How does Google know if two documents are duplicate when portions of the document change at a high rate? The patent titled “Updating search engine document index based on calculated age of changed portions in a document” by Joachim Kupke and Jeff Cox sheds light on this question.
In this post, I will cover how Google may improve duplicate identification by calculating the age of portions of documents.
Google faces many challenges when dealing with duplicate content. One of these challenges is handling documents where some portions change at a very high-frequency (e.g. advertisement that change each day).
Navigation
Show
What is the Patent About?
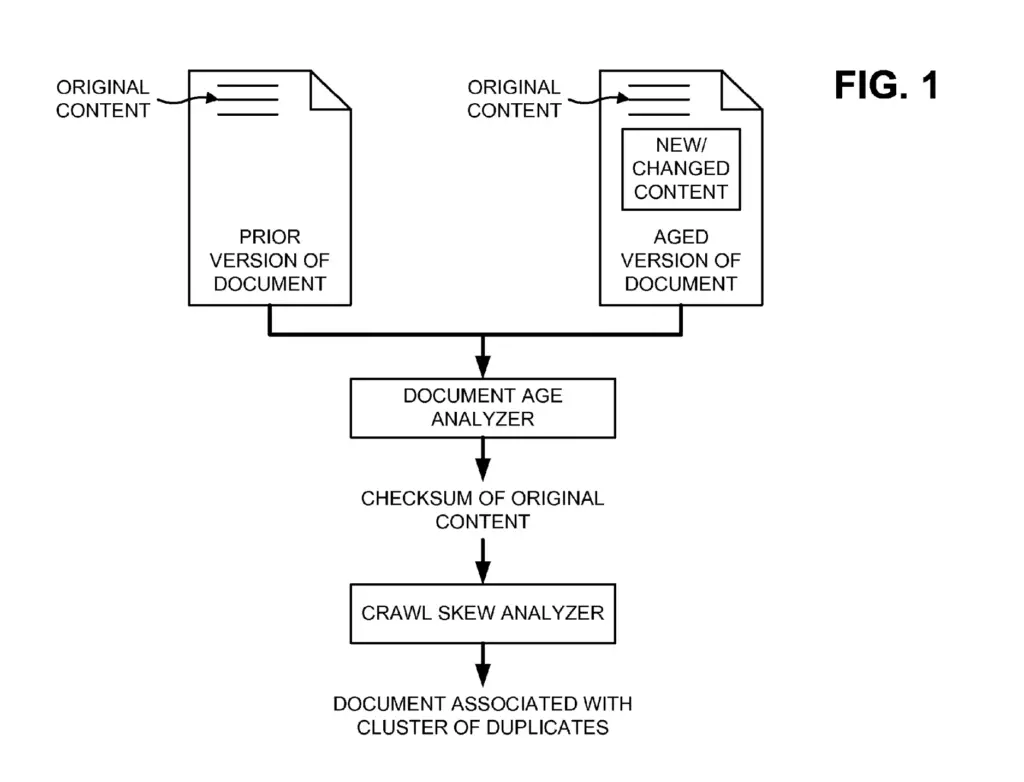
This patent shows how Google’s Indexing System tries to identify duplicate documents or versions of documents by comparing the age of new content and storing the calculated checksum.
The innovation this patent brings is that Google can calculate the age of a portion of a document in order to keep duplicate documents that experience crawl skew in the same duplicate clusters.
Highlights From Updating Index Based on Changes Age
- Google may exclude new content from the calculation of duplication (checksum).
- Even if Google finds new content, it may not send it to be indexed (ads).
Challenges that Indexers Face
Google’s Indexing Engine faces many challenges when indexing the Web.
- Handling duplicate documents
- High-frequency changes of the same document
- Crawl skew
Handling Duplicate Documents
Indexing duplicate documents wastes space in the index, slow down retrieval speed, and may be detrimental to user experience.
Thus, Google invests massive efforts in removing duplicates at all stages of search (crawling, indexing, serving).
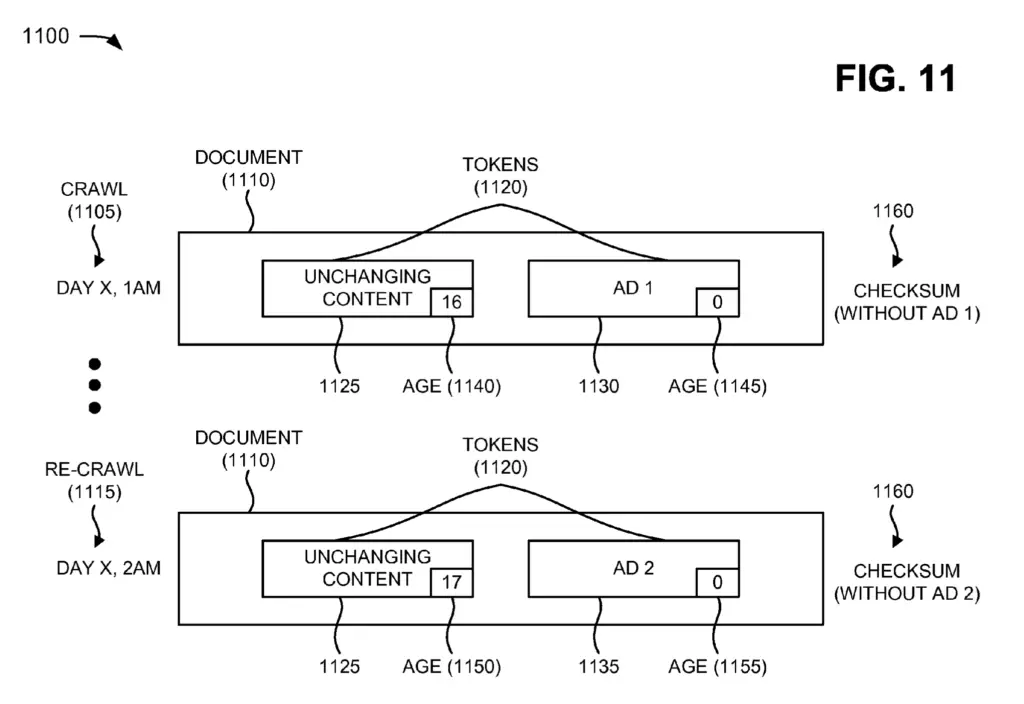
Frequency of Document Changes
Some documents have content that change at a high frequency (e.g. Advertisements, social media feeds, job feeds, etc.). Some other parts of the document may not change at all over time.
