
In this tutorial, you will learn how to extract all pages from a specific website from Commoncrawl with Python.
You will find the full code on my Github account.
What is Commoncrawl?
Commoncrawl is an open repository of web crawl data. It allows you to see the extracted HTML from history of crawls for specific websites or web pages. This is a database that was commonly used when training Large Language Models (LLM) like ChatGPT.
Why Use Commoncrawl?
AS Commoncrawl contains historical data about a large amount of web pages, it is often used to replace the need for handling web scraping. The Commoncrawl database can be used for things like:
- competitive analysis,
- viewing history for a web page,
- training of machine learning models.
In our case, we will use it to extract a website’s HTML pages instead of scraping it ourselves, with all the problems it causes (e.g. being blocked, paying for proxies, etc.)
It is good practice to use the Commoncrawl before scraping a website as it can reduce both the financial cost for the scraper and the scraped website as well as the cost on the environment of running a web crawler for content that is already stored somewhere.
Install Required Libraries
First you will need to install the following libraries (requests, urllib3, warcio and pandas). In the Terminal, type this command to install all the libraries (remove any that you already have installed):
pip3 install requests urllib3 warcio pandas beautifulsoup4Import Libraries
import requests
import json
import os
import pandas as pd
# For parsing URLs:
from urllib.parse import quote_plus
Set Your Python Variables and Functions
The variables that you will need to set are the target_url and the indexes that you want to get the data from. The indexes relates to the point in time when it was crawled and the full list can be found in the official documentation, or from this text file (extracted when this post was first published).
def search_cc_index(url, index_name):
"""
Search the Common Crawl Index for a given URL.
This function queries the Common Crawl Index API to find records related to the specified URL.
It uses the index specified by `index_name` to retrieve the data and returns a list of JSON objects,
each representing a record from the index.
Arguments:
url (str): The URL to search for in the Common Crawl Index.
index_name (str): The name of the Common Crawl Index to search (e.g., "CC-MAIN-2024-10").
Returns:
list: A list of JSON objects representing records found in the Common Crawl Index.
Returns None if the request fails or no records are found.
Example:
>>> search_cc_index("example.com", "CC-MAIN-2024-10")
[{...}, {...}, ...]
"""
encoded_url = quote_plus(url)
index_url = f'http://index.commoncrawl.org/{index_name}-index?url={encoded_url}&output=json'
response = requests.get(index_url)
if response.status_code == 200:
records = response.text.strip().split('\n')
return [json.loads(record) for record in records]
else:
return None
def fetch_single_record(warc_record_filename, offset, length):
"""
Fetch a single WARC record from Common Crawl.
Arguments:
record {dict} -- A dictionary containing the WARC record details.
Returns:
bytes or None -- The raw content of the response if found, otherwise None.
"""
s3_url = f'https://data.commoncrawl.org/{warc_record_filename}'
# Define the byte range for the request
byte_range = f'bytes={offset}-{offset + length - 1}'
# Send the HTTP GET request to the S3 URL with the specified byte range
response = requests.get(
s3_url,
headers={'Range': byte_range},
stream=True
)
if response.status_code == 206:
# Use `stream=True` in the call to `requests.get()` to get a raw byte stream,
# because it's gzip compressed data
stream = ArchiveIterator(response.raw)
for warc_record in stream:
if warc_record.rec_type == 'response':
return warc_record.content_stream().read()
else:
print(f"Failed to fetch data: {response.status_code}")
return None
def append_df_row_to_pickle(row, pickle_file):
"""
Append a row to a DataFrame stored in a pickle file.
Arguments:
row {pd.Series} -- The row to be appended to the DataFrame.
pickle_file {str} -- The path to the pickle file where the DataFrame is stored.
"""
# Check if the pickle file exists
if os.path.exists(pickle_file):
# Load the existing DataFrame from the pickle file
df = pd.read_pickle(pickle_file)
else:
# If the file doesn't exist, create a new DataFrame
df = pd.DataFrame(columns=row.index)
# Append the new row to the DataFrame
df = pd.concat([df, pd.DataFrame([row])], ignore_index=True)
# Save the updated DataFrame back to the pickle file
df.to_pickle(pickle_file)
def load_processed_indices(pickle_file):
"""
Load processed indices from a pickle file to check previously processed records.
Arguments:
pickle_file {str} -- The path to the pickle file where the DataFrame is stored.
Returns:
Set of processed indices.
