Job search in Google’s job search engine (also known as Google for Jobs) isn’t exactly the same as their regular search engine. In fact, Google even has a patent specific to their job search engine.
In this article, we will cover how Google For Jobs works.
Navigation
Show
In a nutshell, the search engine has four major processing steps:
- Getting Jobs for the Job Search Engine
- Processing Job titles
- Processing Job search queries
- Serving search results for the query
Did you know? Google does not only try to find job postings from employer site job listing pages, job boards, recruiting sites, aggregator, social medias, web pages … They also try to get job postings from hardcopy images
https://patentimages.storage.googleapis.com/e9/bb/9c/cb8e5fb51120ba/US20180181609A1.pdf
How Google For Jobs Finds New Jobs?
Google has defined a specific set of rules for jobs to be published in their job search engine.
They can find jobs using their normal crawling/indexing process.
But mainly, to get jobs indexed in Google for Jobs, structured data needs to be added to a webpage.
Specifically, JobPosting structured data needs to be added to each individual job.
Then, Google can discover jobs in 3 main ways:
- Regular crawling of links on the web
- XML sitemaps
- Indexing API
Basics of Google’s Job Search Engine
In a patent named “Search Engine“, Google explains the technology that may be used to match a search query to job search results.
In a nutshell, Google processes both search queries and job titles to match them to occupations. Then, the search is performed using the occupation (not the query), thus allowing the job title not to contain a word from the search query but still match the meaning.
How does Google Rank Job Postings for a Search Query?
Now that both job titles and search queries are being assigned one or more occupations, Google will show results for a user search.
- Job postings are matched to 1 or more occupations
- User searches for a job
- The query is matched to 1 or more occupations
- The occupations are used to perform the search in the job posting index. *
- Search results are filtered based on filters and other possible factors such as commute tolerance
* In some cases, search results may come from both the occupation and the search query
In these situations, the job posting results coming from the occupation search will rank higher than the result from the query search
How Google’s Job Search Engine Processes Job Titles?
First, before showing jobs to the user, Google tries to identify which job title belongs to which occupation. This allows Google to show “Software Developer” jobs to users that are searching for “ICT Programmer” jobs even though none of the terms are matching.
Below is an overview of the matching process that we will cover in greater detail later:
- Employer add
jobpostingstructured data to their site - Google crawls these job and find job detail pages in a structured way.
- The job titles are normalised to remove specific paterns from the titles.
- A subset of all the normalised titles is defined. This is called a training set.
- For each element of the training set, an occupation label is manually assigned
- Using the training set, occupation vectors are generated where multiple job titles can be grouped in a single occupation.
- Each occupation vector is assigned an occupation along with a confidence score
How Google for Jobs Processes Job Search Queries?
Second, a similar process needs to be done on the search query’s side. With our example above, Google needs to map the search query “ICT Programmer” to the “Software Developer” occupation.
The steps for job query processing are very similar to the one for job title processing:
- Get a subset of search queries from search logs (training data)
- Normalise the search queries of each element in training data
- For each element of the training set, generate a query vector
- For each query vector, the similarity engine looks at the similarity between query vector and occupation vectors
- A confidence score is generated by analyzing the distance between the query vector and the occupation vector and returning a probability of the query vector to be correctly classified in the right occupation
- The similarity engine can then decide to classify the query vector in the occupation with either the highest confidence score or in all the occupations that satisfy a threshold.
- Then the query vector is assigned one or more occupations along with a confidence score
How Google Classifies Portions of a Job Posting?
The patent named Systems and methods to improve job posting structure and presentation gives insights into how Google tries to classify potions of a job posting into informative sections.
Portions of a Job Postings that Google tries to Identify
The sections mentioned in the patent on job posting structure are:
- Job description
- Requirements (years of experiences, …)
- Responsibilities
- Hiring company
- Benefits
- Others (catch-all category that include things like “environment”)
In another patent, “System for De-Duplicating Job Postings“, Google identifies additional portions being identified on a job posting:
- Job identifier
- Job title
- Job location
- Job description
- Shift/schedule information
- Department/practice information
- Salary
- Employment type
- Entity (company name)
How the Sections are Separated?