For these fast-changing sections, whenever Googlebot crawls the document, the entire content changes, almost every time.
These elements make it hard to properly evaluate the freshness of the content. The indexer may evaluate the documents with advertisements as being two different versions of the document.
This error may trigger re-indexing of the content even though the main content has not changed at all.
Crawl Skew
The crawl skew is Google’s inability to compare two fast-changing documents accurately because of delay between crawls.
Two duplicate documents may be crawled at various points in time. The duplicate documents may have been added new content between crawls.
The issue that it brings is that Google’s Indexing System may index duplicate documents “thinking” they are different.
Comparing Documents at Google
When comparing two documents, Google may use the document age analyzer to calculate a checksum between documents (or portions of) and then use a crawl skew analyzer to group duplicate pages into clusters.
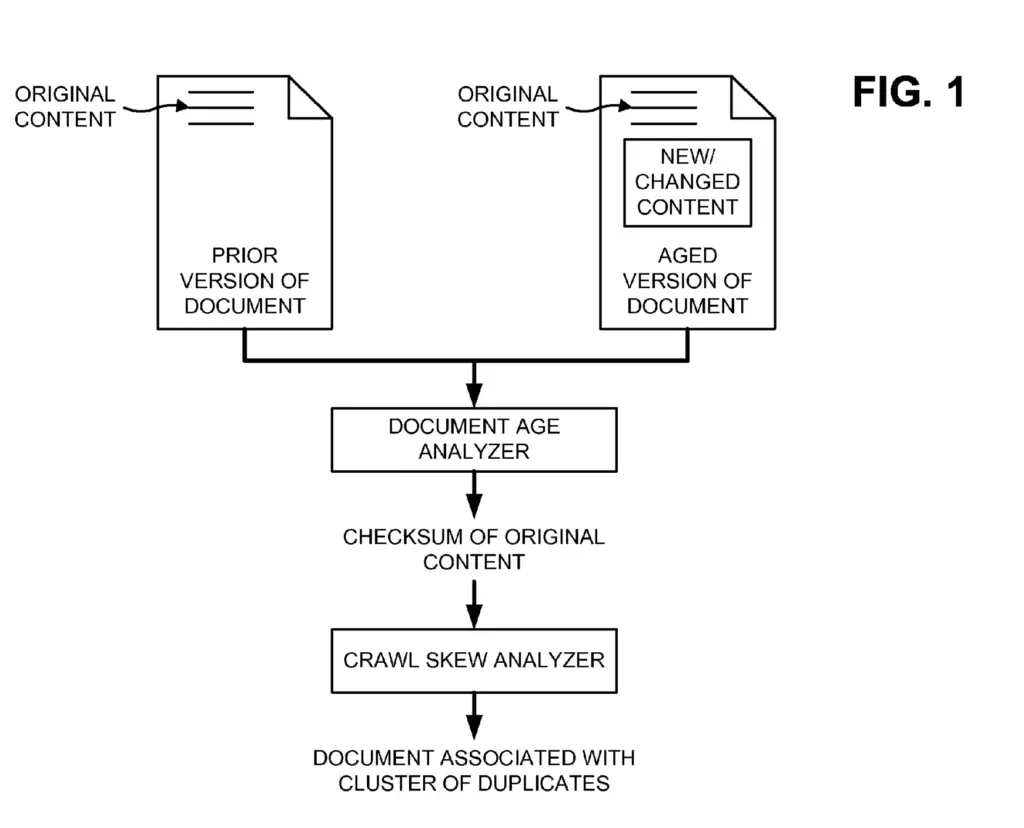
Document Age Analyzer
The document age analyzer is the technology used to analyze the prior and the aged versions of a document or portions of it.
The document age analyzer addresses the problem of indexing duplicate content because of the high frequency of change of some portions by only comparing aged portions of documents.
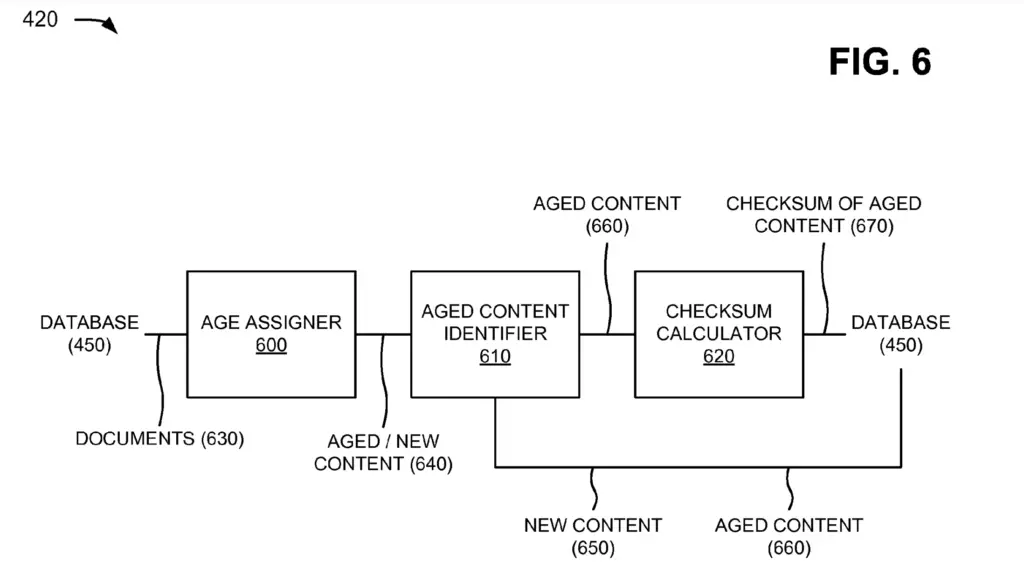
Various components are used within the document age analyzer:
- Content Age Assigner
- Aged Content Identifier
- Checksum Calculator
1. Content Age Assigner
The content age assigner tries to determine the age of portions of documents.
