In this tutorial, we’ll delve how to use Python to diagnose Keyword Cannibalzation, empowering you to incorporate this system into your SEO workflows effectively.
GitHub Repository: github.com/jmelm93/seo_cannibalization_analysis
Navigation
Show
This post is an improvement over the tutorial we shared a while back named Find Keyword Cannibalization Using Google Search Console.
What is SEO Keyword Cannibalization?
SEO keyword cannibalization occurs when multiple URLs on a single website satisfy the same user intent, thus making them compete with one another for the same organic keyword rankings.
It’s a common challenge in the world of search engine optimization.
For more info on the concept of keyword cannibalization, check out this post from the Ahrefs blog – Keyword Cannibalization: What It (Really) Is & How to Fix It.
Challenges of Cannibalization Analysis Techniques
While keyword cannibalization is a well-known concept in the SEO community, most techniques to identify issues have significant drawbacks.
For instance, the most commonly used method involves examining queries with multiple pages receiving clicks and impressions for a unique query. However, this approach often yields misleading results because it overlooks key factors such as the volume of traffic across pages and the significance of a particular query in driving overall traffic to the given page.
To address these challenges, I’ve developed a Python script that enhances the conventional approach with multiple layers of checks to determine if keyword cannibalization exists and if merging overlapping pages is a viable solution.
Free Keyword Cannibalization Tool
For anyone who is not comfortable with Python programming, I’ve made this process available to use for free at seoworkflows.com/tools/opportunity/keyword-cannibalization-checker.
It’s designed to be intuitive and accessible to non-technical users, allowing you to identify and address keyword cannibalization issues effortlessly.
Simplified Explanation of Python Processes
Part 1: Initial Data Processing & Cleaning in Python
In the first stage of the script, we start by cleaning and preparing the data for analysis. This helps us lay the groundwork for the SEO cannibalization analysis and sets the stage for further analysis.
Here’s what happens during this step:
- Reading Data: We read the Google Search Console (GSC) data from a CSV file.
- Removing Branded Keywords: We remove any branded keyword variations from the dataset to focus on non-branded keywords.
- Filtering Keywords: We filter the dataset to include only keywords where at least two pages are driving clicks to the same keyword target.
Part 2: Building Keyword-Level Segments
The keyword-level segments are crucial for identifying consolidation opportunities. In this part of the script, we create and use two segments:
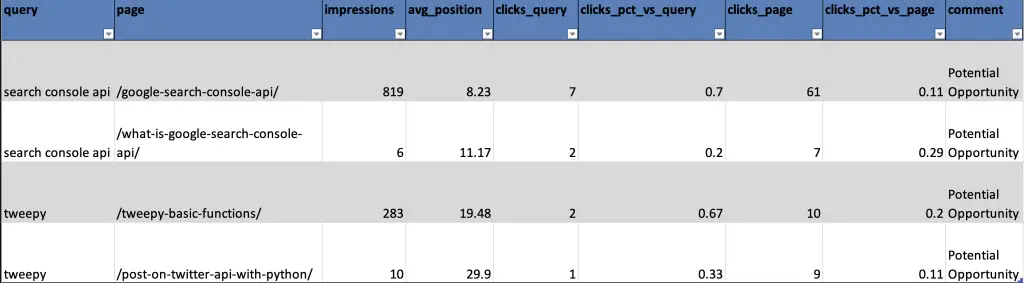
- ‘clicks_pct_vs_query‘: This segment calculates the percentage of clicks each page receives for a specific keyword.
- ‘clicks_pct_vs_page‘: This segment calculates the percentage of clicks for the main page associated with a keyword.

These segments help us determine if consolidating pages is a good idea.
They provide insights into the extent of overlap at the keyword level and help ensure that the pages are strongly influenced by the target keyword.
We also create a new column called ‘comment’, which is filled with either ‘Potential Opportunity’ or ‘Risk’ based on the following logic:
Logic: If ‘clicks_pct_vs_query‘ is greater than or equal to 10% and ‘clicks_pct_vs_page‘ is greater than or equal to 10%, then it’s marked as a ‘Potential Opportunity‘. Otherwise, it’s labeled as a ‘Risk‘.
