In this data science tutorial, we will learn sentiment analysis using Python, BeautifulSoup and TextBlob by building a 9 am real-time report for Editors.
9 am real-time report for Editors
Years ago while working for Time Inc. later known as Meredith Corp. and now known as Dotash Meredith, I had built 9am reports for editors with Python.
The objective of this report was to let our Editors know what our competitors are writing and publishing on their homepages at 9 am every day.
An MVP for the Entertainment industry headlines:
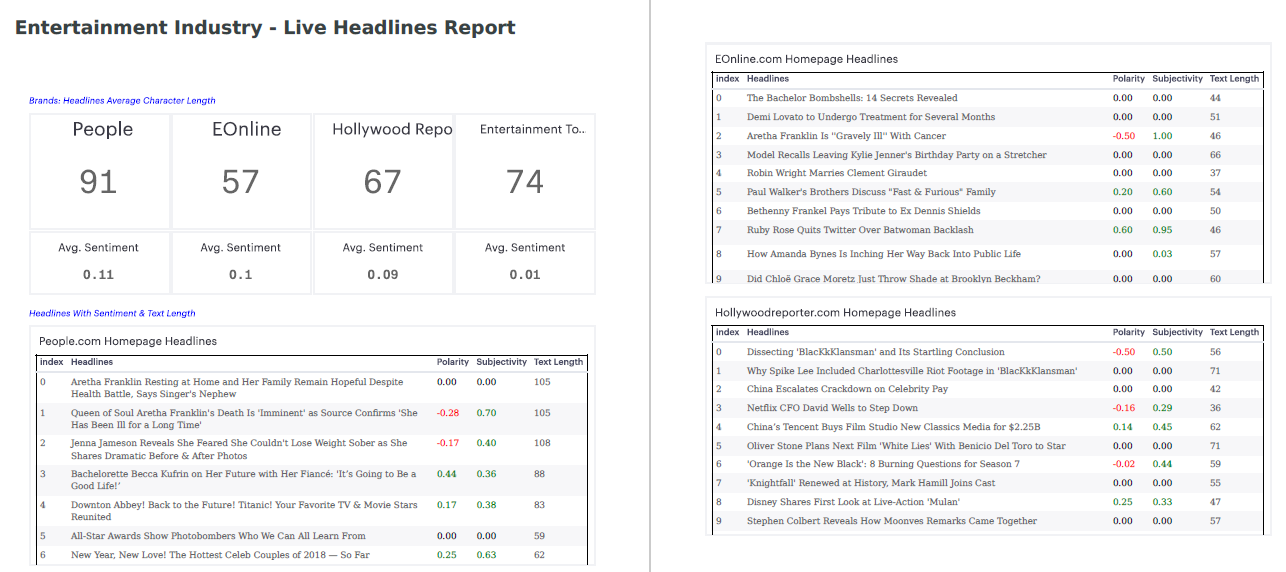
The time slot of ~9 am is one of the prime times in the entire day when people consume news.
We also wanted to show our editors in a simplistic way about the sentiment and polarity of the headlines which may influence readers to click on the story. So, if you create something on similar lines, you may ease your editor’s life and get happiness in return. 🙂
The huge media publishing house had 24+ magazines then including iconic magazines named Time, People, Fortune, Money, Sports Illustrated, Travel + Leisure, etc.
Overview
So, now to the point, with a popular STAR method:
S – Situation – How digital analytics and SEO teams can assist editors to make their lives a bit easier with informed and real-time data.
T – Task – Brainstorm, design and develop lightweight reports for Editors that are easy to consume and have industry-based real-time information.
A – Action – We were then using Mode Analytics which supports Python and R as well. We scraped titles of news featured on the homepage of our prime competitors for each vertical and applied sentiment analysis over the titles. For both scraping and sentiment analysis, we had used Python. And using Mode Analytics we automated this process which ran without any manual intervention every day.
R – Result – The editors had a good picture to understand which news or stories competitors were writing, featuring on their homepages, and what was the likeability of users clicking on the news (based on sentiment analysis). In some of the scenarios, when competitors had featured any news on their homepage and we had not, those news were also caught well.
We had targeted many brands like NY Times, Washington Post, EOnline, Entertainment Tonight, Vogue etc. based on each brand vertical’s (Entertainment, Fashion, Style, News, etc.) corresponding competitors.
The reasoning behind this reporting
On average, roughly ~3k stories were published every day on news brands but you do not see all 3k stories featured on the homepage.
Only the top / prime stories are featured on the homepage, which could be ~100 at max?