To do so, it retrieves and analyzes the information associated with documents from a database:
- Address
- Content
- Refresh meta tag
- Refresh header
- Status code
- Crawl time
It compares the age of the document from the current crawl and compare with versions from prior crawls of the document.
From the comparison, it identifies which portions of the document have not changed (e.g. have aged) and which are new (or have changed).
To identify portions, a document first has to be tokenized in sequences of characters, words or phrases.
The aged/new content is identified using either a a longest common Subsequence (LCS) process or a winnowing process.
It provides the information to the aged content identifier.
2. Aged Content Identifier
The aged content identifier splits aged and new content and decides which and where to send them.
- Aged content is sent to the checksum calculator.
- Relevant new content is sent to the indexing engine
Not all new content is sent to the indexing engine.
For example, advertisements may not be sent to the indexing engine.
Thus, the aged content identifier decides what new content should be indexed and sends the indexation request to the indexing engine.
3. Checksum Calculator
The checksum calculator receives aged content from the aged content identifier and calculate a checksum.
A checksum is a number that is calculated based on the data held in a file.
A checksum can represent a file (or other data structures) as a fixed length value based on the sum of the contents of the file (such as the sum of the bytes in the file).

To calculate the checksum, each letter of the aged content is converted to bytes. Bytes are summed to get a fixed number.
The checksum is added to a database.
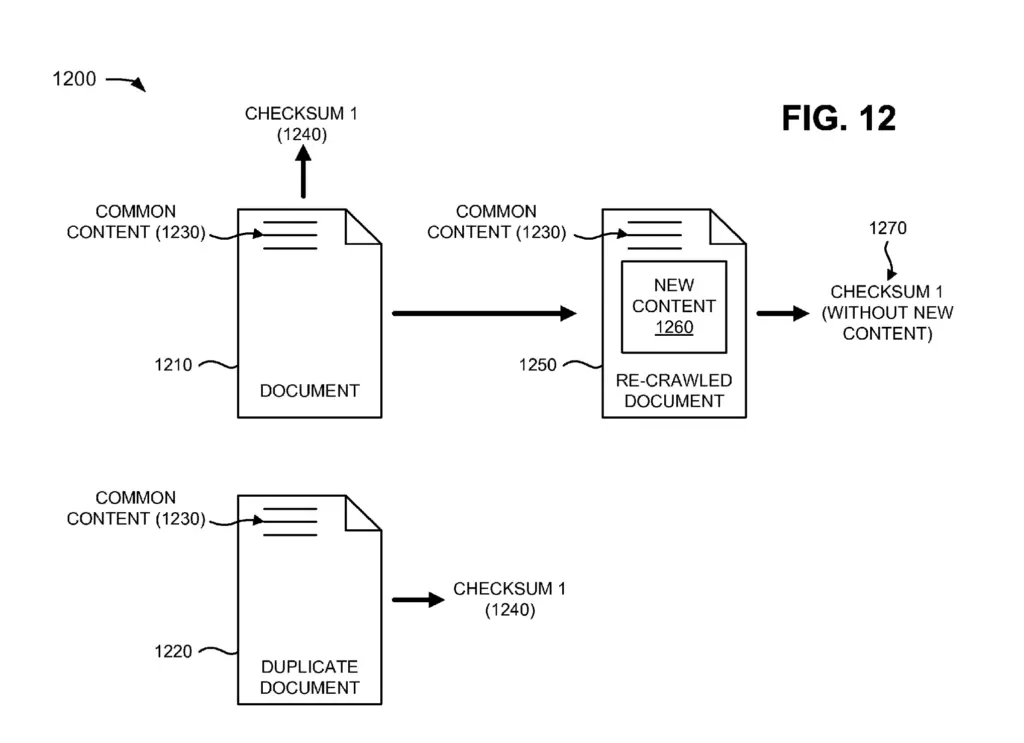
In the image below, all the ads (in red) would be considered new content and only the portion in green would be considered aged content. Thus, checksum would only be calculated on the aged (in green) portion of the page.
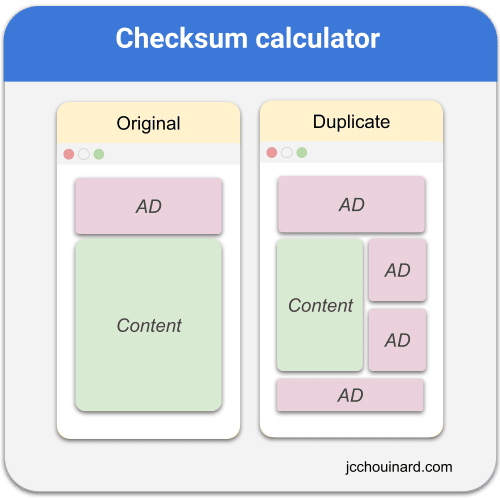
Because the checksum is only calculated on the aged portion of documents, documents with high frequency of change (containing ads) may be clustered together in a duplicate content cluster.
Without this technique, crawlers may miss that both documents of the above example are duplicates.