In simpler terms, this logic tells us that if a keyword drives a significant number of clicks for both the individual keyword and the overall page, there may be a potential opportunity for consolidation.
Part 3: Final Dataset Cleanup & Builds
We take the datasets built during the initial data processing and keyword-level segmentation to identify immediate SEO opportunities and write the final datasets to our output.
Here’s what happens:
- Identifying Immediate Opportunities: To expedite SEO actions, we pinpoint “Immediate Opportunities” by selecting rows where the ‘comment’ column is marked as ‘Potential Opportunity’ and ensuring that there are at least two such rows for the same keyword. This signals a strong consolidation opportunity with reduced risk.
- Generating Final Output: The datasets are organized and sorted while the numerical metrics are rounded. The finalized datasets are then written to the final output.
Expected Outputs
The script will produce an Excel file with multiple tabs, each containing different datasets to utilize for analysis:
- ‘all_potential_opps‘: This contains the dataset created within Part 1: Initial Data Processing & Cleaning, where the dataset is filtered to all keywords that have at least 2 pages with clicks.
- ‘high_likelihood_opps‘: This lists queries with multiple pages marked as ‘Potential Opportunities’, based on the logic explained within Part 2: Building Keyword-Level Segments.
- ‘risk_qa_data‘: This provides query-level data for pages that appear in the ‘all_potential_opps‘ tab.
Step-By-Step Process to Execute Script
- Clone or download the code repository (GitHub Repository Link) to your local machine.
- Download a page-query dataset from the Google Search Console API.
- There are several ways to do this, such as using Search Analytics for Sheets or the free GSC API Data Extractor tool on SEO Workflows.
- Update the Configuration Variables at the top of the main.py file.
- Download the requirements.
- I’d recommend using a virtual environment (resource: Python Virtual Environments)
- Run `python main.py` in the project’s root directory.
Code Breakdown
Let’s dive into the individual components of the script:
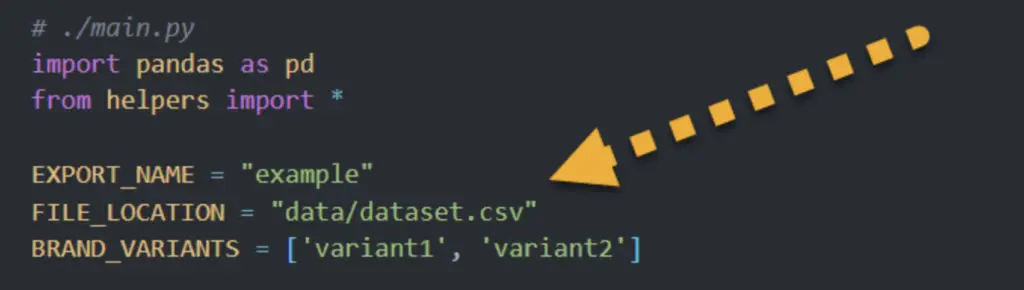
Configuration Variables
- ‘EXPORT_NAME‘: Defines the prefix for the generated output file.
- ‘FILE_LOCATION‘: The location of the page-query Google Search Console CSV.
- ‘BRAND_VARIANTS‘: List of brand name variants to exclude from the analysis.
Main Function: job
This function strings together all the above steps, sequentially processing the data and culminating in the creation of the final output dataset.
def job(file_location, brand_variants):
"""
Main function for the job.
