Creating a dummy dataset in Python is often useful to test functions without searching for a real dataset.
Here are a few ways to generate fake data in Python for testing purposes.
Create DataFrame
from pandas.util.testing import makeDataFrame
df = makeDataFrame()
or
import pandas as pd
s = pd.Series(list('abca'))
pd.get_dummies(s)
Create a List of Dictionaries
from random import randint
num_list = 5
num_keys = 3
list_of_dicts = []
for i in range(num_list):
d = {}
for j in range(1,num_keys+1):
d[chr(j+96)]=randint(1,10)
list_of_dicts.append(d)
list_of_dicts
[{'a': 3, 'b': 8, 'c': 4},
{'a': 9, 'b': 4, 'c': 2},
{'a': 9, 'b': 10, 'c': 6},
{'a': 6, 'b': 4, 'c': 1},
{'a': 3, 'b': 8, 'c': 3}]
Create a Dictionary of Lists
from random import randint
num_keys = 5
letters = []
for i in range(1,num_keys+1):
letters.append(chr(i+96))
dict_of_lists = {key: list(range(randint(5,10))) for key in letters}
dict_of_lists
{'a': [0, 1, 2, 3, 4, 5, 6, 7],
'b': [0, 1, 2, 3, 4, 5, 6],
'c': [0, 1, 2, 3, 4, 5],
'd': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
'e': [0, 1, 2, 3, 4, 5, 6]}
Create DataFrame from Lists
You can create a pandas DataFrame using lists.
def make_df_from_lists(index,**kwargs):
return pd.DataFrame(list(zip(*kwargs.values())),index=index,columns=list(kwargs.keys()))
index = ['United States', 'Germany', 'Great Britain', 'Russia', 'China', 'France', 'Australia', 'Italy', 'Canada', 'Japan']
gold = [137, 47, 64, 50, 44, 20, 23, 8, 4, 17]
silver = [52, 43, 55, 28, 30, 55, 34, 38, 4, 13]
bronze = [67, 67, 26, 35, 35, 21, 25, 24, 61, 34]
make_df_from_lists(index,Bronze=bronze,Gold=gold,Silver=silver)
Create List of DataFrames
cols,dfs,i,s = ['date','values'], [], 1, 3
for date in ['2022-01-01', '2022-01-02']:
data = list(zip([date]*s,list(range(i,i+s))))
dfs.append(pd.DataFrame(data,columns=cols))
i+=s
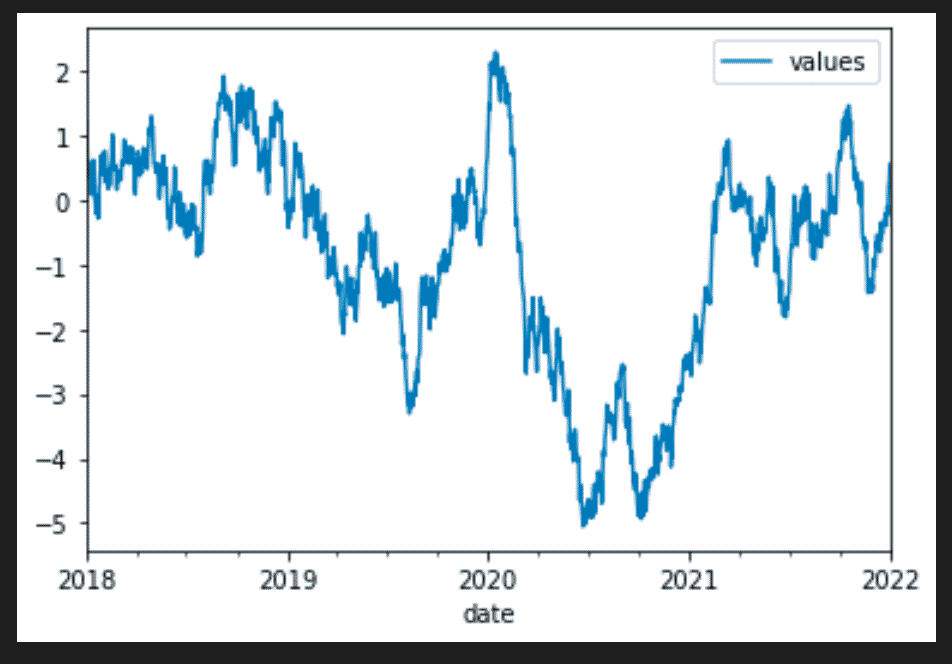
Generate Dummy Time Series
import random
import pandas as pd
def random_timeseries(initial_value: float, volatility: float, count: int) -> list:
time_series = [initial_value, ]
for _ in range(count):
time_series.append(time_series[-1] + initial_value * random.gauss(0, 1) * volatility)
return time_series
ts = pd.date_range(start='2018-01-01', end='2022-01-01', freq='D')
ts = pd.DataFrame(ts, columns=['date'])
ts['values'] = random_timeseries(1.2, 0.15, len(ts)-1)
ts.set_index('date').plot()
This is it, you now know how to generate dummy data from scratch in Python.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.