
The documentation on the Reddit API JSON is very confusing to non-developers.
I wrote this guide to help you make sense of Reddit’s API JSON response.
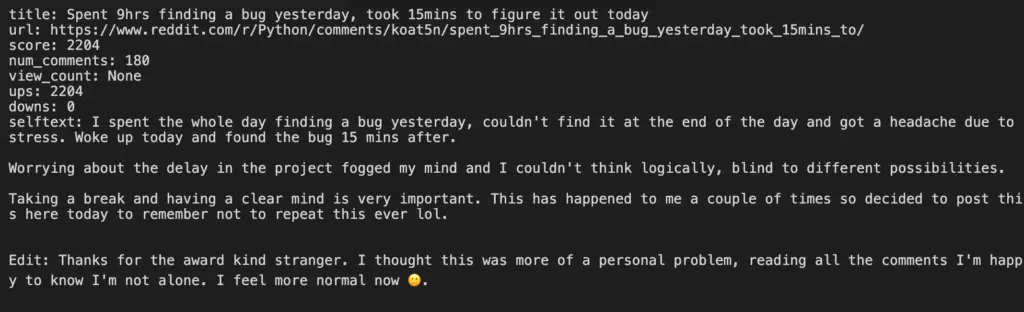
We will also parse the response to show interesting data like this:
The guide is in Python, so if you don’t know how to use python, you can read my complete guide on Python for SEO, or just follow the steps with your favourite tool.
View Reddit API’s JSON Response
The Reddit API’s JSON response represents the format in which the Reddit API returns the data coming from their product.
The simplest way to view the JSON response from the Reddit API is to open the API URL in your browser and simply view the JSON response.
https://www.reddit.com/r/python/top.json?limit=100&t=month
An API, or application programming interface, gives you access to their data through structured data, in this case, JSON.
Parsing Reddit API’s JSON file
There are 2 main ways to parse the JSON file returned from the Reddit API, using a JSON parser or using your favourite programming language.
The simplest way to parse any JSON file is to use an online JSON parser. Here, you can copy and paste the response from the Reddit API endpoint into a free online JSON parser and parse the JSON object into its individual components.
LAter we will learn how to parse the JSON response with Python.
Where is the Subreddit’s Data in the JSON file?
All the Subreddit’s data from the Reddit API JSON response is nested inside the ‘children’ object of the ‘data’.
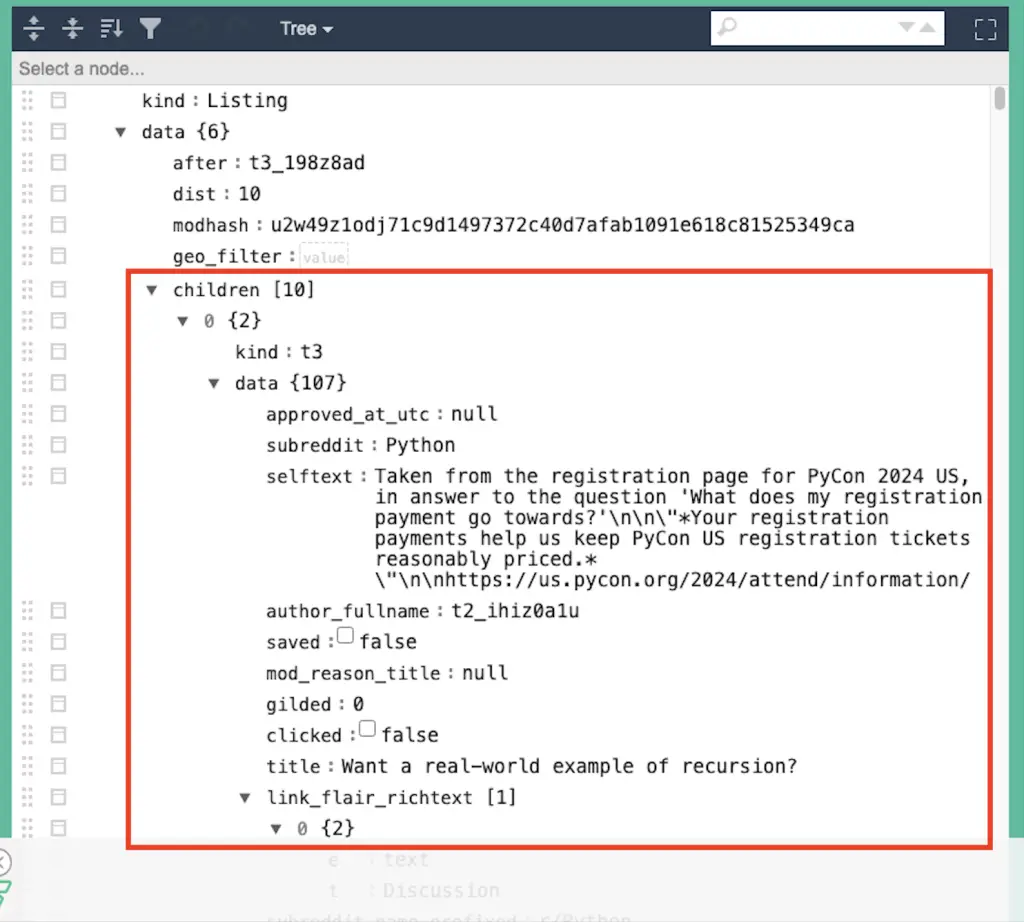
Now that we have a general sense of the structure of the Reddit API JSON file, will learn how to process the API using Python.
How to use Python Requests to get the API’s JSON
With Python, we can use the requests library to perform an HTTP request to the API endpoint and extract the JSON data from the Reddit API. Here, we will fetch the top 100 posts of the month in the r/python subreddit.
The Reddit API limit is 100. If you want to get more rows of data, you will have to make multiple requests.