Now, we wanted to let editors know which prime stories are being covered by competitors every day at 9 am and how well or poorly have they drafted them versus our drafting?
This report also enabled a single view to understand if our editors have missed out on any story while the competitors have them covered?
Tools used to generate the competitor report
Python
For scraping, I had used the requests and the BeautifulSoup libraries, and for Sentiment analysis, I had used the Textblob library.
Install the libraries:
$ pip install requests beautifulsoup4 textblob
Automation
It was a one-time effort and Mode Analytics had this in-built automation where every 9 am the Python script ran, scraped headlines, applied sentiment analysis, and sent the report to the email recipients (editors, managers, etc.).
So, this was an MVP (minimum viable product), and if you do not have such a thing in place, you can create it on similar lines and assist in making your editors’ lives easier.
Now, with one of my favourite powerful SEO tools, ScreamingFrog, you can skip BeautifulSoup in Python and perform a Custom extraction to pull story names, and along with them, you can pull tonnes of other information and make your SEO team’s lives easier as well.
Python script for scraping and sentiment analysis used in this project
Python script for scraping the story titles.
Please note that the scraping is based on the div elements, class id etc. They are likely to break when there is a redesign of the webpage and new class id tags replace the old ones.
Libraries used: BeautifulSoup, requests, pandas
from bs4 import BeautifulSoup
import requests
import pandas as pd
# Define website to scrape
Brand = 'https://www.instyle.com/'
# Make HTTP request
page = requests.get(Brand)
# Parse the HTML
soup = BeautifulSoup(page.text, 'html.parser')
# Define empty list to store data
story_list = []
# Parse headlines CSS classes from the HTML
headline_class = 'category-page-item-image-text-wrapper linkHoverStyle'
stories = soup.find_all('span', {'class': headline_class})
# Loop through each headline class
# And append to list
for story in stories:
story = story.text.strip()
story_list.append(story)
# Remove duplicates from list
s = []
for i in story_list:
if i not in s:
s.append(i)
# Show titles
s[:5]
Output:
['Kate Hudson Hosted an "Underboob Martini Party" in a Bandeau Bra Top',
"Fans Think Pete Davidson Took Kim Kardashian's Latest Bikini Photo",
"Camila Cabello's Post-Breakup Hair Is the Ultimate Power Move",
'Dua Lipa Flashed Her Abs in a Cropped Cardigan Sweater and Matching Bra']
Below code is to apply Textblob sentiment analysis and conditional formatting. There are tons of better ways to write the code and have more advanced techniques applied. It was my Python noob time when I had written the code. Well, I’m still a Python noob for that matter 😀
from textblob import TextBlob
df = pd.DataFrame(s, columns=['Headlines'])
def sentiment_calc(text):
"""compute sentiment analysis"""
try:
return TextBlob(text).sentiment
except:
return None
# Compute polarity and subjectivity
df['sentiment_score'] = df['Headlines'].apply(sentiment_calc)
# Create dataframe from sentiment scores
sentiment_series = df['sentiment_score'].tolist()
columns = ['Polarity', 'Subjectivity']
pf = pd.DataFrame(sentiment_series, columns=columns, index=df.index)
# Concatenate the headlines and sentiment scores
df1 = pd.concat([df, pf], axis=1)
df1 = df1.drop('sentiment_score', axis=1)
df1.head()
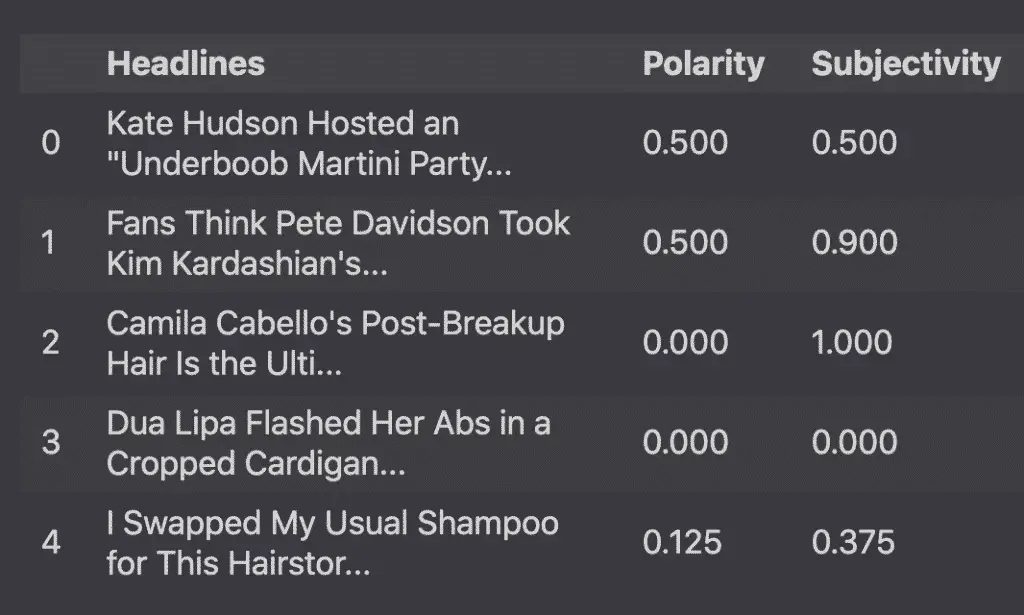
Finally, the code below is used to style the dataframe.