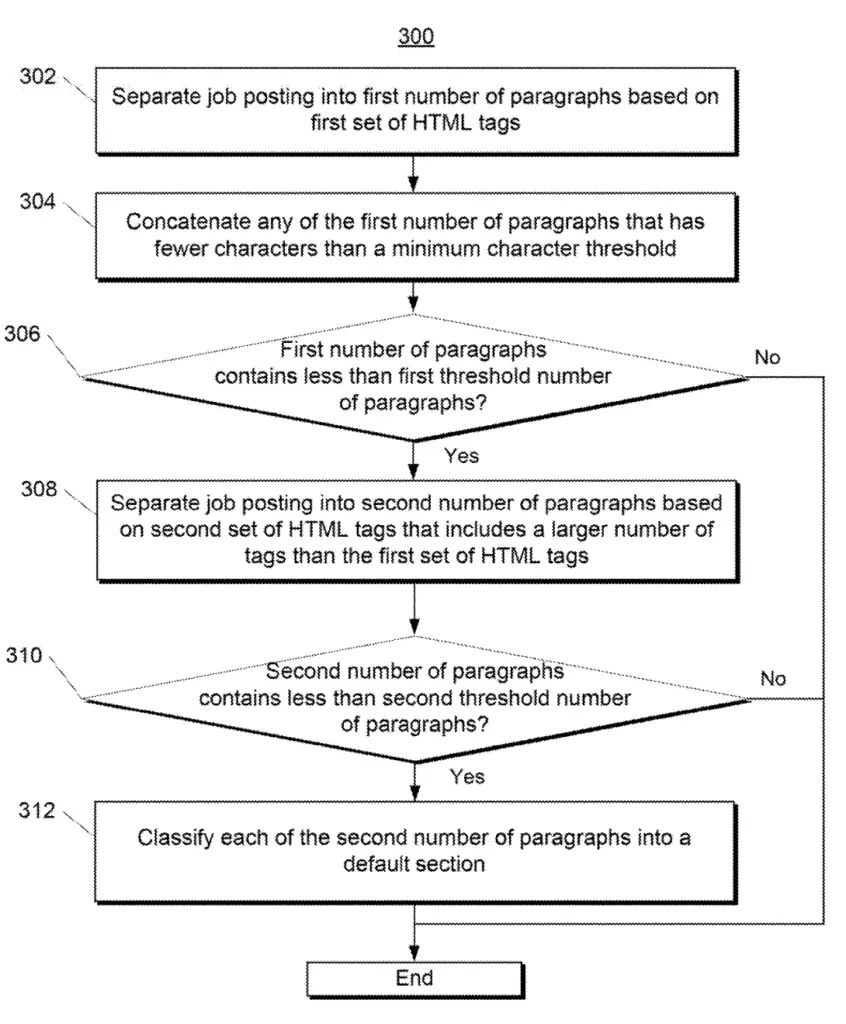
- Separate job postings in paragraphs using a first set of HTML tags (
<ul>,<li>, …). - Remove HTML tags to extract only the text
- Remove empty paragraphs
- Concatenate very small paragraphs (threshold)
- If there are not enough paragraphs, the method ends
- If there are enough paragraphs, paragraphs are further split using additional HTML tags
Why Google Split Job Postings in Sections?
The patent uses a machine-learning classification model to add labels to certain portions of a job posting. The labels may be used to:
- Modify the structure of the job posting
- Provide better snippets to the user
- Penalize job postings missing important sections
- Giving more weigth to keywords matching certain sections than others
- Extracting important features from the job
- Improving classification of job postings
Machine learning methods can include neural networks, support vector machines, logistic regression and other classification models.
Modifying the structure of the job posting
This was originally intended for modifying job postings (add headings, change colours of sections, reordering, …) to make them more appealing to the user.
Providing better snippets to the user
More likely, however, Google may use the job posting structure to improve the snippets of the job postings.
For example, if a user often searches for job posting benefits (e.g. Sales jobs with salaries), then Google can customize snippets to focus on showing those benefits.
Moreover, if a specific section is of higher importance, the size of the snippets showing that section may be increased compared to other sections.