Crawl Skew Analyzer
The crawl skew analyzer associates the aged version of the document with a cluster of duplicate documents using its checksum.
The crawl skew analyzer addresses the problem of crawl skew by implementing a “checksum ownership” process.
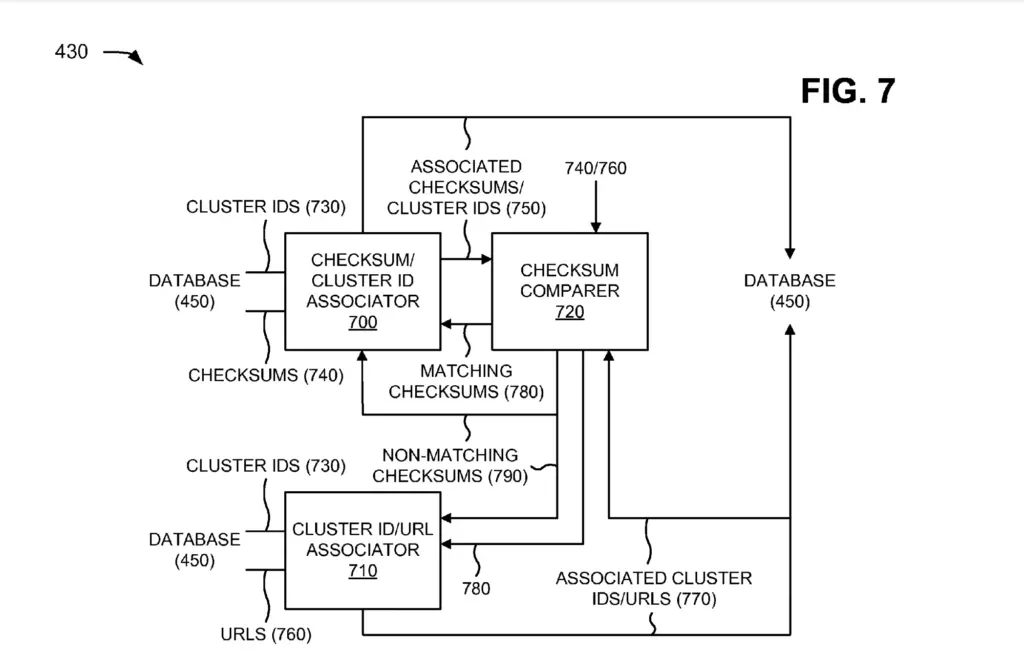
Various components are used within the crawl skew analyzer:
- Checksum ownership
- Checksum and Cluster ID Associator
- Cluster ID and URL Associator
- Checksum comparer
The checksum ownership (1) assigns a waiting period before de-duplicating documents.
The checksum/clusterId associator (2) assigns a checksum to a cluster ID, the cluster ID/URL associator (3) assigns addresses with highly-similar content checksum to a cluster ID.
Finally, the checksum comparer (4) receives a new URL and compare its content checksum with cluster checksums and requests for both associator to do their work.
1. Checksum Ownership
To understand the checksum ownership, consider an example of syndicated content showcased in the image below:
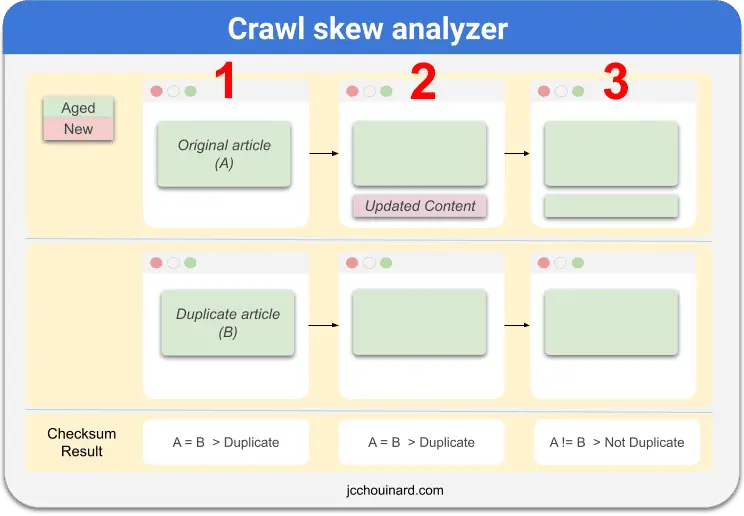
In (1), a duplicate website uses another website’s RSS feed to post all the articles from the original site. In this fashion, duplicate article (B) is created almost instantly after the original website published the original article (A). Google crawls both, applies checksum and group them in a duplicate cluster.
In(2), the original website adds content to the article, but the RSS feed is not updated. Thus the duplicate content doesn’t get updated. To overcome this issue, Google uses the document age analyzer to apply checksum only on the aged (unchanged) portion of the document and sends the updated content to the indexing system (if applicable).
After some time, in (3), the updated content ages and Google is faced with the issue that both aged content checksums are not the same anymore.
To overcome this issue, Google uses checksum ownership to enable that the aged version of the document and the duplicate to remain as duplicates for an extended period of time.
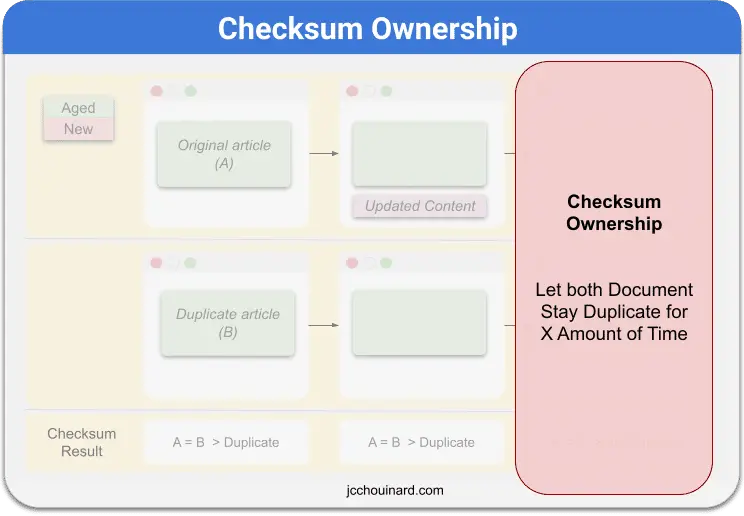
The above description is depicted in the patent by the following illustration.