If you don’t know how to do that, just read my post on using Reddit API without credentials.
Fetching Reddit API with Python
import requests
subreddit = 'python'
limit = 100
timeframe = 'month' #hour, day, week, month, year, all
listing = 'top' # controversial, best, hot, new, random, rising, top
def get_reddit(subreddit,listing,limit,timeframe):
try:
base_url = f'https://www.reddit.com/r/{subreddit}/{listing}.json?limit={limit}&t={timeframe}'
request = requests.get(base_url, headers = {'User-agent': 'yourbot'})
except:
print('An Error Occured')
return request.json()
r = get_reddit(subreddit,listing,limit,timeframe)
Overview of the JSON
By looking at the response r, you get a file that has that kind of structure.
{
"kind": "string",
"data": {
"modhash": "string",
"dist": int,
"children": [{
"kind": "string",
"data": {
"approved_at_utc":"string",
"subreddit": "string",
"selftext": "string"
...,
"is_video":"boolean"
}],
"after":"",
"before:""
}
}
Basically, as we will see details of it later, all the data is under r['data']['children'][i]['data']. With i being the number for the position of the post that you want to select (from 0 to 99 in our case).
You can inside the dig object by object by looking at the keys of the dictionary.
print(r.keys())
# dict_keys(['kind', 'data'])
How to Access Subreddit’s API Data in With Python
To access the data returned from the subreddit’s API call, we simply need to select the nested ‘children’ element that is nested inside the ‘data’ object of Reddit API’s response object.
r['data']['children']
As you see we have a 100 posts in JSON object.
len(r['data']['children'])
# 100
What can you Extract From a Post on Reddit?
Now, we need to select the first post of the 100 posts using r['data']['children'][0].
print(r['data']['children'][0].keys())
# dict_keys(['kind', 'data'])
List of the Reddit’s JSON Keys
To access a JSON object within JSON array in python, you need to select the ‘data’ from ‘children’ object: r‘data’0.