Penalizing job Postings
Now, jumping into the most interesting piece of the patent.
The system can penalize a job posting that is missing significant sections:

Weighing Matching Queries
The classification can be used to give different weights for matching keywords depending on the section with which it matches.
For instance, matching keywords from the company section may weigh less than the one’s matching with requirements.

Extracting Features
This patent also mentions the extraction of features from a job posting. The mentioned features are:
- Skills
- Years of experience required
- Company description
Improving the Classification of Job Postings
Classifying portions of a job posting allow improving the classification of the job posting itself.
For instance, the “benefits” section tend to be similar across all job postings. Thus, using “benefits” for classification adds “noise” that can lead to wrongful classification (false positives).
Hence, portions can be weighted in a way that they impact more, or less, or not at all, the classification of the job posting into a job category.
How each Section is Understood by Google?
Typically, Google is computing TF-IDF score for each section of the page to generate vectors that represent each section.
First, each section is tokenized using anything other than letters, digits and underscores.
Second, the frequencies of each token are computed.
Third, a TF-IDF map is calculated returning something like:
{
"python":1.234,
"java":1.123,
"development":1.018,
...
}
Next, each TF-IDF score is normalized.
Then, using regression coefficients, each portion is attributed a probability of being in a section.
[
("Requirements", 1.0),
("Responsibility and Desc", 0.043),
("Benefits", 0.03),
("Company", 0.007),
("Other", 0.004)
]
Subsequently, if the probability is above a certain threshold, the portion of the job posting is assigned to the section with the highest probability. Otherwise, it is classified as “other”.
Finally, to make sure that the job posting is not split into too granular portions, the classification is “smoothed” by comparing the portion against the portions before and after. If they have a high probability of being about the same sections, they are combined together in the same section.
De-Duplication at Google
De-Duplication using the Similarity Engine
In the context of the job search engine, the similarity engine is used to compare the similarity between vectors.
The similarity engine can be used in many different ways:
- Check the similarity between a query vector and an occupation vector
- Check if sites are duplicates from one another (mirror sites)
- Check similarity of documents based on a list of links in them
- Exclude search results that have too similar snippets for a search query
- Check the similarity between two words or phrases
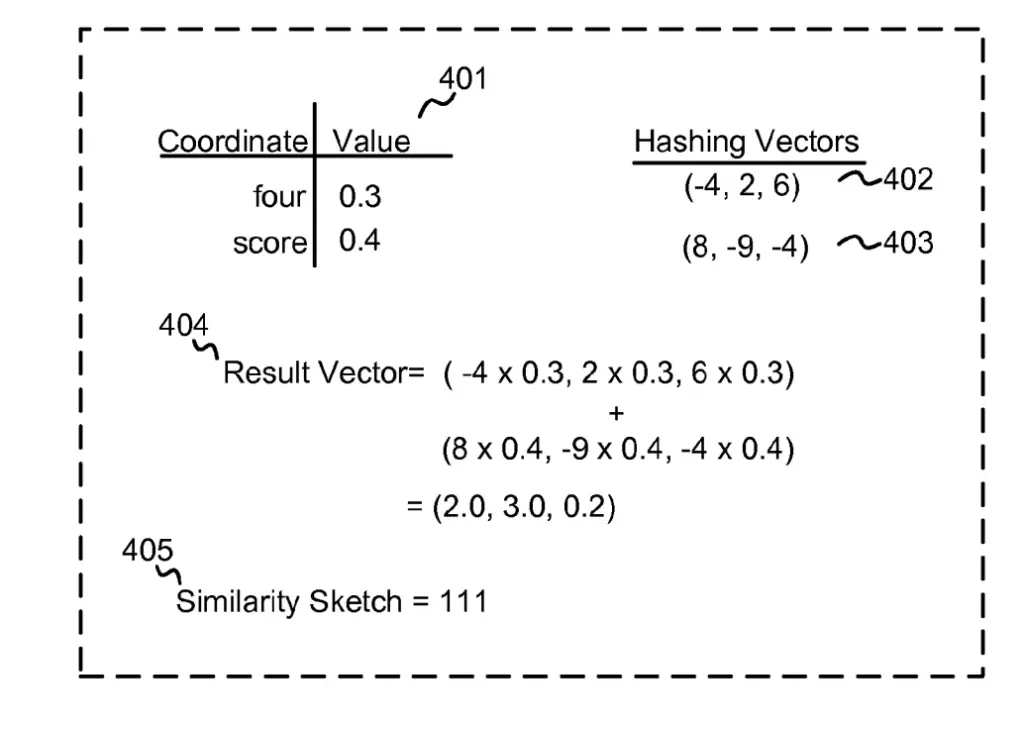
How the similarity engine works:
- Creates a vector from text (401 in example). Vectors can be query vectors or occupation vectors
- Multiply each weight in a vector by a predetermined hashing vector. The values of the hashing vectors (402 and 403 in the example) are chosen at random, as long as the same input provides the same hashing.