# Make styled dataframe
def color_negative_red(value):
if value < 0:
color = 'red'
elif value > 0:
color = 'green'
else:
color = 'black'
return 'color: %s' % color
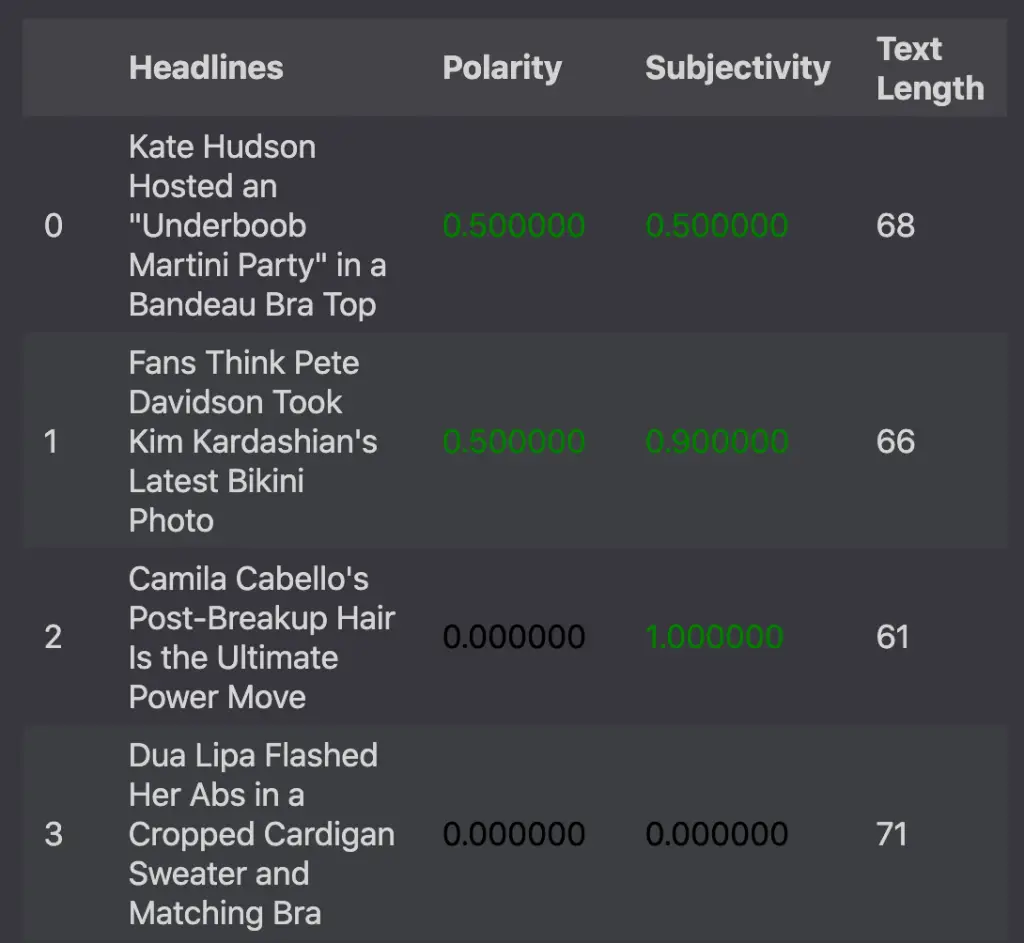
df1['Text Length'] = df1['Headlines'].apply(len)
df1.style.applymap(color_negative_red, subset=['Polarity', 'Subjectivity'])

Currently, SEO Specialist at SEEK Asia. An SEO and Digital Analytics enthusiast. More than 10 years of experience across various industries and geographies. Always a learner and seeking to contribute.