Furthermore, we will look at the keys of that dictionary to look at what we can extract.
for k in r['data']['children'][0]['data'].keys():
print(k)
approved_at_utc
subreddit
selftext
author_fullname
saved
mod_reason_title
gilded
clicked
title
link_flair_richtext
subreddit_name_prefixed
hidden
pwls
link_flair_css_class
downs
thumbnail_height
top_awarded_type
hide_score
name
quarantine
link_flair_text_color
upvote_ratio
author_flair_background_color
subreddit_type
ups
total_awards_received
media_embed
thumbnail_width
author_flair_template_id
is_original_content
user_reports
secure_media
is_reddit_media_domain
is_meta
category
secure_media_embed
link_flair_text
can_mod_post
score
approved_by
author_premium
thumbnail
edited
author_flair_css_class
author_flair_richtext
gildings
content_categories
is_self
mod_note
created
link_flair_type
wls
removed_by_category
banned_by
author_flair_type
domain
allow_live_comments
selftext_html
likes
suggested_sort
banned_at_utc
view_count
archived
no_follow
is_crosspostable
pinned
over_18
all_awardings
awarders
media_only
link_flair_template_id
can_gild
spoiler
locked
author_flair_text
treatment_tags
visited
removed_by
num_reports
distinguished
subreddit_id
mod_reason_by
removal_reason
link_flair_background_color
id
is_robot_indexable
report_reasons
author
discussion_type
num_comments
send_replies
whitelist_status
contest_mode
mod_reports
author_patreon_flair
author_flair_text_color
permalink
parent_whitelist_status
stickied
url
subreddit_subscribers
created_utc
num_crossposts
media
is_video
Extract Interesting Data from Reddit
Last, all you have to do is select what you want from the list.
to_extract = ['title','url','score','num_comments','view_count','ups','downs','selftext']
for e in to_extract:
print(f"{e}: {r['data']['children'][0]['data'][e]}")
title: Spent 9hrs finding a bug yesterday, took 15mins to figure it out today
url: https://www.reddit.com/r/Python/comments/koat5n/spent_9hrs_finding_a_bug_yesterday_took_15mins_to/
score: 2204
num_comments: 180
view_count: None
ups: 2204
downs: 0
selftext: I spent the whole day finding a bug yesterday, couldn't find it at the end of the day and got a headache due to stress. Woke up today and found the bug 15 mins after.
Worrying about the delay in the project fogged my mind and I couldn't think logically, blind to different possibilities.
Taking a break and having a clear mind is very important. This has happened to me a couple of times so decided to post this here today to remember not to repeat this ever lol.
Edit: Thanks for the award kind stranger. I thought this was more of a personal problem, reading all the comments I'm happy to know I'm not alone. I feel more normal now ?.
Understand the Other Objects of the Reddit’s JSON
We now have covered the most important aspect of the Reddit JSON.
Let’s look at the other objects.
- Response’s Kinds
- Other objects inside the data
Reddit Response’s Kind
Kind returns a string that tells the type of the object. You will not find any “data” in that key.
print(r['kind'])
# Listing
In that case, ‘Listing’ represents a list of things. ‘Listing’ is used to paginate results when they are too long to display all at once.
If we look at the actual post ‘kind’, you will see a different string identifier.
r['data']['children'][0]['kind']
# 't3'
Here are the meanings of the other list identifiers.
- t1: Comment
- t2: Account
- t3: Link
- t4: Message
- t5: Subreddit
- t6: Award
Other Objects Inside the Data
Inside the data, we had 5 elements: modhash, dist, children, after, before.
r['data'].keys()
# dict_keys(['modhash', 'dist', 'children', 'after', 'before'])
We have already covered the ‘children‘ element, let’s look at the others.
print(f"Modhash: {r['data']['modhash']}")
print(f"dist: {r['data']['dist']}")
print(f"after: {r['data']['after']}")
print(f"before: {r['data']['before']}")
# Modhash:
# dist: 100
# after: t3_kkwabd
# before: None
- Modhash: The
modhashis to prevent CSRF, but since we did not log-in to make that request, we did not setmodhash. - Dist: Is the number of items that you extracted
- After: Name of the listing that follows after this page. None if no page after (i.e. you extracted the last result).
- Before: Name of the listing that comes before this page
Conclusion
There it is. Hopefully, Reddit’s API JSON response makes a little more sense for you. If you want to dive deeper, you can always go to the dev documentation or to this outdated repository on the subject.

SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.