- Sums the hashing vector to convert in result vector
- Converts to 0s and 1s using the positive or negative value of each element. 3 positive values would equal “111” (see example below). If the hashing vector had 64 values, the result would be a 64 bit hash.
- Compare two similarity sketch through exclusive OR logical operation on complement individual bits. The similarity engine the sums the output to get a result ranging from 0 (not similar) to 64 (very similar).
Example of Exclusive OR logical operation.
How Google Identifies Duplicate Job Postings?
You may have noticed that when showing a job, Google’s job search engine returns multiple sites sharing that job. This implies that they have a technology to identify duplicate job postings.
Google has a patent called “System for De-Duplicating Job Postings” in which they explain the technology that may be used behind this feature.
What can be considered a duplicate Job Posting?
A duplicate job posting can be a job posting that:
- Was previously posted on a website
- Is posted multiple times on a website
- Is posted on multiple websites
Why Deduplicating is Important for Google?
There are a number of reasons why Google wants to remove duplicated job postings:
- Reducing computational storage by archiving duplicates
- Showing the best version of all duplicate job postings
- Showing fewer job postings and reducing clutter for the users
- Improving page load time and reducing processing resources
- Reducing number of user interactions required before application (clicks, searches, …)
- Improving efficiency, reducing bandwidth and ultimately reducing the environmental cost of searches
How it is Done
- Access a job posting cluster that contains multiple historical duplicate job postings
- From the cluster, identify a master job posting to be compared against based on time, source and other factors. For instance, job postings from an employer site may be prioritised as the master over the potentially altered version from a job board. The master allows efficiency by removing the need to compare a job against all jobs in the cluster
- Identify sections (or characteristics of the job posting)
- Based on 1 or more characteristics, identify if the job is duplicated through shingling and Jaccard similarity
- If it is duplicate, add to job posting cluster
- If not, create a new job posting cluster. Possibly assign the job as the master job posting.
It is possible that there are multiple candidates’ job posting clusters. For example, two candidate clusters can have the same job title and location of the new job posting, in this case, additional information like salary and shift schedule can be considered.
De-Duplication Data Processing Pipeline
De-duplication can get really confusing as there are many moving parts. Here is a graph shared in Google’s patent showing the job posting de-duplication pipeline.