"""
if os.path.exists(pickle_file):
df = pd.read_pickle(pickle_file)
# Assuming 'index' column is in the DataFrame and contains indices of processed records
processed_indices = set(df['index'].unique())
print(f"Loaded {len(processed_indices)} processed indices from {pickle_file}")
return processed_indices
else:
print(f"No processed indices found. Pickle file '{pickle_file}' does not exist.")
return set()
Fetch All the Pages from the Commoncrawl Index
The first step in fetching HTML from the Commoncrawl is to search through the index to find where the data that you want is stored. We will do so by using the search_cc_index(target_url, index_name) function.
# The URL you want to look up in the Common Crawl index
target_url = 'indeed.com/.*' # Replace with your target URL
# list of indexes https://commoncrawl.org/get-started
indexes = ['CC-MAIN-2024-33','CC-MAIN-2024-30','CC-MAIN-2024-26']
record_dfs = []
# Fetch each index and store into a dataframe
for index_name in indexes:
print('Running: ', index_name)
records = search_cc_index(target_url,index_name)
record_df = pd.DataFrame(records)
record_df['index_name'] = index_name
record_dfs.append(record_df)
# Combine individual dataframes
all_records_df = pd.concat(record_dfs)
all_records_df = all_records_df.sort_values(by='index_name', ascending=False)
all_records_df = all_records_df.reset_index()
# Create columns where to store data later
all_records_df['success_status'] = 'not processed'
all_records_df['html'] = ''
Now, it would be good to keep a copy of the data in case you break something.
all_records_df.to_csv('all_records_df.csv', index=False)
Then we will process the DataFrame to reduce to only what we are interested in.
Here, I filter to keep only English language job posting pages that have the /job/ string in the URL.
# Select english pages
df = all_records_df[all_records_df['languages'] == 'eng']
# Select oonly URLs that contain a certain string
df = df[df['url'].str.contains('/job/')]
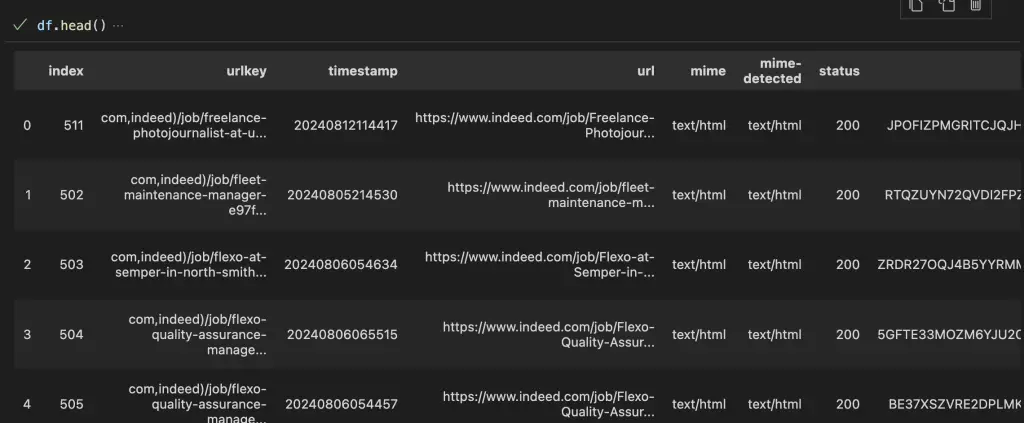
df.head()
You will get a DataFrame with all the data that you need get the content for each web page.
Download the HTML for Each Page
To download the HTML for each Web Page, you will need to get the warc record filename URL that is in this format.
https://data.commoncrawl.org/crawl-data/CC-MAIN-2024-33/segments/1722641036895.73/warc/CC-MAIN-20240812092946-20240812122946-00210.warc.gzYou will find the path of this URL in the filename column of the dataframe. To parse it, you will also need the value from the offset and length columns.
The important function here is the fetch_single_record(warc_record_filename, offset, length) where the warc_record_filename is the value in the filename column.
This is a very lengthy process that may have multiple errors (e.g. Multiple warc files will return ArchiveLoadFailed issue, the only solution that I found was to try to fetch it and discard it when there is an error). This is why it is important to limit your extraction to only the type of pages that you need.
Safeguards
Since it is such a lengthy process, it is good to have safeguards in case your script breaks. This is why I am storing the data in a pickle file (see python pickle tutorial) as we go.
I am also using a bunch of variables for printing progress to have a sense of how long it will take to get all the content.
# If pickle file exists, check for processed items
pickle_file = 'commcrawl_indeed.pkl'
processed_indices = load_processed_indices(pickle_file)
if processed_indices:
# Remove processed items
df = df[~df['index'].isin(processed_indices)]
# Create storage for later
successful = set()
results = {}
# Keep track of each row processed
i = 0
perc = 0
n_records = len(df)
print(f"Found {n_records} records for {target_url}")
mod = int(n_records * 0.01)
Run the Extraction
We can now extract all the data by looping each row and fetching each record.