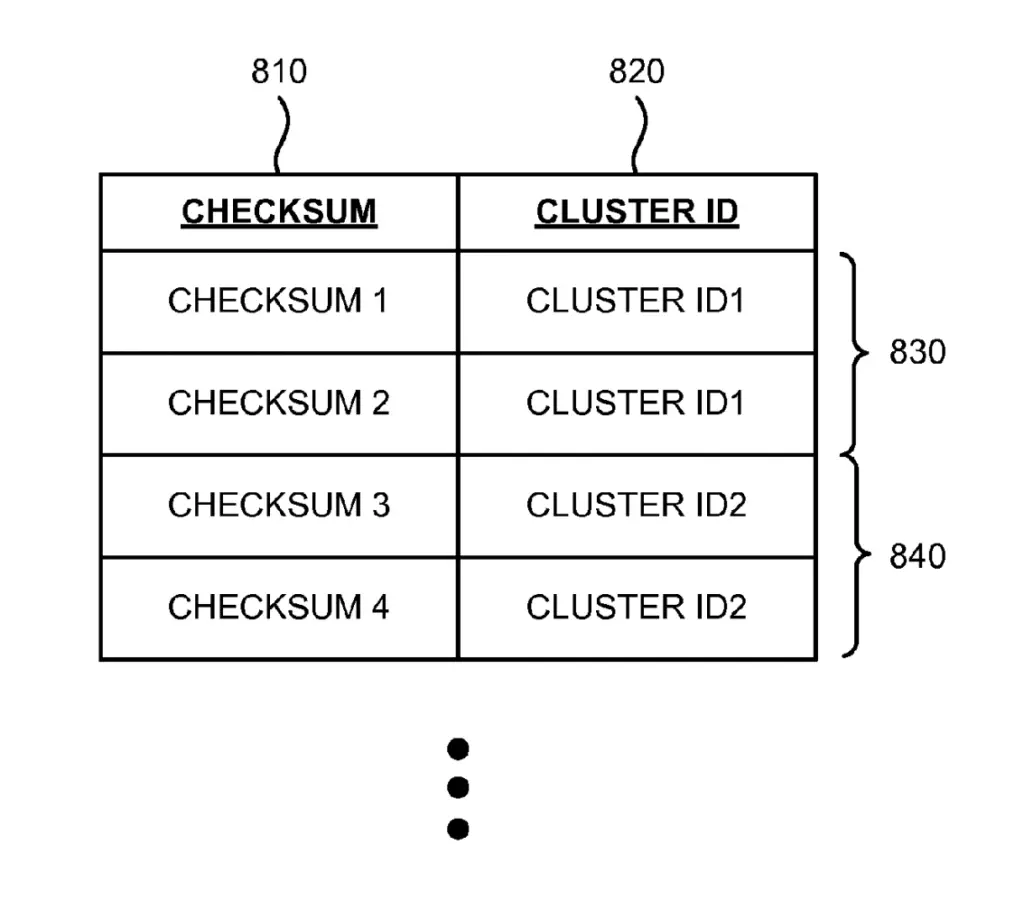
2. Checksum and Cluster ID Associator
The Checksum/Cluster ID Associator retrieves cluster ID and checksums from a database and associate each checksum to cluster IDs.
This is useful so that Cluster ID and URL Associator can match a new document’s checksum against the checksum associated with the cluster ID instead of against the checksum of each document in the cluster.
Not all documents in a cluster necessarily have the exact same checksum. The checksum associated with the cluster is the most representative of the cluster.
Cluster IDs identify one or more clusters of duplicate documents.
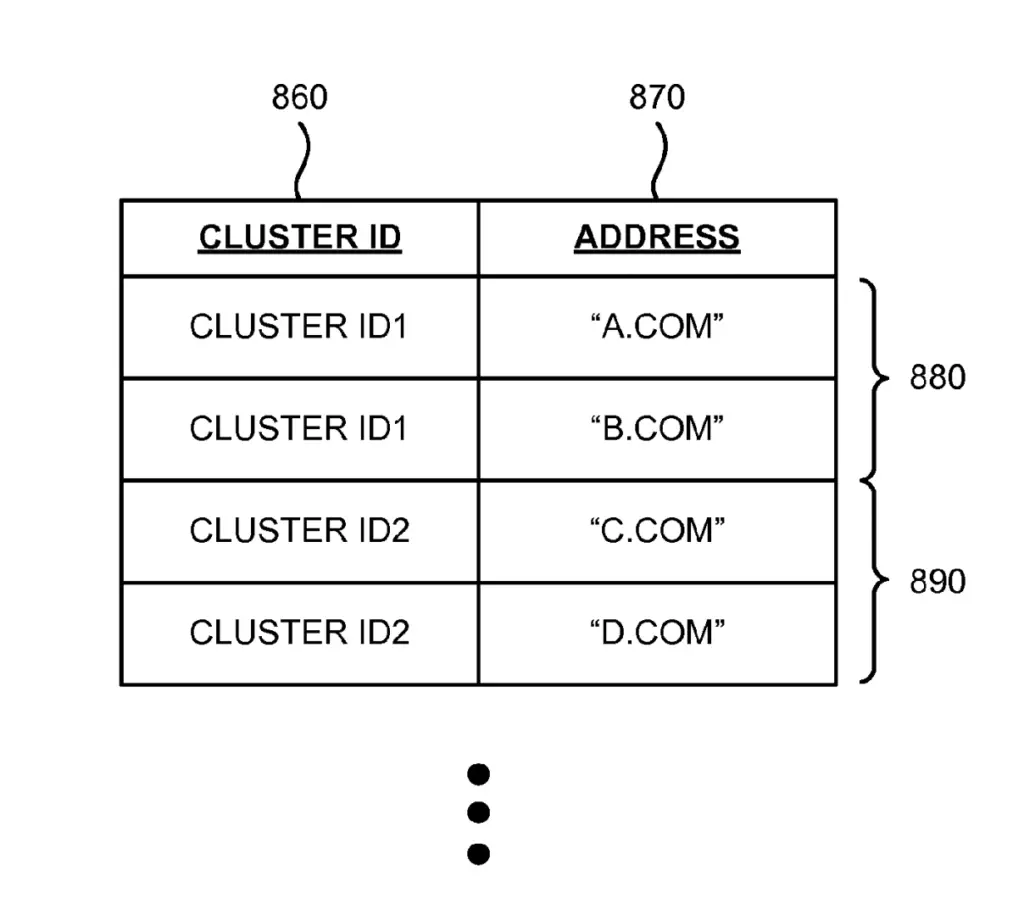
3. Cluster ID and URL Associator
The cluster ID/URL associator retrieves cluster IDs and addresses (e.g. URLs) and their checksum. It associates each cluster ID to one or more addresses when checksum substantially match the checksum associated with the cluster.