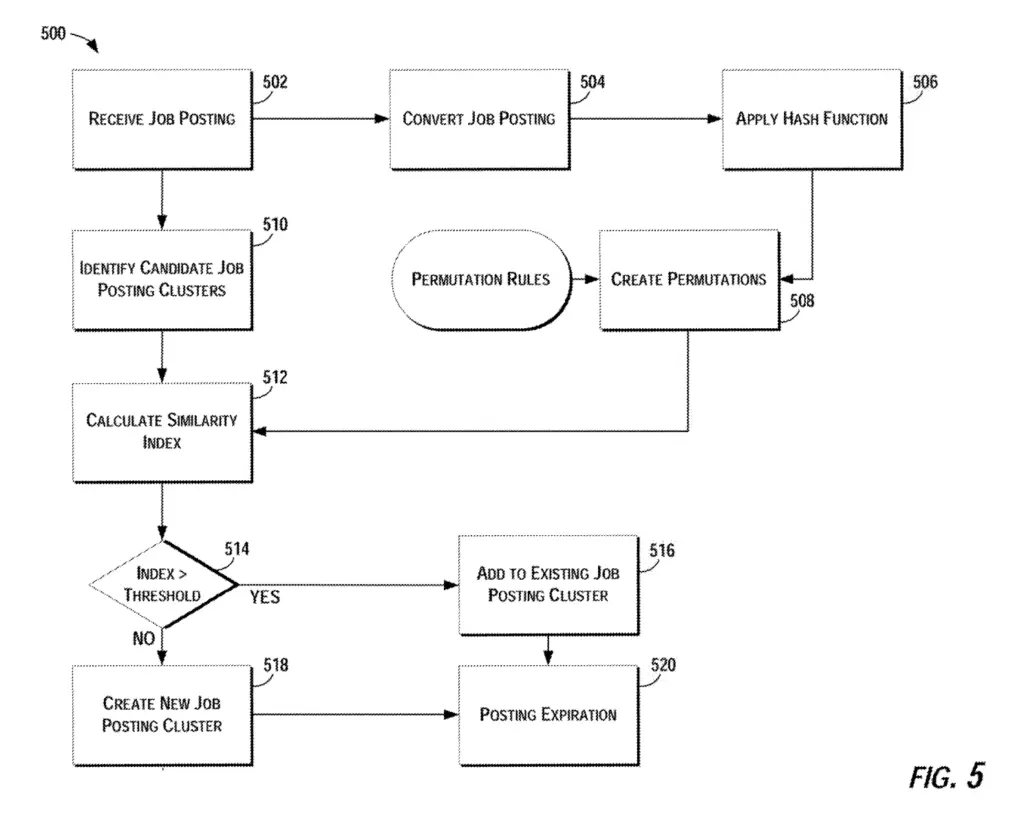
Here are additional information to make better sense of the process of duplication removal.
- Crawl and store job posting
- Extract and store the information in the job posting
- Parse, tokenize and shingle the job posting for deduplication
- Find 1 or more candidate job posting clusters
- Potentially, pass job posting against master job posting through similarity engine (not mentioned in patent but the steps are similar: Hashing/shingling using MD5, XOR permutations)
- Create a similarity index using Jaccard Similarity where 0 means that none of the corresponding minhash values are the same and 1 means that all the minhashes are the same.
- Classify as duplicate or not depending of whether or not the similarity index is above a certain threshold
- Additionally, or alternatively, calculate the longuest common subsequence (LCS) in the job descriptions. If above threshold pecentage, define as duplicate.
- If not duplicate, repeat 5-7 for the next candidate cluster, if not duplicate, create new cluster
- If duplicated, job is assigned to a cluster
- Inform third party of duplicated state of a job (job aggregator) – Not sure what that means.
What Happens When a Job Posting Expires?
Google can determine whether or not a job posting has expired based on:
- the
validThroughstructured data object, - the time or date associated with the job posting
When that happens, the job posting can be temporarily or permanently removed from its job posting cluster and/or removed as a master job posting.
How Google Determines Commute Tolerance and How it Impacts SEO?
Google has a patent named “Determining Commute Tolerance Areas” from 2018, where Google explains how it estimates the commute tolerance of users based on their profile, the location of the job and transportation data.