"""
print('-- Start: Creating primary analysis df')
initial_df = pd.read_csv(file_location)
non_brand_df = initial_df
not_empty_spaces = all([brand_variant != '' for brand_variant in brand_variants])
if brand_variants and not_empty_spaces:
non_brand_df = remove_brand_queries(initial_df, brand_variants)
query_page_counts = calculate_query_page_metrics(non_brand_df)
query_counts = filter_queries_by_clicks_and_pages(query_page_counts)
wip_df = merge_and_aggregate(query_page_counts, query_counts)
wip_df = calculate_click_percentage(wip_df)
wip_df = filter_by_click_percentage(wip_df)
wip_df = merge_with_page_clicks(wip_df, initial_df)
wip_df = define_opportunity_levels(wip_df)
final_df = sort_and_finalize_output(wip_df)
print('-- End: Creating primary analysis df')
print('-- Start: Creating supporting dfs')
qa_df = create_qa_dataframe(initial_df, final_df)
immediate_opps_df = immediate_opps(final_df)
instructions_df = create_instructions_df()
print('-- End: Creating supporting dfs')
dict_of_dfs = {
"instructions": instructions_df,
"all_potential_opps": final_df,
"high_likelihood_opps": immediate_opps_df,
"risk_qa_data": qa_df
}
print('-- Start: Creating excel file')
create_excel_file(dict_of_dfs, EXPORT_NAME)
print('-- End: Creating excel file')
return "Job complete!"
Helper Functions
1. remove_brand_queries
This function excludes any search queries that contain brand variants. The ‘brand_variants’ parameter is a list of branded keywords, and these can include partial matches (e.g., the partial word “exam” could match “example”).
Python Code Snippet
def remove_brand_queries(df, brand_variants):
"""
Remove queries that contain brand variants.
"""
df = df[~df['query'].str.contains('|'.join(brand_variants))]
print("'|'.join(brand_variants)", '|'.join(brand_variants))
return df
2. calculate_query_page_metrics
This function groups and aggregates data at the page-query level, removing cases where various dimensions like “date” or “device” result in multiple instances of the same page-query combination.
Python Code Snippet
def calculate_query_page_metrics(df):
"""
Calculate metrics for each combination of "query" and "page".
"""
query_page_counts = df.groupby(['query', 'page']).agg({
'clicks': 'sum',
'impressions': 'sum',
'position': 'mean'
}).reset_index()
query_page_counts = query_page_counts.rename(columns={'position': 'avg_position'})
return query_page_counts
3. filter_queries_by_clicks_and_pages
This function takes a dataset containing query-page data, groups it by queries, and calculates the number of distinct pages and total clicks for each query.
It then filters the queries to include only those with at least two distinct pages and at least one click, returning a dataset with these refined query results.
Python Code Snippet
def filter_queries_by_clicks_and_pages(query_page_counts):
"""
Filter queries based on the click condition and distinct pages.
"""
query_counts = query_page_counts.groupby('query').agg({
'page': 'nunique',
'clicks': 'sum'
}).reset_index()
query_counts = query_counts[(query_counts['page'] >= 2) & (query_counts['clicks'] >= 1)]
return query_counts
4. merge_and_aggregate
This function combines and summarizes data from two datasets.
It first merges the ‘query_page_counts’ dataset with a filtered set of queries from ‘query_counts’, retaining only matching queries to ensure we’re only looking at keywords with 2+ pages driving clicks.
Then, it groups this merged data and provides the necessary aggregations for the available metrics for later use.
Python Code Snippet
def merge_and_aggregate(query_page_counts, query_counts):
"""
Merge metrics and join with filtered queries.
"""
df = query_page_counts.merge(query_counts[['query']], on='query', how='inner')
df = df.groupby(['page', 'query']).agg({
'clicks': 'sum',
'impressions': 'sum',
'avg_position': 'mean'
}).reset_index()
return df
5. calculate_click_percentage
This function calculates the percentage of clicks a specific page-query combination receives out of the total clicks for that query.
For instance, if Example Page A gets 10 clicks for Keyword Example A, and Keyword Example A accumulates a total of 100 clicks across all pages on the website, the data row for Example Page A/Keyword Example A will show a ‘clicks_pct_vs_query’ of 0.10, indicating 10% of the total clicks for that query.
Python Code Snippet
def calculate_click_percentage(df):
"""
Calculate percentage of clicks for each page per query.
