom.
Instead, just note these interesting points about WRS:
- The indexing pipeline calls WRS, which renders;
- WRS skips the pixels;
- WRS makes connection requests to read HTML, CSS and JS files using single connections. Each connection is what we call the “crawl budget”;
- WRS relies heavily on the cache and has certain rules to timeout if a page takes too much time to load.
- WRS is used by all testing tools (mobile-friendly test, page speed, etc.). In exception, it will have an aggressive timeout and will not cache the page.
- To render a page with Python or JavaScript, you can use the open-source Headless chromium renderer, Rendertron.
- WRS is stateless (cookies are overridden after each page load).
Other interesting features of Web Rendering Service are explained by Jamie Alberico.
- WRS is the name that represents the collective elements used in Google’s rendering service.
- WRS reads HTTP response and header;
- Googlebot’s first priority is not to degrade the user experience so it uses a “crawl rate limit”.
The end result would look something like this.


How Does Google Determine What Needs to be sent to the WRS?
When Google “looks” at a page, it checks the difference between the initial HTML and the rendered HTML. If there is a lot of additional content after the JavaScript was loaded (diff between crawled DOM and rendered DOM), it knows that the content needs to be rendered.
Batch Optimized Rendering
Rendering is expensive. To reduce the costs of rendering, Google came out with a patent (which may or may not be used).
The patent is called: Batch-optimized render and fetch architecture.
What is this service doing?
It sets-up a virtual clock to stop rendering after a while and skips resources that are not critically relevant for rendering.
From the documentation, here is what Google skips while using Batch Optimized Rendering:
- Google Analytics
- Advertising Systems
- Images
- Duplicated Embedded Objects
How Can You Improve Rendering for SEO?
A lot of stuff can help your crawl budget and the rendering of the page. Remember this, what is good for the user, Googlebot will like it.
Here are a few advises that Martin Splitt gave:
Tip #1: Make sure that DOM changes made with JavaScript don’t force Chrome to recreate the HTML layout.
Tip #2: Use Tree shaking to remove unused code
Tip #3: Use simple and clean caching by adding content caches hashes. You can do this by using Webpack.

Tip #4: Bundle your code, but split it into reasonable bundles.

This is it!
When Does Googlebot Stop Rendering
In batch optimized rendering patent, we have seen how a virtual clock might stops the rendering of a web page, which, in Martin’s words, is “ridiculously long” and should not be a concern for SEOs.
In new discussion, Martin Splitt mentions that the rendering system stops rendering “when the event loop is empty”. (Explanation starting around 26:40 mark)
What Happens with Idle Loops
Idle task such as setTimeout are set to run faster in Googlebot.

Other Useful SEO Content on Rendering
Fantastic Engineering case study on How Google handles JavaScript throughout the indexing process.
How to diagnose my site’s rendering?
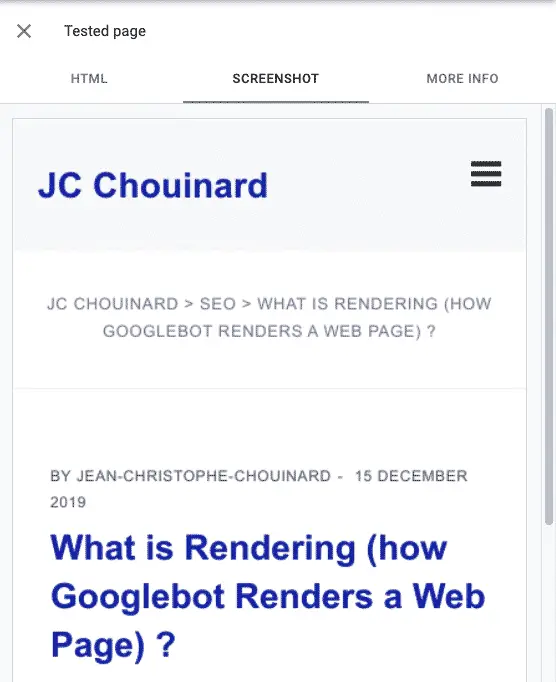
If you want to see how Google renders your website, you can use Google’s Rich Results testing tool. This will give you an idea of whether or not Google is capable of rendering your web pages properly.
Careful with APIs
If you use an API that is required to load content on the page, and that API blocks Googlebot in robots.txt, then Google won’t be able to render the page.
A very special thanks to Martin Splitt for sharing this amount of useful information on what is rendering and how Google renders a website.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.