It then adds to associated values to a database and/or send them to the checksum comparer.
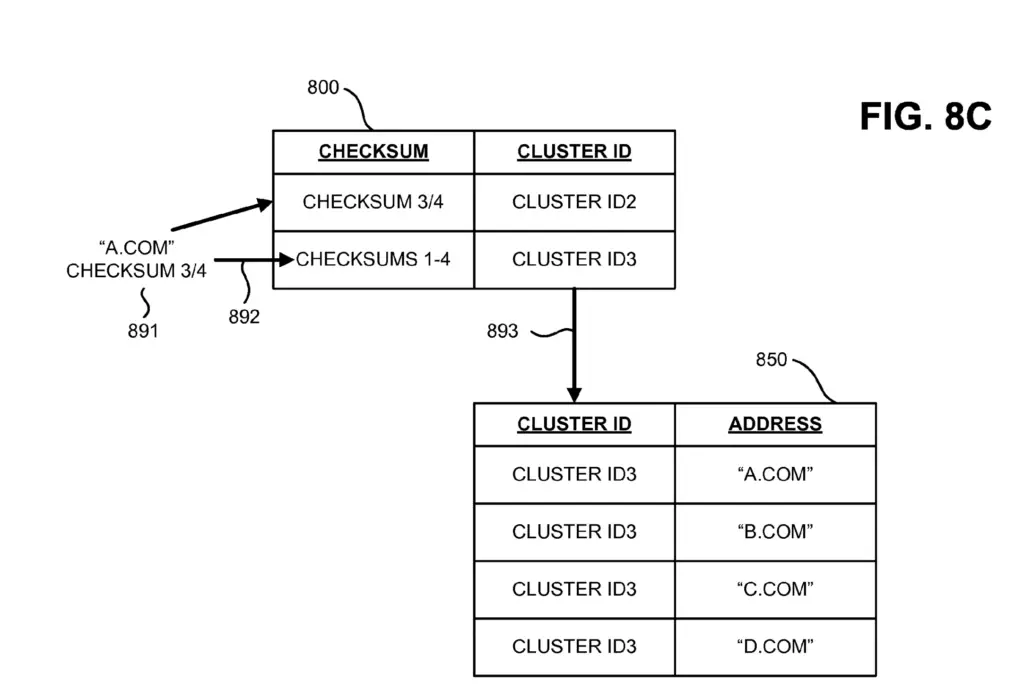
In the example below, A.COM and B.COM are duplicate of each other. C.COM and D.COM are also duplicate. Both clusters are not duplicate to each other.
What if A, B, C and D are actually duplicates where A and B were simply not updated?
Take the image below where some time has passed and the additional content from cluster ID2 was added to documents in cluster ID1 and enough time has passed so that the entire content aged.
Then both clusters became duplicate.
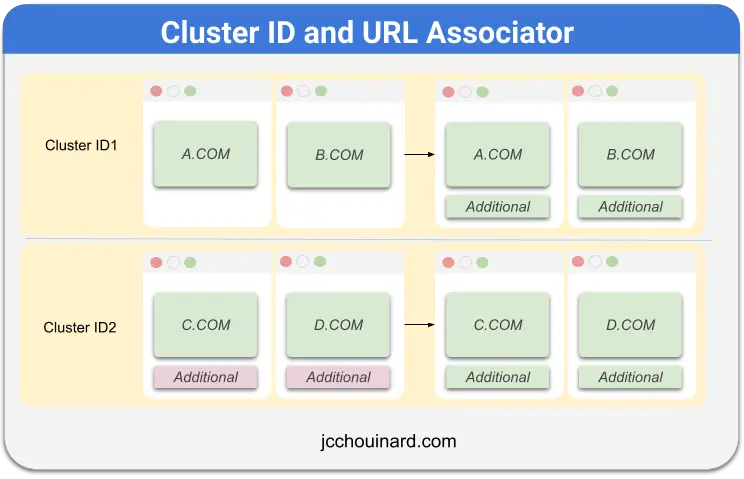
What will happen is that a new cluster will be created from merging cluster 1 and 2 and all checksums will be assumed by the cluster ID3.
4. Checksum Comparer
As its name implies, the checksum comparer compares the checksums. It may compare the checksum of two documents, or of a document against a checksum associated with a duplicate cluster.