"""
df['clicks_pct_vs_query'] = df.groupby('query')['clicks'].transform(lambda x: x / x.sum())
return df
6. filter_by_click_percentage
This function refines the dataset by selecting keywords where at least 10% of the total clicks for that keyword are distributed among at least two different pages.
The goal is to identify genuine SEO cannibalization concerns, where multiple pages compete for clicks. Therefore, keywords with a single dominant page driving most clicks are excluded from the dataset.
Python Code Snippet
def filter_by_click_percentage(df):
"""
Identify and filter by queries that meet specific conditions.
Only keep queries that have at least 2 pages with 10% or more clicks
"""
queries_to_keep = df[df['clicks_pct_vs_query'] >= 0.1].groupby('query').filter(lambda x: len(x) >= 2)['query'].unique()
df = df[df['query'].isin(queries_to_keep)]
return df
7. merge_with_page_clicks
This function combines page-level click data into the working dataset and calculates the percentage of clicks a specific page-query combination receives out of the total clicks for that page.
For instance, if Example Page A gets 10 clicks for Keyword Example A, and Example Page A accumulates a total of 500 clicks across all queries, the data row for Example Page A/Keyword Example A will show a ‘clicks_pct_vs_page’ of 0.02, indicating 2% of the total clicks.
Python Code Snippet
def merge_with_page_clicks(wip_df, initial_df):
"""
Merge with page-level click metrics and calculate percentage metrics.
"""
page_clicks = initial_df.groupby('page').agg({'clicks': 'sum'}).reset_index()
wip_df = wip_df.merge(page_clicks, on='page', how='inner')
wip_df['clicks_pct_vs_page'] = wip_df['clicks_x'] / wip_df['clicks_y']
wip_df = wip_df.rename(columns={'clicks_x': 'clicks_query', 'clicks_y': 'clicks_page'})
return wip_df
8. define_opportunity_levels
Creates a new ‘comment’ column based on the ‘clicks_pct_vs_query’ and ‘clicks_pct_vs_page’ metrics that classifies each page-query combo as either a ‘Potential Opportunity’ or a ‘Risk’.
This column is the core dimension to utilize for analysis to understand whether it makes sense to consolidate pages.
Python Code Snippet
def define_opportunity_levels(wip_df):
"""
Create 'comment' column based on 'clicks_pct_vs_query' and 'clicks_pct_vs_page'.
"""
wip_df['comment'] = np.where(
(wip_df['clicks_pct_vs_query'] >= 0.1) & (wip_df['clicks_pct_vs_page'] >= 0.1),
'Potential Opportunity',
'Risk - Low percentage of either query-level or page-level clicks'
)
return wip_df
9. immediate_opps
This function identifies and extracts “Immediate Opportunities” from the input DataFrame (final_df).
It does this by selecting rows where the ‘comment’ column is marked as ‘Potential Opportunity’ and ensures that there are at least two such rows for the same keyword.
Reason being, having at least two rows for a single keyword marked as ‘Potential Opportunity’ is an indicator of a strong consolidation opportunity with a lesser degree of risk.
Python Code Snippet
def immediate_opps(final_df):
"""
If 2+ pages for a query are marked as 'Potential Opportunity,' then return those rows as they're 'Immediate Opportunities.'
"""
return final_df[final_df['comment'] == 'Potential Opportunity'].groupby('query').filter(lambda x: len(x) >= 2)
Conclusion
In conclusion, this comprehensive script can be utilized to address the challenges associated with conventional approaches to identifying keyword cannibalization.
By enhancing the analysis with multiple layers of checks and refining the methodology, the script provides a more nuanced and accurate understanding of cannibalization issues. It empowers SEO practitioners to make informed decisions regarding keyword consolidation and optimization.
Feel free to reach out if you have any questions!

Founder of seoworkflows.com, VP of SEO at DEPT. Experienced in leading SEO teams & strategies for 100+ brands. Also skilled in database engineering & full-stack development.