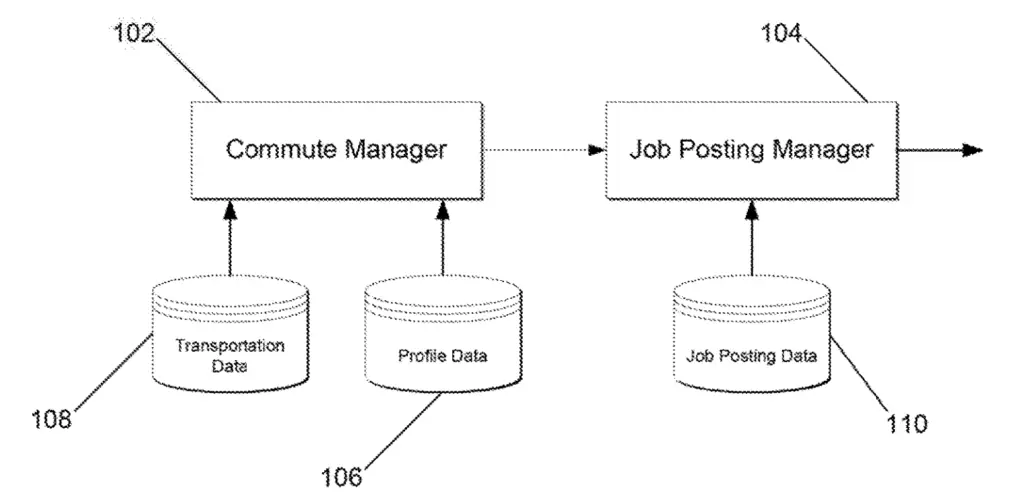
The gist of how it works is to determine:
- The origin location based on profile data (commute manager)
- The destination location based on the information of the job posting (Job posting manager)
- The frequently traveled commute of users in the geographic areas using origin and the destination (commute manager)
When Google receives a search query, it is determined if it is a job search query, and then multiple computing devices are used to gather user profile, geographical area and transportation data.
What the Commute Manager Does
The commute manager tries to evaluate the frequently travelled commute based on things like the user’s origin location (user’s residence) and user’s place employment, place of education, etc. This implies the use of some of the data from Google maps profiles.
Essentially, the commute manager will:
- Gather user’s location from profile
- Gather latest employment and/or education location
- Determine frequently traveled commute
To estimate the commute tolerance, the commute manager can use the most recently held job compared to the user’s location.
The user’s location and destination granularity can vary. One user’s address can be as granular as the full street address and the other, a general area like a city. They are also given a confidence score.
The confidence score depends on:
- Time when the pofile data was created,
- Trustworthiness of the source
Then, the commute manager
How is the Profile Data Gathered
The profile data can be gathered from:
- social media profiles,
- professional network profile,
- resume,
- work history,
- job search site profile,
- job aggregator profile.
How Google Interpret Searches with Filters and Radius?
In the patent called Job search in a geo-spatial environment, Google explains how a job search is performed when filters are used.
It is unclear how this patent could be used in search. From personal knowledge, I believe it is related to “hire by Google” that does not exist anymore.
Still, we will still explain a little bit of it here and show how I think it can be used.
In Google For Jobs, more filters are available than in regular search.
For instance, below you can choose a location and radius parameters, as well as many other types of filters to enhance your search.

If location or radius is provided, the employers or job postings within the radius will be shown, and the rest will be filtered. If the employer’s profile has a radius that overlaps with the job seekers’ radius, it is shown.
If location or radius is not provided, the location may be inferred from the user’s job searcher’s profile.
This is where it gets confusing. In the patent, Google gives hints of what they think is the important information in a job searcher’s profile and an employer’s profile.
But, as you will see, they mention in “employer profiles” some information that Google doesn’t have access to, and can’t possibly know, such as their “Candidate Preferences”. This is why I was talking about “Hire by Google” where they could’ve had access to that information.
Job Seeker’s Profile
This is how Google defines the Job Searcher’s profile:
- Name,
- Location,
- Education,
- Experience,
- Resume,
- Cover Letter,
- Employment Preferences
Employer’s Profile
This is how Google defines the employer’s profile:
- Employer Name,
- Location,
- Education,
- Experience,
- Job Title,
- Job Description,
- Compensation,
- Employer Description,
- Candidate Preferences
Google Patents Related to the Job Industry
Job Search Engine Using Occupation Vectors
Determining Commute Tolerance Areas
Job search in a geo-spatial environment
System for De-duplicating Job Postings
Identifying and Suggesting Companies With Employment Opportunities Within a Social Network
Systems and methods to improve job posting structure and presentation
Method and apparatus for learning a probabilistic generative model for text
Ranking documents based on a location sensitivity factor
Identification of implicitly local queries
Industry-Specific Resources
Generating a Machine-Learned Model for Scoring Skills Based on Feedback from Job Posters – Linkedin
Towards a Job Title Classification System
Did Indeed Hide Your Job Postings? Deduplication Explained

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.