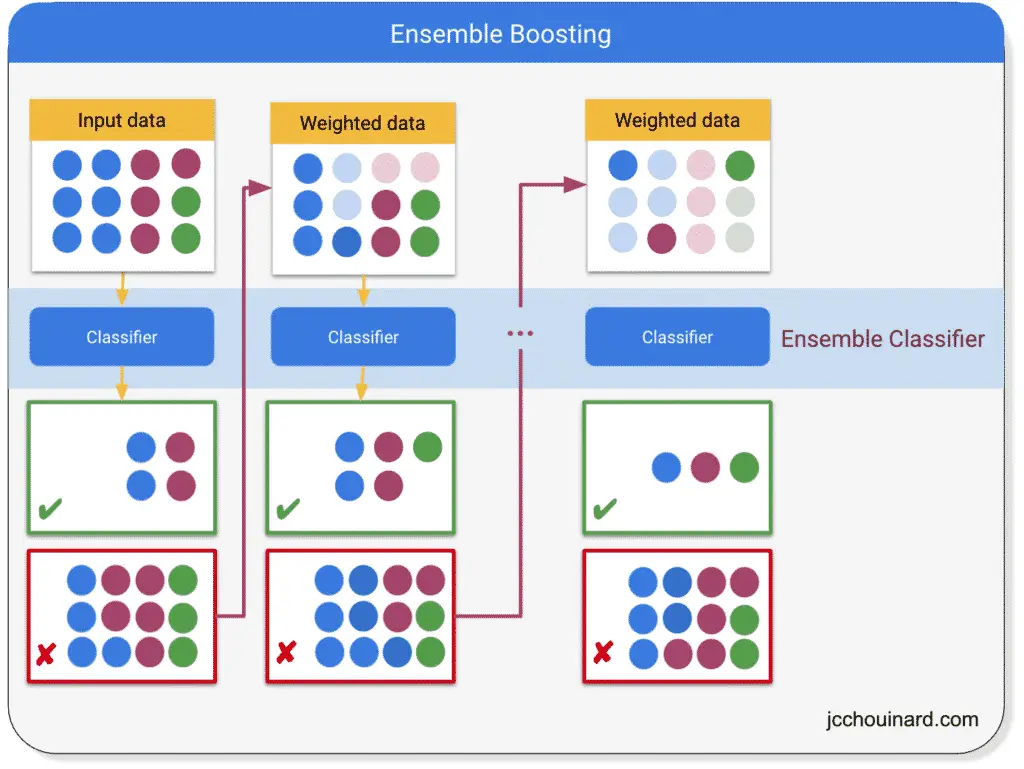
Boosting is an ensemble learning method used in supervised learning that converts weak learners into strong learners by having each predictor fix the errors of its predecessor.
Boosting can be used in classification and regression problems.
Weak Learners VS Strong Learners
A weak learner is a machine algorithm that performs slightly better than random chance.
A strong learner is a machine algorithm that can be tuned to perform arbitrarily better than random chance.

How Boosting Algorithms Work?
Boosting machine learning algorithms work sequentially by:
- Instantiating a weak learner (e.g. CART with
max_depthof 1) - Making a prediction and passing the wrong predictions to the next predictor
- Paying more and more attention at each iteration to the observations. having prediction errors
- Making new predictions until the limit is reached or a higher accuracy is achieved.
#/media/File:Ensemble_Boosting.svg){kind=link}
Multiple Types of Boosting Algorithms
There are 3 main types of boosting algorithms:
- AdaBoost
- Gradient Boosting
- XGBoost
Adaboost
Adaboost, also known as Adaptative Boosting, is a Boosting algorithm that was created for classification problems. It combines multiple weak learners into strong learners by iteratively fitting and adjusting the weights of incorrect predictions until the strongest predictor is reached.
Gradient Boosting
Gradient boosting is also a boosting algorithm that works sequentially. Each predictor is added to an ensemble correcting the errors of its predecessor. The difference between AdaBoost and Gradient boosting is that GB does not change the weights of incorrect predictions, but fits the new predictor to the residual error of its predecessor.
Gradient Boosting Algorithms:
- Gradient boosting machines (GBM)
- Gradient Boosted Regression Trees
XGBoost
XGBoost, or Extreme Gradient Boosting, is an optimized Gradient boosting library that was originally developed in C to improve speed and performance and allow parallelization.
How to Run Boosting Algorithms in Sklearn
from sklearn.ensemble import GradientBoostingClassifier # Classification
from sklearn.ensemble import GradientBoostingRegressor # Regression
# example from https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html
from sklearn.datasets import make_hastie_10_2
from sklearn.ensemble import GradientBoostingClassifier
# Generate dataset
X, y = make_hastie_10_2(random_state=0)
X_train, X_test = X[:2000], X[2000:]
y_train, y_test = y[:2000], y[2000:]
# Instantiate model
clf = GradientBoostingClassifier(
n_estimators=100,
learning_rate=1.0,
max_depth=1,
random_state=0)
# Train model
clf.fit(X_train, y_train)
# Evaluate
clf.score(X_test, y_test)
- n_estimators: Number of weak learners.
- learning_rate: Shrinks the contribution of each tree.
- max_depth: The maximum depth of the individual regression estimators.
- random_state: For reproducibility
Conclusion
This article was far from a comprehensive article on Boosting, but instead helped understand what boosting is and what type of boosting machine learning algorithms existed.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.