To speed up the process, we will only fetch one version of the HTML page (not its history). So if we already have found the HTML in the latest extraction of the commoncrawl, we will skip earlier versions for that URL.
# Reset index to help with looping
df.reset_index(drop=True,inplace=True)
for i in range(len(df)):
# Print every 1% process
if i % mod == 0:
print(f'{i} of {n_records}: {perc}%')
perc += 1
record_url = df.loc[i, 'url']
# Fetch only URLs that were not processed
# If it was already processed, skip URL
# (Helps speeding if you only need one version of the HTML, not its history)
if not record_url in successful:
length = int(df.loc[i, 'length'])
offset = int(df.loc[i, 'offset'])
warc_record_filename = df.loc[i, 'filename']
result = fetch_single_record(warc_record_filename, offset, length)
if not result:
df.loc[i,'success_status'] = 'invalid warc'
else:
df.loc[i,'success_status'] = 'success'
df.loc[i,'html'] = result
else:
df.loc[i,'success_status'] = 'previously processed'
# Add to pickle file
append_df_row_to_pickle(df.loc[i, :], pickle_file)
Read the Data From Commoncrawl Extraction
Now that you have extracted everything, you can read the data by using read_pickle() from pandas.
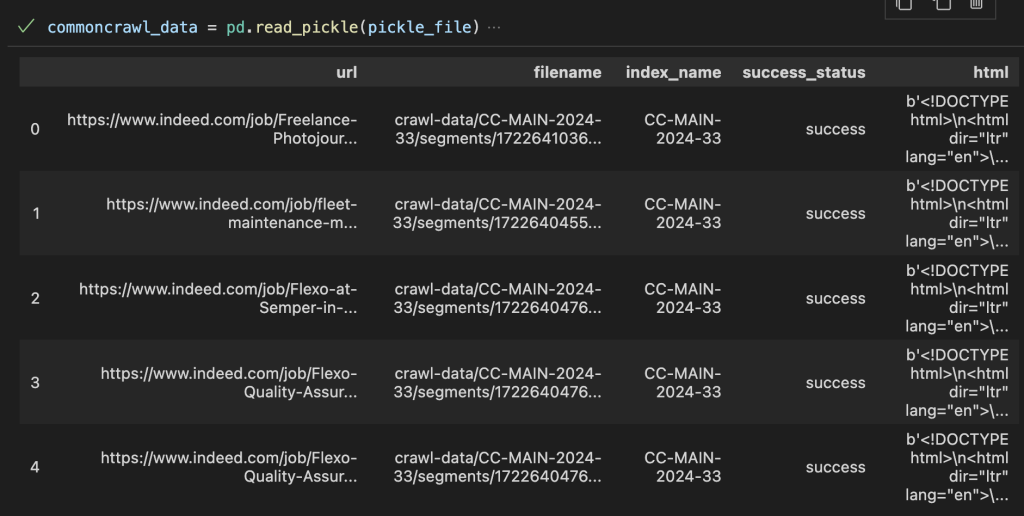
commoncrawl_data = pd.read_pickle(pickle_file)
commoncrawl_data[
['url','filename','index_name','success_status','html']
].head()
Here, you can get all the data into a DataFrame.
Parse the HTML from Commoncrawl
Now that you have the data, you may want to parse the HTML file. You can do so using BeautifulSoup in Python.
from bs4 import BeautifulSoup
# Select HTML from row 0
content = commoncrawl_data.loc[0, 'html']
# Parse in Beautiful soup
soup = BeautifulSoup(content, 'html.parser')
print(soup.find('title'))
<title>FREELANCE PHOTOJOURNALIST - San Francisco, CA 94105 - Indeed.com</title>How to Run Commoncrawl with Multiple Threads
In order to run commoncrawl in multiple threads, you will have to wrap the function using the threading module.
import threading
n_threads = 3
threads = []
for i in range(n_threads):
pickle_file = f'data/commcrawl_expedia_hotel_information_th{i}.pkl'
thread_df = df[df.index % n_threads == i]
try:
t = threading.Thread(
target=cc_records_to_pkl,
args=[thread_df, pickle_file])
t.start()
except:
pass
threads.append(t)
for thread in threads:
thread.join()
That being said, you will face some issues with the pickling of files when running on separate threads. You will handle that by creating temporary checkpoints for your pickle files and then store the data into the main files. All the details are in this code that I added on Github.
This is it, you now can scrape any web page available in commoncrawl with Python

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.