When the checksum comparer receives a new URL, it compares its content checksum with cluster checksums.
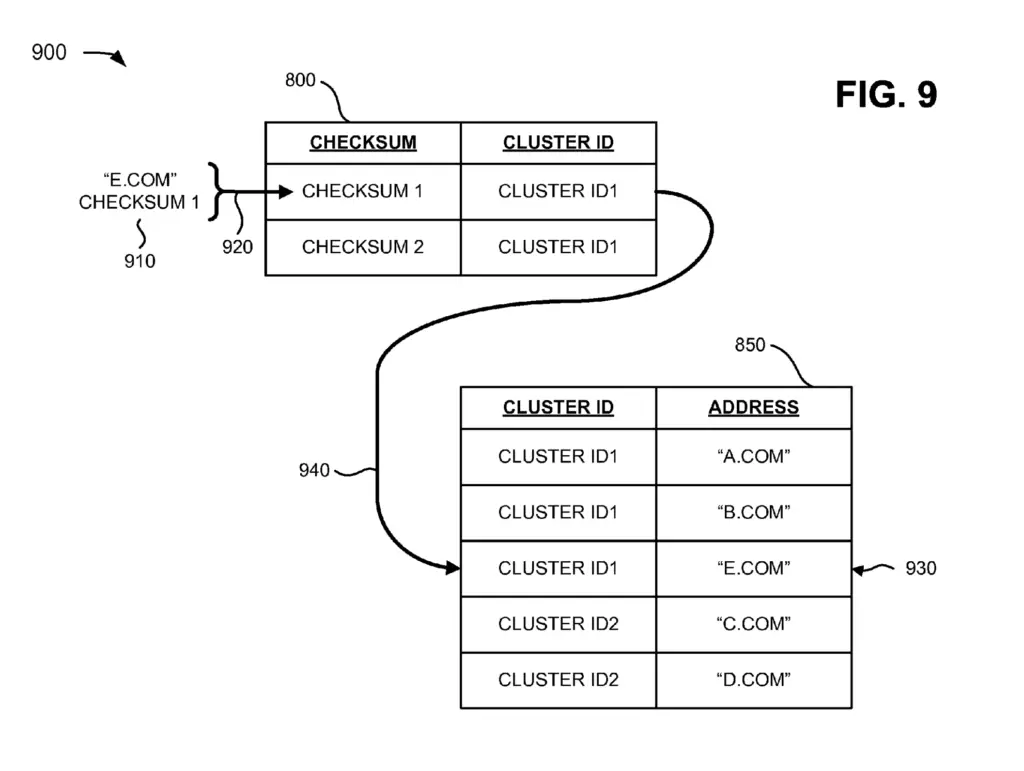
Depending if the checksum comparer can find a match or not, the associators will assign the URL and checksum to a new (no match) or to an existing (match) cluster ID.
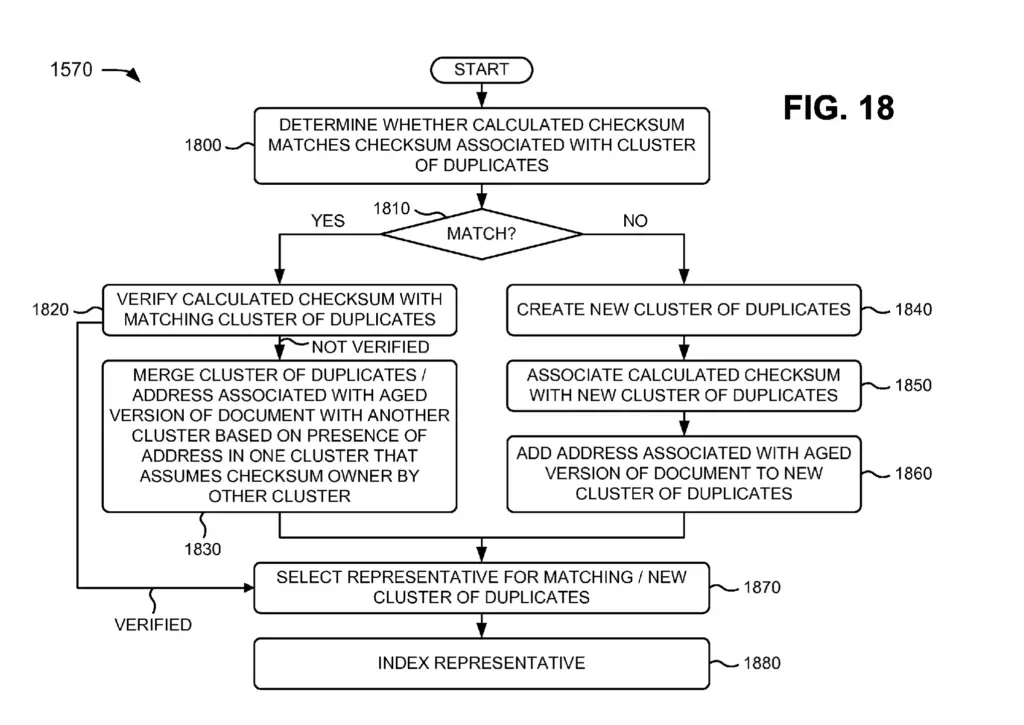
Here is the logic behind assigning new URLs to clusters and deciding which version to index.
Storing Data From the Crawler/Indexer System
While the current patent combines the crawler and the indexer system as a single entity, they could potentially be two separated entities.
In the crawler/indexer system, data is stored in a database.
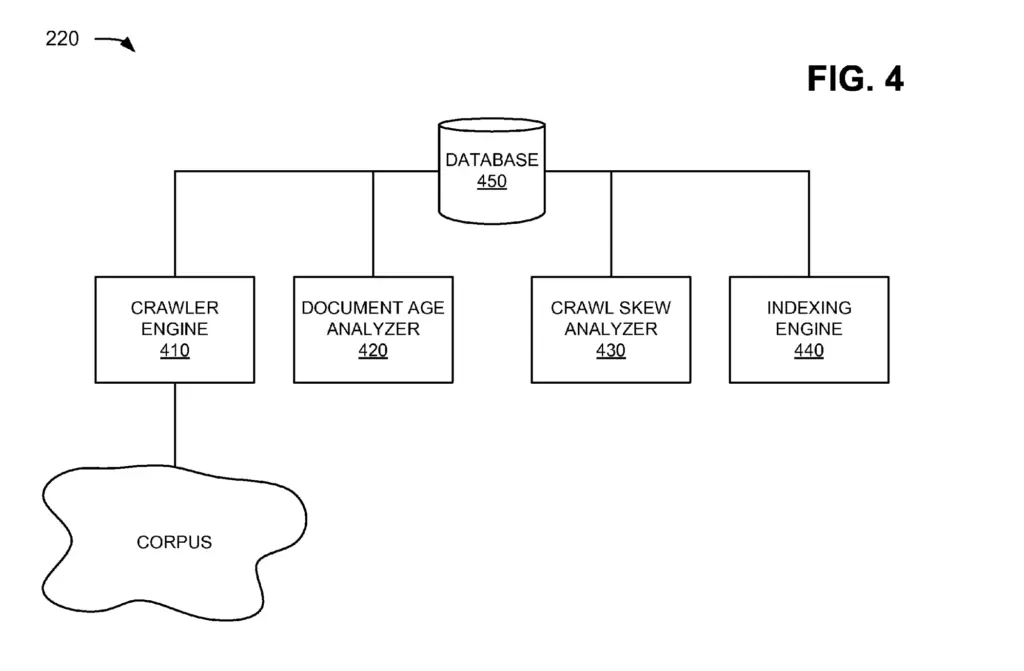
The database stores:
- List of addresses used by the crawler engine
- List of checksums compiled by document age analyzer
- List of checksums and associated duplicate cluster identifiers (IDs) compiled by crawl skew analyzer
- List of duplicate cluster IDs and associated address (e.g., URLs) compiled by crawl skew analyzer
- Index generated by indexing engine
What Categories is the Patent About?
- Indexing
- Crawling
- Duplicate content
Definitions in the Patent
| Patent term | Definition |
|---|---|
| Web crawler | Program that exploit the link-based structure of the web to browse the web in a methodical, automated manner |
| Crawl Skew | Inability of Google to compare two documents accurately because of delay between crawls |
| Document age analyzer | Analyzes prior and aged versions of a document. |
| Checksum | Hash of the content that can be used to compare similarity between documents |
| Crawl skew analyzer | Associates the aged version of the document with a cluster of duplicate documents |
| Content age assigner | Retrieves and analyzes the information associated with documents from a database |
| Aged Content Identifier | Sends new content to the indexing engine |
| Checksum calculator | Calculates checksum of aged content |
| Aged version of a document | Document retrieved from a current crawl |
| Prior versions of a document | Versions of the document retrieved from prior crawls |
| Checksum ownership | Allow duplicates to stay duplicates for some time after their aged version has diverged |
| Cluster ID | Id that identifies one or more clusters of duplicate documents |
| Cluster ID and URL Associator | Component that assign addresses to cluster IDs |
Google Search Infrastructure Involved
The “Updating search engine document index based on calculated age of changed portions in a document” patent mentions these elements from the Google Search Infrastructure:
- Crawler/Indexer System
- Crawler Engine
- Document Age Analyzer
- Content Age Assigner
- Aged Content Identifier
- Checksum Calculator
- Crawl Skew Analyzer
- Checksum and Cluster ID Associator
- Checksum comparer
- Cluster ID and URL Associator
- Indexing Engine
Updating Index Based on Aged Portions FAQ
What is the aged portion of a document?
Portion of a document that hasn’t changed between two crawls
What is this patent about?
Identifying duplicate documents even when some content change at a high frequency
How Google compares if two portions are duplicate?
Google uses checksum to compare the similarity between documents.
What SEOs Should Do About It?
Google does not use content that always changes between crawls when checking for duplication.
If you have a website heavily impacted by duplicate content (e.g. lots of Duplicate without user-selected canonical in Google Search Console indexation report), check out if most of the content changes faster than Googlebot crawls. If so, make sure that you add more stable supplementary content that could reduce the risk of duplication.
Real-World Example
A good example of this is a list page that changes a lot (e.g. a job listing page).
Let’s say you have built a job board using the highly popular Jobify theme.
All it does is show a list of jobs on the page.
You decide to programmatically create landing pages by city to mimic what major job boards are doing.
Your website now has two list pages: Barista jobs in Melbourne and Barista Jobs in Sydney, both of which simply show a list of job like in the example above.
Both pages have over 1000 jobs each, sorted by date of publication.
Every time Google comes to the page, all the jobs are new, on both pages.
Cool, all content is fresh, Google will love that, right? Not so fast.
What might happen here.
Every time Google crawls each page, Google submits the “new” list of jobs to the indexer, but only uses aged content (content that was there when they last crawled the page) to check for duplicates.

Thus, on both pages, Google only computes checksum on the filter and think that both pages are very similar, and thus put them in the same cluster of duplicates.
Patent Details
| Name | Updating search engine document index based on calculated age of changed portions in a document |
| Assignee | Google LLC |
| Granted | 2013-04-16 |
| First filed | 2011-08-15 |
| Status | Active |
| Expiration | 2029-01-30 |
| Application | 13/209,593 |
| Inventor | Joachim Kupke and Jeff Cox |
| Patent | US9536006B2 |
Other Articles on Duplication in SEO
Conclusion
We now know how Google’s Indexing System handles duplicate documents based on a content-based approach of duplicate detection.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.